海南网站优化吧网站做软件的软件下载
欢迎来到《小5讲堂》
大家好,我是全栈小5。
这是《C#》系列文章,每篇文章将以博主理解的角度展开讲解,
特别是针对知识点的概念进行叙说,大部分文章将会对这些概念进行实际例子验证,以此达到加深对知识点的理解和掌握。
温馨提示:博主能力有限,理解水平有限,若有不对之处望指正!

目录
- 前言
- 图形处理库
- 常见库
- 自带库
- 创建图片
- SixLabors
- Drawing
- SkiaSharp
- Magick
- 相关文章
前言
最近升级改造图片功能,发现提示Image只在windows上支持。
这也就是意味着,如何还继续使用System.Drawing下的Image对象,把Core部署到linux系统是会有报错的。
因此,本篇文章就来了解下这两者的基本信息和使用。
图形处理库
常见库
1.SixLabors.ImageSharp:
这是一个跨平台的图形处理库,提供了丰富的图像操作功能,包括缩放、裁剪、旋转、滤镜、颜色调整等。
2.System.Drawing
这是 .NET Framework 提供的图形处理库,在 Windows 平台上有广泛的支持。它包含大量的图像操作类和方法,如 Image、Bitmap、Graphics 等。
3.SkiaSharp
这是一个用于各种平台的高性能2D图形库,适用于移动应用、游戏和 UI 开发。它提供了丰富的图像处理功能和绘图 API,可以在多个平台上运行。
4.Magick.NET
这是基于 ImageMagick 的 .NET 封装库,ImageMagick 是一个功能强大的开源图像处理库。Magick.NET 提供了丰富的图像处理功能,包括格式转换、调整大小、滤镜、特效等。
以上仅是一些常见的图形处理库,还有其他一些库可供选择,取决于具体需求和平台。
自带库
在 .NET Framework框架中,自带的图形处理库是System.Drawing,为什么在.net core中没有呢?
在 .NET Core 中,没有与 .NET Framework 中的 System.Drawing 直接对应的自带图形处理库。
由于 .NET Core 的跨平台性质和面向云原生应用的定位,微软选择没有将 System.Drawing 直接包含在 .NET Core 中。
不过,可以通过使用第三方图形处理库来进行图形操作。
其中最常用的是 SixLabors.ImageSharp,它是一个专门为 .NET Core 和 .NET Standard 开发的跨平台图形处理库,非常适合在 .NET Core 项目中进行图像处理。
创建图片
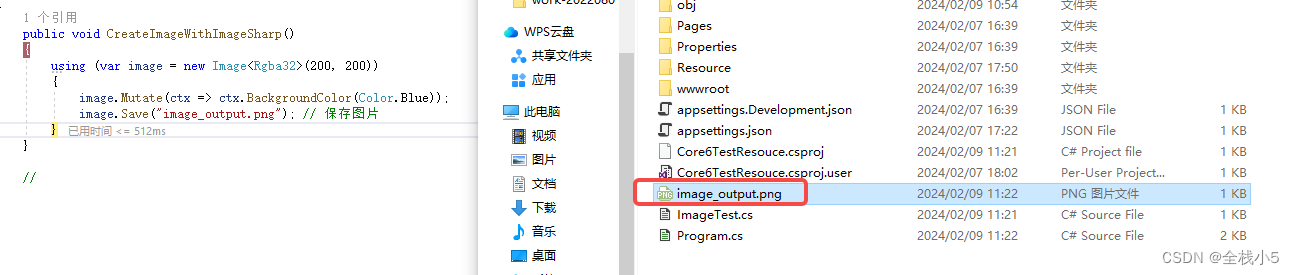
使用各个库创建一个尺寸为 200x200 的蓝色图片,并将其保存为 “image_output.png” 文件
SixLabors
引用版本,SixLabors.ImageSharp 3.1.2
下面是 SixLabors.ImageSharp 创建图片并输出的代码
using SixLabors.ImageSharp;
using SixLabors.ImageSharp.PixelFormats;
using SixLabors.ImageSharp.Processing;namespace Core6TestResouce
{public class ImageTest{public void CreateImageWithImageSharp(){using (var image = new Image<Rgba32>(200, 200)){image.Mutate(ctx => ctx.BackgroundColor(Color.Blue));image.Save("image_output.png"); // 保存图片}}//}
}
Drawing
下面是 System.Drawing 创建图片并输出的代码
using System.Drawing;public void CreateImageWithSystemDrawing()
{using (var image = new Bitmap(200, 200))using (var graphics = Graphics.FromImage(image)){graphics.Clear(Color.Blue); // 设置图片为蓝色image.Save("image_output.png"); // 保存图片}
}
SkiaSharp
下面是 SkiaSharp 创建图片并输出的代码
using SkiaSharp;public void CreateImageWithSkiaSharp()
{using (var bitmap = new SKBitmap(200, 200))using (var canvas = new SKCanvas(bitmap)){canvas.Clear(SKColors.Blue); // 设置图片为蓝色using (var image = SKImage.FromBitmap(bitmap))using (var data = image.Encode(SKImageEncodeFormat.Png, 100))using (var stream = System.IO.File.Create("image_output.png")){data.SaveTo(stream); // 保存图片}}
}
Magick
下面是 Magick.NET 创建图片并输出的代码
using ImageMagick;public void CreateImageWithMagickNET()
{using (var image = new MagickImage(new MagickColor("blue"), 200, 200)){image.Write("image_output.png"); // 保存图片}
}
相关文章
【C#】使用代码实现龙年春晚扑克牌魔术(守岁共此时),代码实现篇
【C#】使用代码实现龙年春晚扑克牌魔术(守岁共此时),流程描述篇
【C#】约瑟夫原理举例2个代码实现
【C#】List泛型数据集如何循环移动,最后一位移动到第一位,以此类推
【C#】获取文本中的链接,通过正则表达式的方法获取以及优化兼容多种格式
温故而知新,不同阶段重温知识点,会有不一样的认识和理解,博主将巩固一遍知识点,并以实践方式和大家分享,若能有所帮助和收获,这将是博主最大的创作动力和荣幸。也期待认识更多优秀新老博主。