长春网站优化指导网站常用热点hot小图标
基于springboot实现园周边美食探索及分享平台系统演示
摘要
美食一直是与人们日常生活息息相关的产业。传统的电话订餐或者到店消费已经不能适应市场发展的需求。随着网络的迅速崛起,互联网日益成为提供信息的最佳俱渠道和逐步走向传统的流通领域,传统的美食业进而也面临着巨大的挑战,此时推出网络订餐非常适时。
与传统的电话订餐以及去店里订餐的方式相比,网络订餐有着自己独特的优点——直观、互动性强、成本低、方便快捷。顾客可以及时了解到最新商品,及时反馈商家的服务;也能在商家营业的任何时候下单,并且自由决定送餐时间,这对于消费者也是更好的服务。对于商家来说,也可以更方便地留住有价值的客户,挖掘潜在客户等本论文系统地描绘了整个网上校园周边美食探索及分享平台的设计与实现,主要实现的功能有以下几点:管理员;首页、个人中心、用户管理、美食鉴赏管理、我的好友管理、我的收藏管理、系统管理,前台首页;首页、美食鉴赏、我的好友、个人中心、后台管理,用户后台;首页、个人中心、美食鉴赏管理、我的好友管理、我的收藏管理等功能,其具有简单的接口,方便的应用,强大的互动,完全基于互联网的特点。
现代社会的网络和信息技术不断提高,人们的生活水平达到一个新的层次。这篇文章研究了基于Spring Boot框架的校园周边美食探索及分享平台的开发和实现,从需求分析、总体设计到具体实现,最终完成了整个在线校园周边美食探索及分享平台,从而方便了用户和提高了管理员的管理水平。
关键词:校园周边美食探索及分享平台,Spring Boot框架,数据库MYSQL,Java语言
课题背景
2021年处于信息高速发展的大背景之下。在今天,缺少手机和电脑几乎已经成为不可能的事情,人们生活中已经难以离开手机和电脑。针对增加的成本管理和操作,商家非常有必要建立自己的网上校园周边美食探索及分享平台,这既可以让更多的人体验到网络所带来的方便。
以往的校园周边美食相关信息管理,都是工作人员手工统计。这种方式不但时效性低,而且需要查找和变更的时候很不方便。随着科学的进步,技术的成熟,计算机信息化也日新月异的发展,社会也已经深刻的认识,计算机功能非常的强大,计算机已经进入了社会发展的各个领域,并且发挥着十分重要的作用。本系统利用网络沟通、计算机信息存储管理,有着与传统的方式所无法替代的优点。比如计算检索速度特别快、可靠性特别高、存储容量特别大、保密性特别好、可保存时间特别长、成本特别低等。在工作效率上,能够得到极大地提高,延伸至服务水平也会有好的收获,有了网络, 校园周边美食探索及分享平台的开发各方面的管理更加科学和系统,更加规范和简便。
本文所设计的在线校园周边美食探索及分享平台就是在这种客观条件下进行的,在校园周边美食探索及分享平台管理方面,传统的管理方式显然无法与在线校园周边美食探索及分享平台相比,在线校园周边美食探索及分享平台正发挥着越来越重要的作用。在线校园周边美食校园周边美食探索及分享平台的速度快、信息量大、安全、简单都是传统模式难以企及的优点,在本文中的在线校园周边美食探索及分享平台是一个基于MySQL数据库和Spring Boot框架的。
课题意义
社会主义进入新时代,经济实力越来越强。我们也变得越来越忙碌、对生活的要求也变得更加严格,对快速和方便的服务的需求也在逐渐增加。因此,对服务行业的管理、服务的要求也越来越严格。为适应时代的发展,各大商家开始广泛地使用电脑来进行管理,为提高工作人员效率提供了一种新的方式,并且减轻了他们的工作强度,在树立商家形象的同时,为用户提供更加方便、简单而高效的服务,实现双赢。
本系统即为方便管理员、用户而制作的网上校园周边美食探索及分享平台,结合了用户的需求,设计出的一个基于Java、MySQL的网上校园周边美食探索及分享平台。
系统结构设计
整个系统是由多个功能模块组合而成的,要将所有的功能模块都一一列举出来,然后进行逐个的功能设计,使得每一个模块都有相对应的功能设计,然后进行系统整体的设计。
本校园周边美食探索及分享平台结构图如图3-2所示。

系统页展示
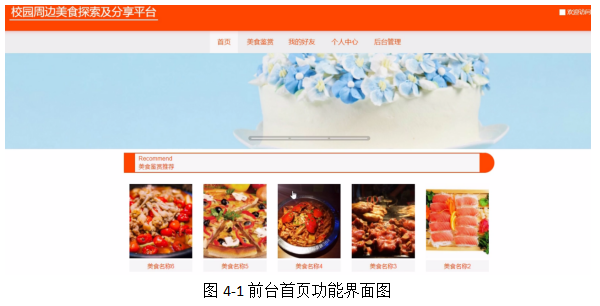
校园周边美食探索及分享平台,在系统首页可以查看首页、美食鉴赏、我的好友、个人中心、后台管理等内容,如图4-1所示。
美食鉴赏,在美食鉴赏页面查看发布时间、美食名称、美食类别、美食介绍、商品所在、推荐指数、美食照片、商品价格、用户名、姓名、美食介绍等信息进行点赞、评论,也可根据需要美食鉴赏名称进行搜索操作,如图4-3所示。

个人中心,在个人中心页面通过填写用户名、姓名、手机、邮箱、身份证、照片等信息进行添加、修改、删除进行更改操作,如图4-4所示。

用户登录进入校园周边美食探索及分享平台可以查看首页、个人中心、美食鉴赏管理、我的好友管理、我的收藏管理等内容。如图4-5所示。

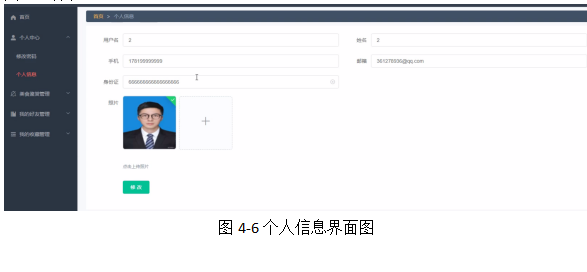
个人中心,用户在个人信息页面中可以查看用户名、姓名、手机、邮箱、身份证、照片等信息内容,并且根据需要对已有个人信息进行查看或删除等其他详细操作,如图4-6所示。
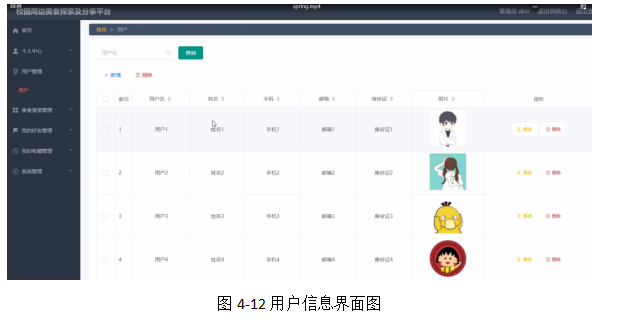
用户管理,管理员在用户信息页面中可以查看用户名、姓名、手机、邮箱、身份证、照片等信息,并可根据需要对已有用户信息进行修改或删除等操作,如图4-12所示。
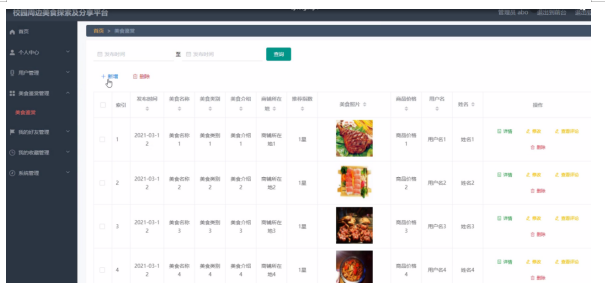
美食鉴赏管理,管理员在美食鉴赏信息页面中可以查看发布时间、美食名称、美食类别、美食介绍、商品所在、推荐指数、美食照片、商品价格、用户名、姓名、美食介绍等信息,并可根据需要对已有美食鉴赏信息进行新增、修改或删除等详细操作,如图4-13所示。
如需要可扫取文章下方二维码联系得源码