个人做民宿需要建立网站吗php做网站怎么布局
一.继承的概念
继承是面向对象的三大特性之一
有些类与类之间存在特殊的关系,例如下图:
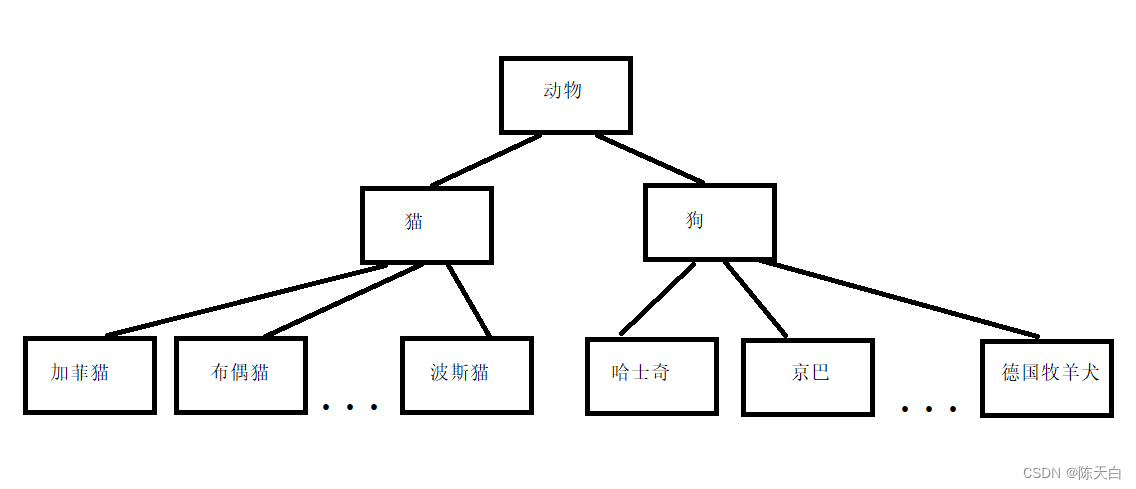
我们可以发现,下级别的成员除了拥有上一级的共性,还有自己的特性,这个时候,我们可以讨论利用继承的技术,减少代码重复代码,
继承语法:class 子类 :继承方式 父类。
子类也成为派生类,父类也称之为基类,派生类中的成员,包含两大部分。一类是从基类中继承过来的,一类是自己增加的成员,从基类继承过来的表现其共性,而新增的表现其个性
这边不理解就参考《马原》里事物的共性和个性的区别进行理解
代码案例:例如用c++编写一个网页
普通实现
#include<iostream>
using namespace std;
//Java页面
class Java
{
public:void header(){cout << "首页、公开课、登录、注册...(公共头部)" << endl;}void footer(){cout << "帮助中心、交流合作、站内地图...(公共底部)" << endl;}void left(){cout << "Java,Python,C++...(公共分类列表)" << endl;}void content(){cout << "JAVA学科视频" << endl;}
};
//Python页面
class Python
{
public:void header(){cout << "首页、公开课、登录、注册...(公共头部)" << endl;}void footer(){cout << "帮助中心、交流合作、站内地图...(公共底部)" << endl;}void left(){cout << "Java,Python,C++...(公共分类列表)" << endl;}void content(){cout << "Python学科视频" << endl;}
};
//C++页面
class CPP
{
public:void header(){cout << "首页、公开课、登录、注册...(公共头部)" << endl;}void footer(){cout << "帮助中心、交流合作、站内地图...(公共底部)" << endl;}void left(){cout << "Java,Python,C++...(公共分类列表)" << endl;}void content(){cout << "C++学科视频" << endl;}
};void test01()
{//Java页面cout << "Java下载视频页面如下: " << endl;Java ja;ja.header();ja.footer();ja.left();ja.content();cout << "--------------------" << endl;//Python页面cout << "Python下载视频页面如下: " << endl;Python py;py.header();py.footer();py.left();py.content();cout << "--------------------" << endl;//C++页面cout << "C++下载视频页面如下: " << endl;CPP cp;cp.header();cp.footer();cp.left();cp.content();}int main() {test01();system("pause");return 0;
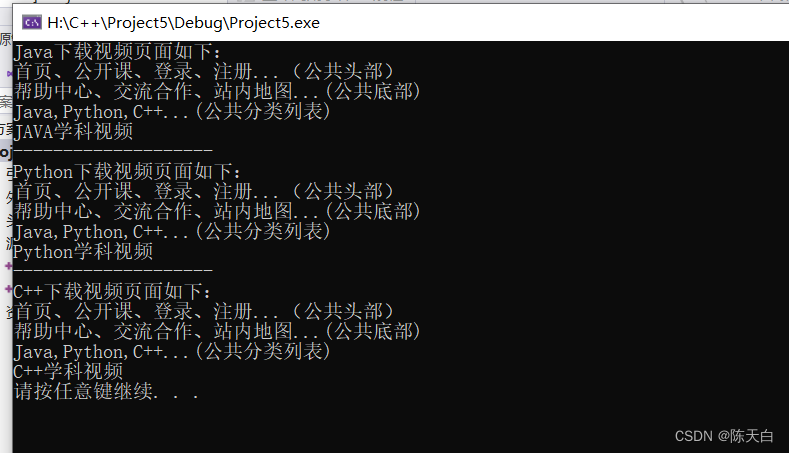
}效果图:

直接这样写会导致代码过于繁琐,重复率太高
以继承的方式实现:
代码示例:
#include<iostream>
using namespace std;
//公共页面
class BasePage
{
public:void header(){cout << "首页、公开课、登录、注册...(公共头部)" << endl;}void footer(){cout << "帮助中心、交流合作、站内地图...(公共底部)" << endl;}void left(){cout << "Java,Python,C++...(公共分类列表)" << endl;}};//Java页面
class Java : public BasePage
{
public:void content(){cout << "JAVA学科视频" << endl;}
};
//Python页面
class Python : public BasePage
{
public:void content(){cout << "Python学科视频" << endl;}
};
//C++页面
class CPP : public BasePage
{
public:void content(){cout << "C++学科视频" << endl;}
};void test01()
{//Java页面cout << "Java下载视频页面如下: " << endl;Java ja;ja.header();ja.footer();ja.left();ja.content();cout << "--------------------" << endl;//Python页面cout << "Python下载视频页面如下: " << endl;Python py;py.header();py.footer();py.left();py.content();cout << "--------------------" << endl;//C++页面cout << "C++下载视频页面如下: " << endl;CPP cp;cp.header();cp.footer();cp.left();cp.content();}int main() {test01();system("pause");return 0;
}剩下代码与上面一致
可见,代码量减少后显示内容不变