毕业设计网站开发的中期报告小礼品网络定制
目录
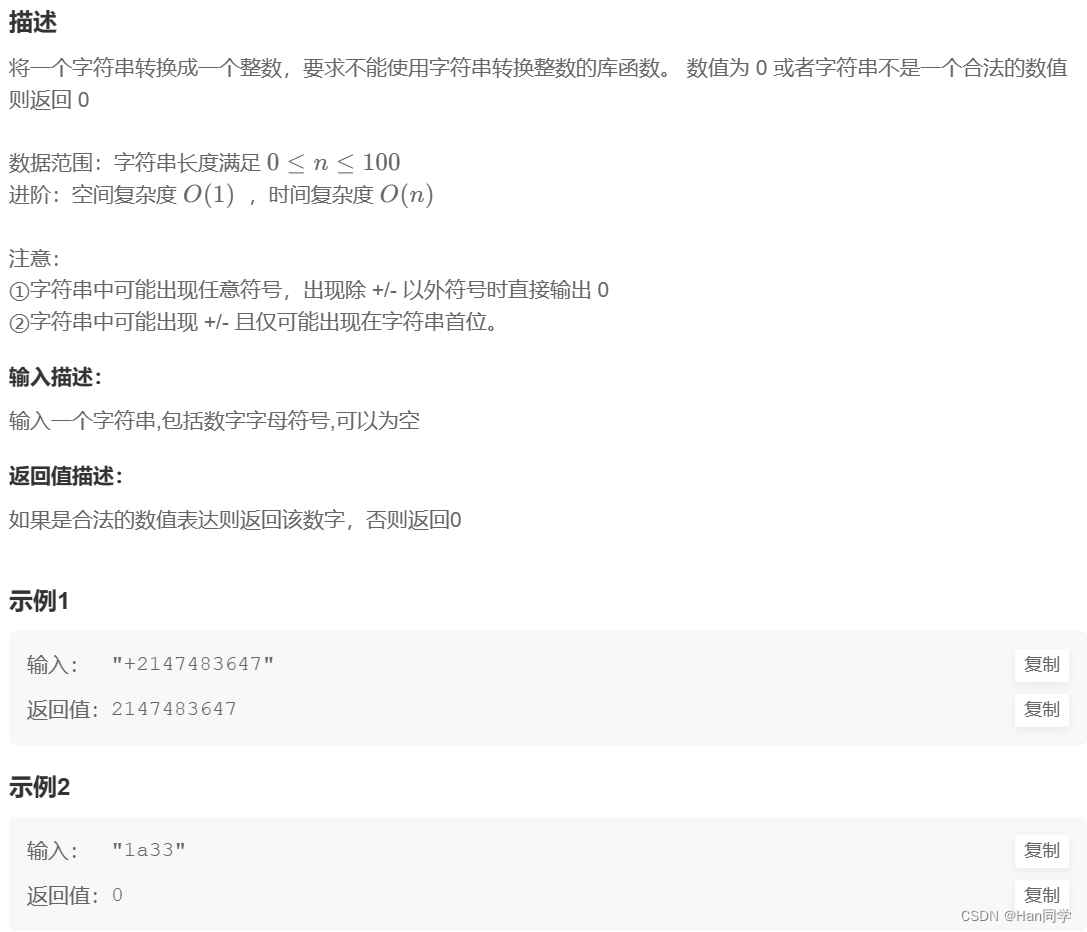
把字符串转换成整数
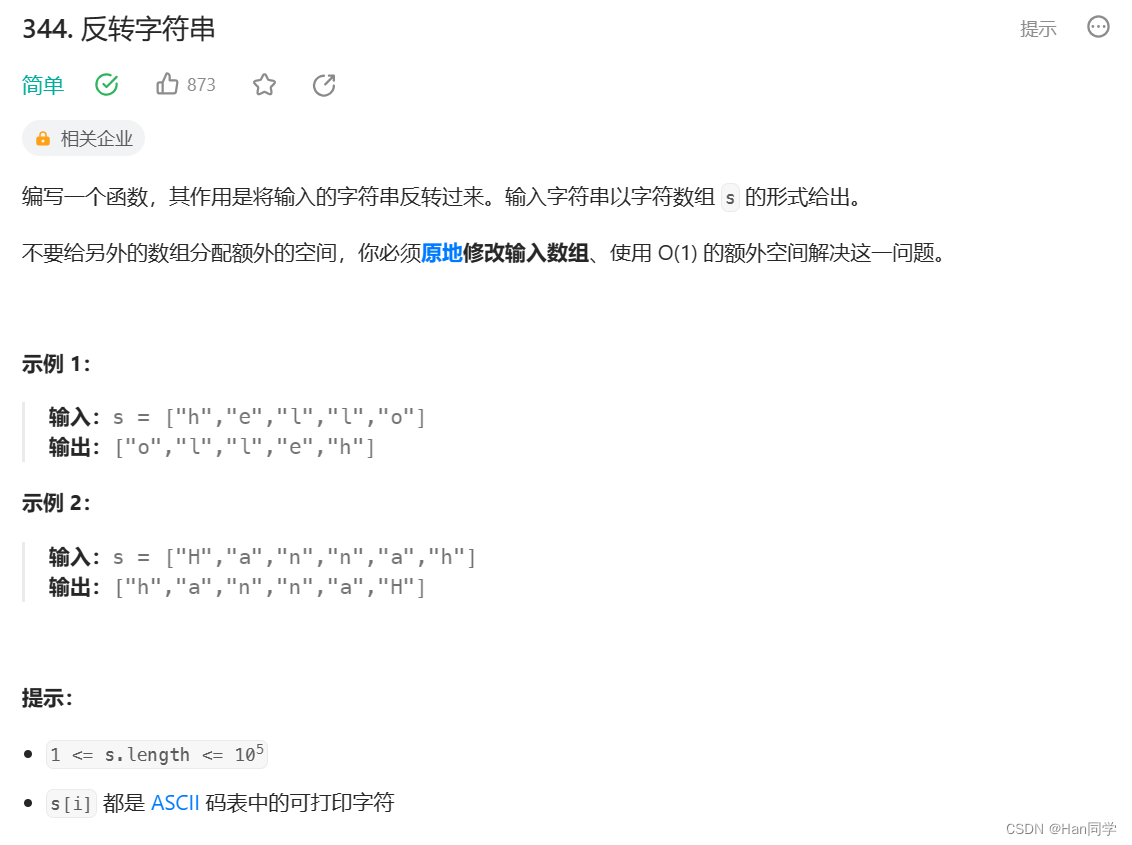
反转字符串
字符串中的第一个唯一字符
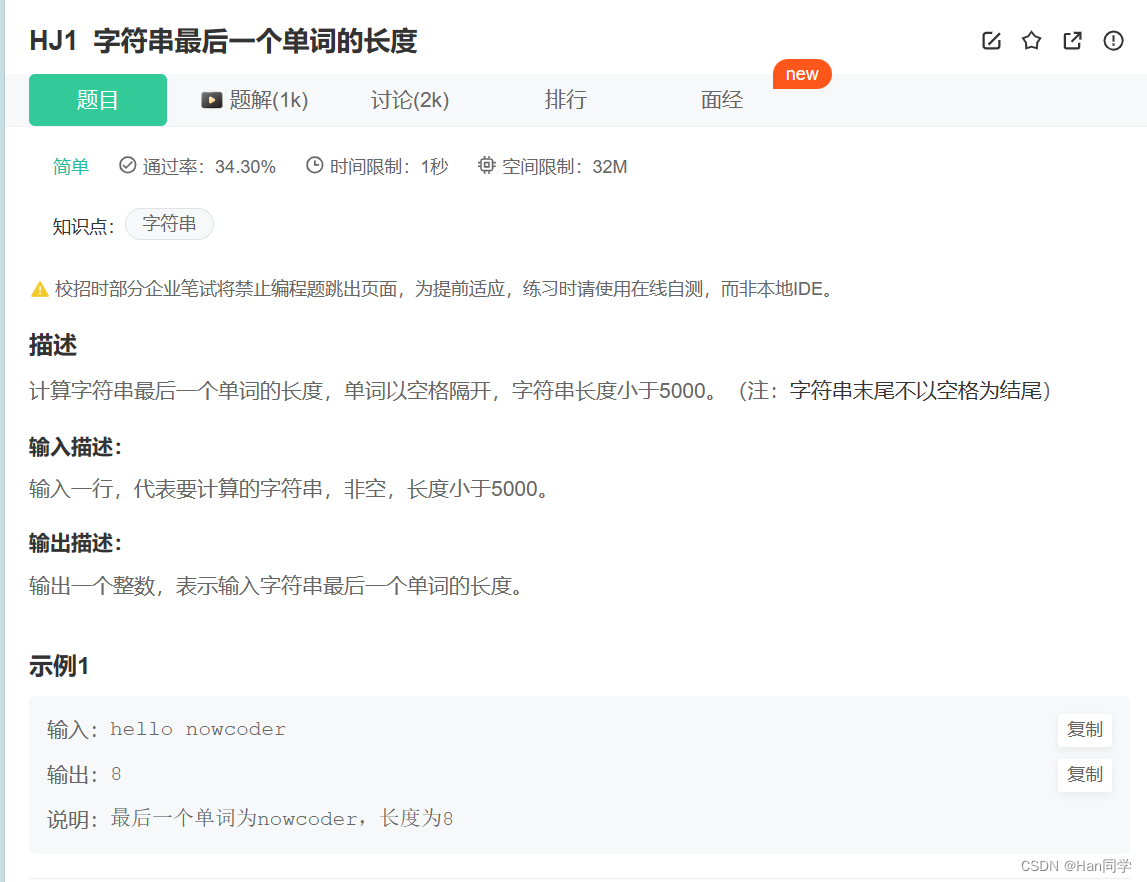
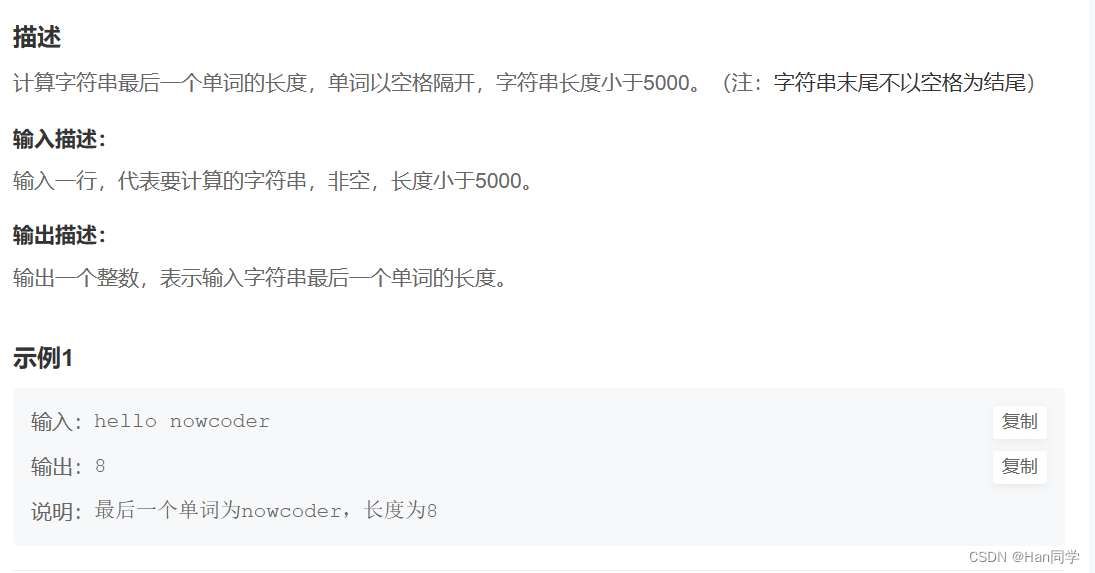
字符串最后一个单词的长度
找出字符串中第一个只出现一次的字符
字符串相加
字符串最后一个单词长度
字符串相乘
反转字符串3
反转字符串2
验证回文串
把字符串转换成整数
通过遍历字符串并逐位转换,处理空格、正负号和整数溢出的情况。最终返回转换后的整数。
class Solution {public:int StrToInt(string str) {const int len = str.length();if (len == 0) return 0;int i = 0;while (i < len && str[i] == ' ') {++i; // 排除开头的空格}if (i == len) return 0;if (!isdigit(str[i]) && str[i] != '+' && str[i] != '-') return 0;bool neg = str[i] == '-' ? true : false;i = isdigit(str[i]) ? i : i + 1;long long ans = 0L;while (i < len && isdigit(str[i])) {ans = ans * 10 + (str[i++] - '0');if (!neg && ans > INT_MAX) {ans = INT_MAX;break;}if (neg && ans > 1L + INT_MAX) {ans = 1L + INT_MAX;break;}}if (i != len) return 0; return !neg ? static_cast<int>(ans) : static_cast<int>(-ans);}
};-
首先,定义了一个函数
StrToInt,该函数接受一个字符串参数str,表示要转换的字符串。 -
获取字符串的长度,并检查长度是否为0。如果长度为0,则返回0。
-
初始化变量
i为0,用于遍历字符串。 -
使用
while循环跳过字符串开头的空格,将i向后移动。 -
检查
i是否已经达到字符串的末尾,如果是,则返回0。 -
检查
str[i]是否为数字、正号或负号。如果不是,则返回0。 -
根据
str[i]的值,确定是否为负数,并将结果存储在布尔变量neg中。 -
如果
str[i]不是数字,则将i向后移动一位。 -
初始化变量
ans为0,用于存储转换后的整数。 -
进入循环,只要
i小于字符串的长度且str[i]是数字,就执行循环体。 -
在循环体内,将
ans乘以10,并加上str[i]减去字符 '0' 的结果,以将字符转换为数字。 -
检查转换后的整数是否超出了
INT_MAX的范围。如果超出了,则将ans设置为INT_MAX或1L + INT_MAX,具体取决于neg的值。 -
将
i向后移动一位。 -
循环结束后,检查
i是否等于字符串的长度。如果不相等,则表示字符串中包含非数字字符,返回0。 -
根据
neg的值,返回转换后的整数,使用static_cast<int>进行类型转换。
反转字符串
class Solution {
public:void reverseString(vector<char>& s) {reverse(s.begin(),s.end());}
};字符串中的第一个唯一字符

class Solution {
public:int firstUniqChar(string s) {int count[26]={0};for(auto ch:s){count[ch-'a']++;}for(int i=0;i<s.size();i++){if(count[s[i]-'a']==1)return i;}return -1;}
};字符串最后一个单词的长度
#include <iostream>
using namespace std;int main() {string str;getline(cin,str);size_t pos=str.rfind(' ');if(pos!=string::npos){cout<<str.size()-pos-1<<endl;}else{cout<<str.size()<<endl;}
}找出字符串中第一个只出现一次的字符

#include <iostream>
#include <string>
using namespace std;int main() {string a;cin>>a;int charCount[256]={0};for(auto e:a){++charCount[e];}int s=-1;for(auto e:a){if(charCount[e]==1){cout<<e;s=1;break;}}if(s==-1)cout<<s;
}-
首先,定义了一个字符串变量
a,用于接收用户的输入。 -
创建一个大小为256的整型数组
charCount,用于记录每个字符在字符串中出现的次数。初始时,所有元素都被初始化为0。 -
使用
for循环遍历字符串a中的每个字符。 -
在循环中,将当前字符
e对应的charCount数组元素加1,以统计字符出现的次数。 -
初始化变量
s为-1,用于标记是否找到了不重复的字符。 -
使用另一个
for循环遍历字符串a中的每个字符。 -
在循环中,检查当前字符
e在charCount数组中的值。如果值为1,表示该字符只出现了一次,即为第一个不重复的字符。 -
输出该字符,并将变量
s设置为1,表示已找到不重复字符。 -
如果循环结束后
s仍为-1,表示没有找到不重复的字符。 -
输出变量
s的值,即-1。
字符串相加

class Solution {
public:string addStrings(string num1, string num2) {int end1=num1.size()-1;int end2=num2.size()-1;int next=0;string str;str.reserve(num1.size()>num2.size()?num1.size()+1:num2.size()+1);while(end1>=0||end2>=0){int val1=end1>=0?num1[end1]-'0':0;int val2=end2>=0?num2[end2]-'0':0;int ret =val1+val2+next;next=ret/10;ret=ret%10;str+='0'+ret;--end1,--end2;}if(next==1)str+='1';reverse(str.begin(),str.end());return str;}
};-
首先,定义了一个函数
addStrings,该函数接受两个字符串参数num1和num2,表示要相加的两个数字。 -
初始化变量
end1和end2分别为num1和num2的最后一个字符的索引。 -
初始化变量
next为0,用于记录进位。 -
创建一个空字符串
str,用于存储相加的结果。 -
根据两个字符串的长度,预先分配
str的容量,以避免不必要的内存重新分配。 -
进入循环,只要
end1或end2中至少有一个大于等于0,就执行循环体。 -
在循环体内,首先获取
num1和num2当前索引位置的字符,并将其转换为对应的数字值。如果已经超出字符串的范围,则将其视为0。 -
将
val1、val2和next相加,得到ret,并更新next为ret除以10的商,更新ret为ret除以10的余数。 -
将
ret转换为字符,并将其添加到str的末尾。 -
更新
end1和end2,向前移动一位。 -
循环结束后,如果
next为1,说明最高位有进位,将字符 '1' 添加到str的末尾。 -
将
str反转,得到正确的相加结果。 -
返回
str
字符串最后一个单词长度
首先介绍一下接下来会用到的读取字符串的函数getline.
getline 是 C++ 标准库中的一个函数,用于从输入流中读取一行字符串。它有以下几个特点:
-
读取一行字符串:
getline函数会读取输入流中的一行字符串,直到遇到换行符('\n') 或者文件结束符(EOF)。它将读取的字符串存储到指定的变量中。 -
处理空格字符:与
cin不同,getline函数会将空格字符(包括空格、制表符等)视为普通字符,而不是作为分隔符。这意味着getline可以读取包含空格的字符串,而不会在空格处停止读取。 -
保留换行符:
getline函数会将换行符('\n') 从输入流中读取并存储在字符串中,即使它是一行的结尾。这与cin不同,cin会将换行符视为分隔符并从输入流中丢弃。 -
指定分隔符:除了默认的换行符作为分隔符外,
getline函数还可以接受一个可选的分隔符参数,用于指定其他字符作为行的结束标志。例如,可以使用getline(cin, str, ',')来读取以逗号分隔的字符串。
#include <iostream>
using namespace std;int main() {string str;getline(cin,str);size_t pos=str.rfind(' ');if(pos!=string::npos){cout<<str.size()-pos-1<<endl;}else{cout<<str.size()<<endl;}
}字符串相乘

class Solution {
public:string multiply(string num1, string num2) {if(num1=="0"||num2=="0")return "0";int n1=num1.size(),n2=num2.size();string result(n1+n2,'0');for (int i = n1 - 1; i >= 0; i--) {for (int j = n2 - 1; j >= 0; j--) {int product = (num1[i] - '0') * (num2[j] - '0') + (result[i + j + 1] - '0');result[i + j + 1] = product % 10 + '0';result[i + j] += product / 10;}}size_t startpos = result.find_first_not_of("0");if (string::npos != startpos) {return result.substr(startpos);}return "0";}
};反转字符串3

class Solution {
public:string reverseWords(string s) {int pos=s.find(' ');int start=0;while(pos!=string::npos){reverse(s.begin()+start,s.begin()+pos);start=pos+1;pos=s.find(' ',pos+1); }reverse(s.begin()+start,s.end());return s;}
};反转字符串2

class Solution {
public:string reverseStr(string s, int k) {auto start = s.begin();while (start < s.end()) {if (start + k < s.end()) {reverse(start, start + k);} else {reverse(start, s.end());}start += 2 * k;}return s;}
};验证回文串

class Solution {
public:bool isPalindrome(string s) {string judge;for(char c:s){if(isalnum(c))judge+=tolower(c);}int left=0;int right=judge.size()-1;while(left<right){if(judge[left]!=judge[right]){return false;}++left;--right;}return true;}
};