北京市保障房建设投资中心网站瘫痪宿迁做网站公司哪家好
下面是为任意事务代码查找用户出口的步骤:
方法一:
第 1 步:使用 事务代码:SE93。输入您要搜索用户出口的 事务代码。
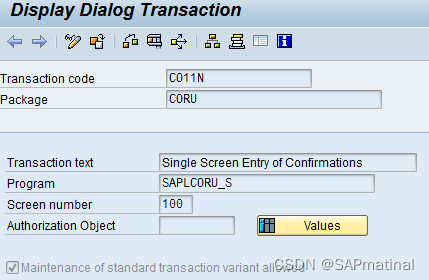
在我们的场景中,我们将使用 CO11N。
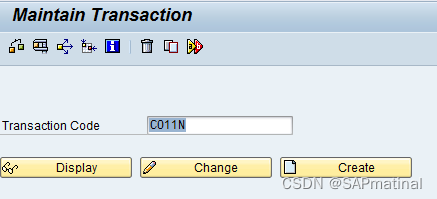
第 2 步:点击显示:
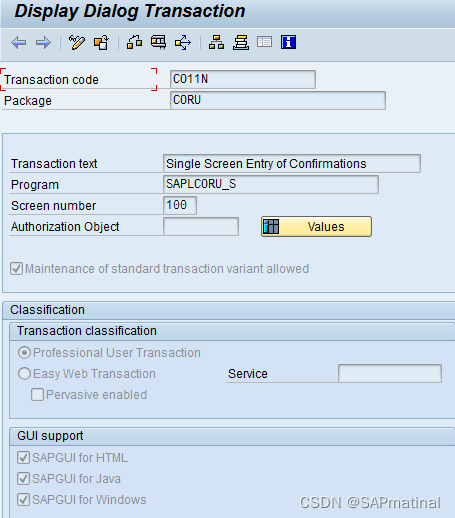
第 3 步:获取包裹:CORU。现在转到 事务代码:SMOD。
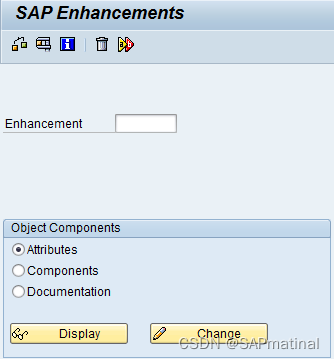
第四步:在增强中按F4。
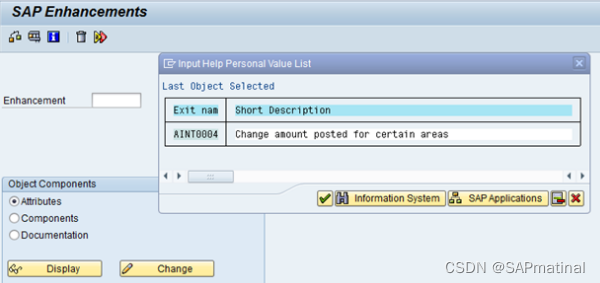
第五步:按信息系统按钮,然后在弹出的画面中输入包名(Repository Info System: Find Exits)
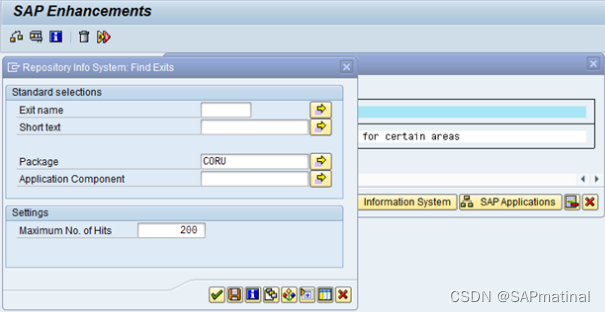
第 6 步:按回车键,您将获得一个带有描述的用户退出列表。
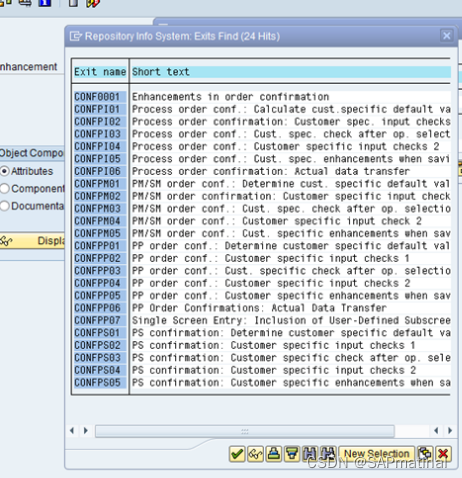
这就是为任意 事务代码找到用户出口的方式。
方法二:
第 1 步:转到 事务代码:CO11N(与上例相同)
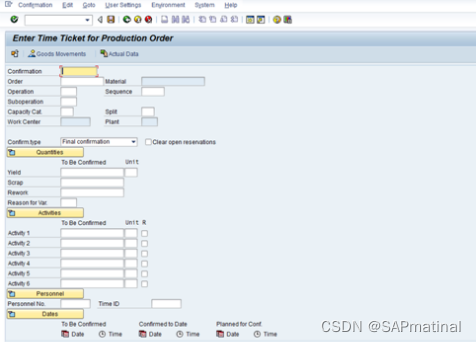
第二步:在菜单栏中选择“系统”。选择“状态”。
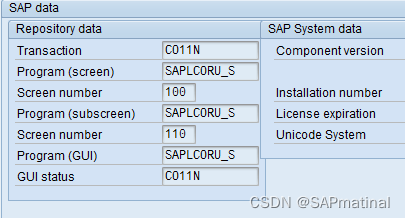
第 3 步:双击字段事务码:CO11N,将看到下面的屏幕,从那里选择包、。
第四步:得到包名后,按照流程一中的第三步到第六步进行同样的操作。