想自己做一个网站外贸出口新三样
文章目录
- 1.介绍
- 2.知识
- 2.1 基于响应的知识(response-based)
- 2.2 基于特征的知识(feature-based)
- 2.3 基于关系的知识(relation-based)
- 3.蒸馏机制
- 3.1 离线蒸馏
- 3.2 在线蒸馏
- 3.3 自蒸馏
- 4.教师-学生架构
- 5.蒸馏算法
- 5.1 对抗性蒸馏(Adversarial Distillation)
- 5.2 多教师蒸馏(Multi-teacher Distillation)
- 5.3 跨模态蒸馏(Cross-Modal Distillation)
- 5.4 基于图的蒸馏(Graph-Based Distillation)
- 5.5 基于注意力的蒸馏(Attention-Based Distillation)
- 5.6 无数据的蒸馏(Data-Free Distillation)
- 5.7 量化蒸馏(Quantized Distillation)
- 5.8 终身蒸馏(Lifelong Distillation)
- 6 论文
- Videos
- 7 开源项目
- PyTorch
- Lua
- Torch
- Theano
- Lasagne + Theano
- Tensorflow
- Caffe
- Keras
博客参考自: https://zhuanlan.zhihu.com/p/581286422?utm_id=0, 仅供学习使用。
知识蒸馏的关键在于:1)在教师网络中学到什么样的知识(知识的类型);2)师生网络架构;3)如何迁移知识(蒸馏算法)

1.介绍
知识蒸馏,近年来越来越受到研究界的关注。大型深度神经网络取得了显著的成功,特别是在大规模数据的真实场景中,因为当考虑新数据时,过度参数化提高了泛化性能。然而,由于移动设备的算力和存储受限,在这些设备中部署DNN模型是一个巨大的挑战。为了解决这个问题,Bucilua等人(2006)首次提出了模型压缩,将信息从大模型或集成模型转移到训练的小模型中,并且不会显著导致精度下降。从大模型中学习小模型的方法后来作为知识蒸馏正式推广。
在知识蒸馏中,小型学生模型通常由大型教师模型监督。其主要思想是:学生模型模仿教师模型,并获得近似甚至更优越的性能表现。关键问题是如何将大教师模型转移到小的学生模型上。知识蒸馏系统基本由三个关键部分组成:知识、蒸馏算法、教师-学生结构。其一般框架如下:

2.知识
将知识分为三种形式:基于响应的(response-based)、基于特征的(feature-based)、基于关系的(relation-based)。

2.1 基于响应的知识(response-based)
基于响应的知识通常指教师模型最后一个输出层的神经响应。其主要思想是直接模拟教师模型的最终预测。给定一个logit(即一般神经网络最后一层的输出,后接一个softmax可以转换为概率值)作为最后一个全连接层的输出,基于响应的知识蒸馏loss可以表示为: L R e s D ( z t , z s ) = L R ( z t , z s ) L_{ResD}(z_t,z_s) = L_R(z_t,z_s) LResD(zt,zs)=LR(zt,zs)。其中, L R ( . ) L_R(.) LR(.)表示logits的之间的loss, z t z_t zt和 z s z_s zs分别表示教师和学生的logits。典型的基于响应的知识蒸馏模型如下图:

基于响应的知识可以用于不同类型的模型预测。例如,在目标检测任务中的响应可能包含bounding box的偏移量的logits;在人体姿态估计任务中,教师模型的响应可能包括每个landmark的热力图。最流行的基于响应的图像分类知识被称为软标签(soft target)。软标签是输入的类别的概率,可以通过softmax函数估计为:

z j z_j zj 是第i个类别的logit, T T T是温度因子,控制每个软目标的重要性。软目标包含来自教师模型的暗信息知识(informative dark knowledge)。因此,软logits的蒸馏loss可以重写为:

通常, L R ( p ( z t , T ) , p ( z s , T ) ) L_R(p(z_t,T),p(z_s,T)) LR(p(zt,T),p(zs,T)),使用KL散度loss (Kullback-Leibler divergence,衡量两个概率分布的相似性的度量指标)。优化该等式可以使学生的logits与教师的logits相匹配。下图为基准知识蒸馏的具体架构。

然而,基于响应的知识通常需要依赖最后一层的输出,无法解决来自教师模型的中间层面的监督,而这对于使用非常深的神经网络进行表示学习非常重要。由于logits实际上是类别概率分布,因此基于响应的知识蒸馏限制在监督学习。
2.2 基于特征的知识(feature-based)
DNN善于随着抽象程度的增加学习到不同级别的特征表示。这被称为表示学习(representation learning)。对于最后一层的输出和中间层的输出(特征图,feature map),都可以作为监督学生模型训练的知识。来自中间层的基于特征的知识是基于响应的知识的一个很好的扩展,特别是对于训练窄而深的网络。
一般,基于特征的知识蒸馏loss可以表示为:

其中, f t ( x ) f_t(x) ft(x)、 f s ( x ) f_s(x) fs(x)分别是教师模型和学生模型的中间层特征图。变换函数 θ ( . ) \theta(.) θ(.)当教师和学生模型的特征图大小不同时应用。 L F ( . ) L_F(.) LF(.)衡量两个特征图的相似性,常用的有L1 norm、L2 norm、交叉熵等。下图为基于特征的知识蒸馏模型的通常架构。


2.3 基于关系的知识(relation-based)
基于响应和基于特征的知识都使用了教师模型中特定层的输出,基于关系的知识进一步探索了不同层或数据样本的关系。
一般,将基于特征图关系的关系知识蒸馏loss表述如下:



传统的知识迁移方法往往涉及到单个知识蒸馏,教师的软目标被直接蒸馏给学生。实际上,蒸馏的知识不仅包含特征信息,还包含数据样本之间的相互关系。这一节的关系涉及许多方面,作者的设计很灵活,建议看原论文更清楚。

3.蒸馏机制
根据教师模型是否与学生模型同时更新,知识蒸馏的学习方案可分为离线(offline)蒸馏、在线(online)蒸馏、自蒸馏(self-distillation)。

3.1 离线蒸馏
大多数之前的知识蒸馏方法都是离线的。最初的知识蒸馏中,知识从预训练的教师模型转移到学生模型中,整个训练过程包括两个阶段:1)大型教师模型蒸馏前在训练样本训练;2)教师模型以logits或中间特征的形式提取知识,将其在蒸馏过程中指导学生模型的训练。教师的结构是预定义的,很少关注教师模型的结构及其与学生模型的关系。因此,离线方法主要关注知识迁移的不同部分,包括知识设计、特征匹配或分布匹配的loss函数。离线方法的优点是简单、易于实现。
离线蒸馏方法通常采用单向的知识迁移和两阶段的训练程序。然而,训练时间长的、复杂的、高容量教师模型却无法避免,而在教师模型的指导下,离线蒸馏中的学生模型的训练通常是有效的。此外,教师与学生之间的能力差距始终存在,而且学生往往对教师有极大依赖。
3.2 在线蒸馏
为了克服离线蒸馏的局限性,提出了在线蒸馏来进一步提高学生模型的性能,特别是在没有大容量高性能教师模型的情况下。在线蒸馏时,教师模型和学生模型同步更新,而整个知识蒸馏框架都是端到端可训练的。
在线蒸馏是一种具有高效并行计算的单阶段端到端训练方案。然而,现有的在线方法(如相互学习)通常无法解决在线环境中的高容量教师,这使进一步探索在线环境中教师和学生模式之间的关系成为一个有趣的话题。
3.3 自蒸馏
在自蒸馏中,教师和学生模型使用相同的网络,这可以看作是在线蒸馏的一个特例。例如论文(Zhang, L., Song, J., Gao, A., Chen, J., Bao, C. & Ma, K. (2019b).Be your own teacher: Improve the performance of convolutional eural networks via self distillation. In ICCV.) 将网络深层的知识蒸馏到浅层部分。
从人类师生学习的角度也可以直观地理解离线、在线和自蒸馏。离线蒸馏是指知识渊博的教师教授学生知识;在线蒸馏是指教师和学生一起学习;自我蒸馏是指学生自己学习知识。而且,就像人类学习的方式一样,这三种蒸馏由于其自身的优点,可以相互补充
4.教师-学生架构
在知识蒸馏中,教师-学生架构是形成知识迁移的通用载体。换句话说,从教师到学生的知识获取和蒸馏的质量取决于如何设计教师和学生的网络结构。基于人类学习的习惯,希望学生模型能找到合适的教师。近年来,在蒸馏中,教师和学生的模型设置几乎是预先固定的,大小和结构不变,容易产生模型容量上的差距。两者之间模型的设置主要有以下关系:

Hinton等人(Hinton, G., Vinyals, O. & Dean, J. (2015). Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531.)曾将知识蒸馏设计为压缩深度神经网络的集合。深度神经网络的复杂性主要来自于深度和宽度这两个维度。通常需要将知识从更深、更宽的神经网络转移到更浅、更窄的神经网络。学生网络的结构通常有以下选择:1)教师网络的简化版本,层数更少,每一层的通道数更少;2)保留教师网络的结构,学生网络为其量化版本;3)具有高效基本运算的小型网络;4)具有优化全局网络结构的小网络;5)与教师网络的结构相同。
大网络和小网络之间容量的差距会阻碍知识的迁移。为了有效地将知识迁移到学生网络中,许多方法被提出来控制降低模型的复杂性。论文(Mirzadeh, S. I., Farajtabar, M., Li, A. & Ghasemzadeh, H. (2020). Improved knowledge distillation via teacher assistant. In AAAI.)引入了一个教师助手,来减少教师模型和学生模型之间的训练差距。另一篇工作通过残差学习进一步缩小差距,利用辅助结构来学习残差。还有其他一些方法关注减小教师模型与学生模型结构上的差异。例如将量化与知识蒸馏相结合,即学生模型是教师模型的量化版本。
通过替换基础组件也是有效的方法,例如将普通卷积替换为在移动和嵌入式设备上更高效的深度可分离卷积。受神经架构搜索的启发,通过搜索基于基础构建块的全局结构,小型神经网络的性能进一步提高。此外,动态搜索知识迁移机制的想法也出现在知识蒸馏中,例如,使用强化学习以数据驱动的方式自动去除冗余层,并寻找给定教师网络的最优学生网络。
5.蒸馏算法
一个简单但有效的知识迁移方法是直接匹配基于响应的、基于特征的或教师模型和学生模型之间的特征空间中的表示分布。这小节回顾用于知识迁移的典型蒸馏算法。
5.1 对抗性蒸馏(Adversarial Distillation)
生成对抗网络(GAN)中的鉴别器估计样本来自训练数据分布的概率,而生成器试图使用生成的数据样本欺骗鉴别器的概率预测。受此启发,许多对抗性的知识蒸馏方法已经被提出,以使教师和学生网络能够更好地理解真实的数据分布。

如上图,对抗性学习的蒸馏方法可以分为三类:
- a)训练一个对抗性生成器生成合成的数据,将其直接作为训练集或用于增强训练集。
其loss可以表示为: L K D = L G ( F t ( G ( z ) ) , F S ( G ( z ) ) ) L_{KD} =L_G(F_t(G(z)),F_S(G(z))) LKD=LG(Ft(G(z)),FS(G(z)))
其中, F t ( . ) F_t(.) Ft(.)和 F s ( . ) F_s(.) Fs(.)分别分别是教师模型和学生模型的输出; G ( z ) G(z) G(z)表示给定随机输入向量z的生成器G生成的训练样本; L G L_G LG是蒸馏损失,以迫使预测的概率分布与真实概率分布之间匹配,蒸馏损失函数通常采用交叉熵或KL散度。
- b)使用鉴别器,利用logits或特征来分辨样本来自教师或是学生模型

- c)在线方式进行,在每次迭代中,教师和学生共同进行优化
利用知识蒸馏压缩GAN,小GAN学生网络通过知识迁移模仿大GAN教师网络
从上述对抗性蒸馏方法中,可以得出三个主要结论:1)GAN是通过教师知识迁移来提高学生学习能力的有效工具;2)联合GAN和知识蒸馏可以为知识蒸馏的性能生成有价值的数据,克服了不可用和不可访问的数据的限制;3)知识蒸馏可以用来压缩GAN
5.2 多教师蒸馏(Multi-teacher Distillation)
不同的教师架构可以为学生网络提供他们自己有用的知识。在训练一个教师网络期间,多个教师网络可以单独或整体地用于蒸馏。在一个典型的师生框架中,教师通常是一个大的模型或一个大的模型的集合。要迁移来自多个教师的知识,最简单的方法是使用来自所有教师的平均响应作为监督信息。

多个教师网络通常使用logits和特征表示作为知识。除了来自所有教师的平均logits,还有其他的变体。文献(Chen, X., Su, J., & Zhang, J. (2019b). A two-teacher tramework for knowledge distillation. In ISNN.)使用了两个教师网络,其中一名教师将基于响应的知识迁移给学生,另一名将基于特征的知识迁移给学生。文献(Fukuda, T., Suzuki, M., Kurata, G., Thomas, S., Cui, J. & Ramabhadran,B. (2017). Effificient knowledge distillation from an ensemble of teachers. In Interspeech.))在每次迭代中从教师网络池中随机选择一名教师。
5.3 跨模态蒸馏(Cross-Modal Distillation)
在训练或测试时一些模态的数据或标签可能不可用,因此需要在不同模态间知识迁移。在教师模型预先训练的一种模态(如RGB图像)上,有大量注释良好的数据样本,(Gupta, S., Hoffman, J. & Malik, J. (2016). Cross modal distillation for supervision transfer. In CVPR.)将知识从教师模型迁移到学生模型,使用新的未标记输入模态,如深度图像(depth image)和光流(optical flow)。具体来说,所提出的方法依赖于涉及两种模态的未标记成对样本,即RGB和深度图像。然后将教师从RGB图像中获得的特征用于对学生的监督训练。成对样本背后的思想是通过成对样本迁移标注(annotation)或标签信息,并已广泛应用于跨模态应用。成对样本的示例还有1)在人类动作识别模型中,RGB视频和骨骼序列;2)在视觉问题回答方法中,将图像-问题-回答作为输入的三线性交互教师模型中的知识迁移到将图像-问题作为输入的双线性输入学生模型中。
跨模态蒸馏的框架如下:

跨模态总结如下:
ResK表示基于响应的知识,FeaK表示基于特征的知识,RelK表示基于关系的知识

5.4 基于图的蒸馏(Graph-Based Distillation)
大多数知识蒸馏算法侧重于将个体实例知识从教师传递给学生,而最近提出了一些方法使用图来探索数据内关系。这些基于图的蒸馏方法的主要思想是1)使用图作为教师知识的载体;2)使用图来控制教师知识的传递。基于图的知识可以归类为基于关系的知识。

- 1)使用图作为教师知识的载体
文献(Zhang, C. & Peng, Y. (2018). Better and faster: knowledge transfer from multiple self-supervised learning tasks via graph distillation for video classifification. In IJCAI)中,每个顶点表示一个自监督的教师,利用logits和中间特征构造两个图,将多个自监督的教师的知识转移给学校。
- 2)使用图来控制知识迁移
文献(Luo, Z., Hsieh, J. T., Jiang, L., Carlos Niebles, J.& Fei-Fei, L. (2018).Graph distillation for action detection with privileged http://modalities.In ECCV.)将模态差异纳入来自源领域的特权信息,特权信息。引入了一种有向图来探讨不同模态之间的关系。每个顶点表示一个模态,边表示一个模态和另一个模态之间的连接强度。
5.5 基于注意力的蒸馏(Attention-Based Distillation)
由于注意力可以很好地反映卷积神经网络的神经元激活,因此利用注意力机制在知识蒸馏中提高学生网络的性能。注意力迁移的核心是定义特征嵌入到神经网络各层中的注意力映射。
5.6 无数据的蒸馏(Data-Free Distillation)
无数据蒸馏的方法提出的背景是克服由于隐私性、合法性、安全性和保密问题导致的数据缺失。“data free”表明并没有训练数据,数据是新生成或综合产生的。新生的数据可以利用GAN来产生。合成数据通常由预先训练过的教师模型的特征表示生成

5.7 量化蒸馏(Quantized Distillation)
量化的目的是将高精度(如float32)表示的网络转换为低精度(如int8)以降低计算复杂度,而知识蒸馏的目的是训练一个小模型,以产生与复杂模型相当的性能。二者可以结合。
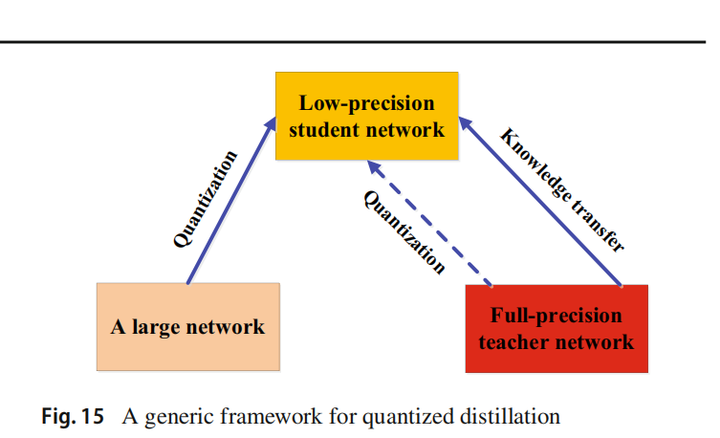
5.8 终身蒸馏(Lifelong Distillation)
终身学习,包括持续学习、集成学习和元学习,旨在以类似于人类的方式学习,积累了之前学到的知识,并将学到的知识转移到未来的学习中
5.9 基于神经架构搜索的蒸馏(NAS-Based Distillation)
神经架构搜索的目的是自动确认深度神经模型,并自适应地学习适当的神经结构。在知识蒸馏中,知识迁移的成功不仅取决于教师的知识,还取决于学生的体系结构。然而,在大教师模型和小学生模型之间可能存在着能力差距,这使得学生很难从老师那里学习得很好。为了解决这一问题,采用神经结构搜索寻找合适的学生结构。
6 论文
- Combining labeled and unlabeled data with co-training, A. Blum, T. Mitchell, 1998
- Ensemble Methods in Machine Learning, Thomas G. Dietterich, 2000
- Model Compression, Rich Caruana, 2006
- Dark knowledge, Geoffrey Hinton, Oriol Vinyals, Jeff Dean, 2014
- Learning with Pseudo-Ensembles, Philip Bachman, Ouais Alsharif, Doina Precup, 2014
- Distilling the Knowledge in a Neural Network, Geoffrey Hinton, Oriol Vinyals, Jeff Dean, 2015
- Cross Modal Distillation for Supervision Transfer, Saurabh Gupta, Judy Hoffman, Jitendra Malik, 2015
- Heterogeneous Knowledge Transfer in Video Emotion Recognition, Attribution and Summarization, Baohan Xu, Yanwei Fu, Yu-Gang Jiang, Boyang Li, Leonid Sigal, 2015
- Distilling Model Knowledge, George Papamakarios, 2015
- Unifying distillation and privileged information, David Lopez-Paz, Léon Bottou, Bernhard Schölkopf, Vladimir Vapnik, 2015
- Learning Using Privileged Information: Similarity Control and Knowledge Transfer, Vladimir Vapnik, Rauf Izmailov, 2015
- Distillation as a Defense to Adversarial Perturbations against Deep Neural Networks, Nicolas Papernot, Patrick McDaniel, Xi Wu, Somesh Jha, Ananthram Swami, 2016
- Do deep convolutional nets really need to be deep and convolutional?, Gregor Urban, Krzysztof J. Geras, Samira Ebrahimi Kahou, Ozlem Aslan, Shengjie Wang, Rich Caruana, Abdelrahman Mohamed, Matthai Philipose, Matt Richardson, 2016
- Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer, Sergey Zagoruyko, Nikos Komodakis, 2016
- FitNets: Hints for Thin Deep Nets, Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, Yoshua Bengio, 2015
- Deep Model Compression: Distilling Knowledge from Noisy Teachers, Bharat Bhusan Sau, Vineeth N. Balasubramanian, 2016
- Knowledge Distillation for Small-footprint Highway Networks, Liang Lu, Michelle Guo, Steve Renals, 2016
- Sequence-Level Knowledge Distillation, deeplearning-papernotes, Yoon Kim, Alexander M. Rush, 2016
- MobileID: Face Model Compression by Distilling Knowledge from Neurons, Ping Luo, Zhenyao Zhu, Ziwei Liu, Xiaogang Wang and Xiaoou Tang, 2016
- Recurrent Neural Network Training with Dark Knowledge Transfer, Zhiyuan Tang, Dong Wang, Zhiyong Zhang, 2016
- Adapting Models to Signal Degradation using Distillation, Jong-Chyi Su, Subhransu Maji,2016
- Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results, Antti Tarvainen, Harri Valpola, 2017
- Data-Free Knowledge Distillation For Deep Neural Networks, Raphael Gontijo Lopes, Stefano Fenu, 2017
- Like What You Like: Knowledge Distill via Neuron Selectivity Transfer, Zehao Huang, Naiyan Wang, 2017
- Learning Loss for Knowledge Distillation with Conditional Adversarial Networks, Zheng Xu, Yen-Chang Hsu, Jiawei Huang, 2017
- DarkRank: Accelerating Deep Metric Learning via Cross Sample Similarities Transfer, Yuntao Chen, Naiyan Wang, Zhaoxiang Zhang, 2017
- Knowledge Projection for Deep Neural Networks, Zhi Zhang, Guanghan Ning, Zhihai He, 2017
- Moonshine: Distilling with Cheap Convolutions, Elliot J. Crowley, Gavin Gray, Amos Storkey, 2017
- Local Affine Approximators for Improving Knowledge Transfer, Suraj Srinivas and Francois Fleuret, 2017
- Best of Both Worlds: Transferring Knowledge from Discriminative Learning to a Generative Visual Dialog Model, Jiasen Lu1, Anitha Kannan, Jianwei Yang, Devi Parikh, Dhruv Batra 2017
- Learning Efficient Object Detection Models with Knowledge Distillation, Guobin Chen, Wongun Choi, Xiang Yu, Tony Han, Manmohan Chandraker, 2017
- Learning Transferable Architectures for Scalable Image Recognition, Barret Zoph, Vijay Vasudevan, Jonathon Shlens, Quoc V. Le, 2017
- Revisiting knowledge transfer for training object class detectors, Jasper Uijlings, Stefan Popov, Vittorio Ferrari, 2017
- A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning, Junho Yim, Donggyu Joo, Jihoon Bae, Junmo Kim, 2017
- Rocket Launching: A Universal and Efficient Framework for Training Well-performing Light Net, Zihao Liu, Qi Liu, Tao Liu, Yanzhi Wang, Wujie Wen, 2017
- Data Distillation: Towards Omni-Supervised Learning, Ilija Radosavovic, Piotr Dollár, Ross Girshick, Georgia Gkioxari, Kaiming He, 2017
- Parallel WaveNet:Fast High-Fidelity Speech Synthesis, Aaron van den Oord, Yazhe Li, Igor Babuschkin, Karen Simonyan, Oriol Vinyals, Koray Kavukcuoglu, 2017
- Learning from Noisy Labels with Distillation, Yuncheng Li, Jianchao Yang, Yale Song, Liangliang Cao, Jiebo Luo, Li-Jia Li, 2017
- Deep Mutual Learning, Ying Zhang, Tao Xiang, Timothy M. Hospedales, Huchuan Lu, 2017
- Distilling a Neural Network Into a Soft Decision Tree, Nicholas Frosst, Geoffrey Hinton, 2017
- Interpreting Deep Classifiers by Visual Distillation of Dark Knowledge, Kai Xu, Dae Hoon Park, Chang Yi, Charles Sutton, 2018
- Efficient Neural Architecture Search via Parameters Sharing, Hieu Pham, Melody Y. Guan, Barret Zoph, Quoc V. Le, Jeff Dean, 2018
- Transparent Model Distillation, Sarah Tan, Rich Caruana, Giles Hooker, Albert Gordo, 2018
- Defensive Collaborative Multi-task Training - Defending against Adversarial Attack towards Deep Neural Networks, Derek Wang, Chaoran Li, Sheng Wen, Yang Xiang, Wanlei Zhou, Surya Nepal, 2018
- Deep Co-Training for Semi-Supervised Image Recognition, Siyuan Qiao, Wei Shen, Zhishuai Zhang, Bo Wang, Alan Yuille, 2018
- Feature Distillation: DNN-Oriented JPEG Compression Against Adversarial Examples, Zihao Liu, Qi Liu, Tao Liu, Yanzhi Wang, Wujie Wen, 2018
- Multimodal Recurrent Neural Networks with Information Transfer Layers for Indoor Scene Labeling, Abrar H. Abdulnabi, Bing Shuai, Zhen Zuo, Lap-Pui Chau, Gang Wang, 2018
- Born Again Neural Networks, Tommaso Furlanello, Zachary C. Lipton, Michael Tschannen, Laurent Itti, Anima Anandkumar, 2018
- YASENN: Explaining Neural Networks via Partitioning Activation Sequences, Yaroslav Zharov, Denis Korzhenkov, Pavel Shvechikov, Alexander Tuzhilin, 2018
- Knowledge Distillation with Adversarial Samples Supporting Decision Boundary, Byeongho Heo, Minsik Lee, Sangdoo Yun, Jin Young Choi, 2018
- Knowledge Transfer via Distillation of Activation Boundaries Formed by Hidden Neurons, Byeongho Heo, Minsik Lee, Sangdoo Yun, Jin Young Choi, 2018
- Self-supervised knowledge distillation using singular value decomposition, Seung Hyun Lee, Dae Ha Kim, Byung Cheol Song, 2018
- Multi-Label Image Classification via Knowledge Distillation from Weakly-Supervised Detection, Yongcheng Liu, Lu Sheng, Jing Shao, Junjie Yan, Shiming Xiang, Chunhong Pan, 2018
- Learning to Steer by Mimicking Features from Heterogeneous Auxiliary Networks, Yuenan Hou, Zheng Ma, Chunxiao Liu, Chen Change Loy, 2018
- A Generalized Meta-loss function for regression and classification using privileged information, Amina Asif, Muhammad Dawood, Fayyaz ul Amir Afsar Minhas, 2018
- Large scale distributed neural network training through online distillation, Rohan Anil, Gabriel Pereyra, Alexandre Passos, Robert Ormandi, George E. Dahl, Geoffrey E. Hinton, 2018
- KDGAN: Knowledge Distillation with Generative Adversarial Networks, Xiaojie Wang, Rui Zhang, Yu Sun, Jianzhong Qi, 2018
- Deep Face Recognition Model Compression via Knowledge Transfer and Distillation, Jayashree Karlekar, Jiashi Feng, Zi Sian Wong, Sugiri Pranata, 2019
- Relational Knowledge Distillation, Wonpyo Park, Dongju Kim, Yan Lu, Minsu Cho, 2019
- Graph-based Knowledge Distillation by Multi-head Attention Network, Seunghyun Lee, Byung Cheol Song, 2019
- Knowledge Adaptation for Efficient Semantic Segmentation, Tong He, Chunhua Shen, Zhi Tian, Dong Gong, Changming Sun, Youliang Yan, 2019
- Structured Knowledge Distillation for Semantic Segmentation, Yifan Liu, Ke Chen, Chris Liu, Zengchang Qin, Zhenbo Luo, Jingdong Wang, 2019
- Fast Human Pose Estimation, Feng Zhang, Xiatian Zhu, Mao Ye, 2019
- MEAL: Multi-Model Ensemble via Adversarial Learning, Zhiqiang Shen, Zhankui He, Xiangyang Xue, 2019
- Learning Lightweight Lane Detection CNNs by Self Attention Distillation, Yuenan Hou, Zheng Ma, Chunxiao Liu, Chen Change Loy, 2019
- Improved Knowledge Distillation via Teacher Assistant: Bridging the Gap Between Student and Teacher, Seyed-Iman Mirzadeh, Mehrdad Farajtabar, Ang Li, Hassan Ghasemzadeh, 2019
- A Comprehensive Overhaul of Feature Distillation, Byeongho Heo, Jeesoo Kim, Sangdoo Yun, Hyojin Park, Nojun Kwak, Jin Young Choi, 2019
- Contrastive Representation Distillation, Yonglong Tian, Dilip Krishnan, Phillip Isola, 2019
- Distillation-Based Training for Multi-Exit Architectures, Mary Phuong, Christoph H. Lampert, Am Campus, 2019
- Learning Metrics from Teachers: Compact Networks for Image Embedding, Lu Yu, Vacit Oguz Yazici, Xialei Liu, Joost van de Weijer, Yongmei Cheng, Arnau Ramisa, 2019
- On the Efficacy of Knowledge Distillation, Jang Hyun Cho, Bharath Hariharan, 2019
- Revisit Knowledge Distillation: a Teacher-free Framework, Li Yuan, Francis E.H.Tay, Guilin Li, Tao Wang, Jiashi Feng, 2019
- Ensemble Distribution Distillation, Andrey Malinin, Bruno Mlodozeniec, Mark Gales, 2019
- Improving Generalization and Robustness with Noisy Collaboration in Knowledge Distillation, Elahe Arani, Fahad Sarfraz, Bahram Zonooz, 2019
- Self-training with Noisy Student improves ImageNet classification, Qizhe Xie, Eduard Hovy, Minh-Thang Luong, Quoc V. Le, 2019
- Variational Student: Learning Compact and Sparser Networks in Knowledge Distillation Framework, Srinidhi Hegde, Ranjitha Prasad, Ramya Hebbalaguppe, Vishwajith Kumar, 2019
- Preparing Lessons: Improve Knowledge Distillation with Better Supervision, Tiancheng Wen, Shenqi Lai, Xueming Qian, 2019
- Positive-Unlabeled Compression on the Cloud, Yixing Xu, Yunhe Wang, Hanting Chen, Kai Han, Chunjing Xu, Dacheng Tao, Chang Xu, 2019
- Variational Information Distillation for Knowledge Transfer, Sungsoo Ahn, Shell Xu Hu, Andreas Damianou, Neil D. Lawrence, Zhenwen Dai, 2019
- Knowledge Distillation via Instance Relationship Graph, Yufan Liu, Jiajiong Cao, Bing Li, Chunfeng Yuan, Weiming Hu, Yangxi Li and Yunqiang Duan, 2019
- Knowledge Distillation via Route Constrained Optimization, Xiao Jin, Baoyun Peng, Yichao Wu, Yu Liu, Jiaheng Liu, Ding Liang, Junjie Yan, Xiaolin Hu, 2019
- Similarity-Preserving Knowledge Distillation, Frederick Tung, Greg Mori, 2019
- Distilling Object Detectors with Fine-grained Feature Imitation, Tao Wang, Li Yuan, Xiaopeng Zhang, Jiashi Feng, 2019
- Knowledge Squeezed Adversarial Network Compression, Shu Changyong, Li Peng, Xie Yuan, Qu Yanyun, Dai Longquan, Ma Lizhuang, 2019
- Stagewise Knowledge Distillation, Akshay Kulkarni, Navid Panchi, Shital Chiddarwar, 2019
- Knowledge Distillation from Internal Representations, Gustavo Aguilar, Yuan Ling, Yu Zhang, Benjamin Yao, Xing Fan, Edward Guo, 2019
- Knowledge Flow: Improve Upon Your Teachers, Iou-Jen Liu, Jian Peng, Alexander G. Schwing, 2019
- Graph Representation Learning via Multi-task Knowledge Distillation, Jiaqi Ma, Qiaozhu Mei, 2019
- Deep geometric knowledge distillation with graphs, Carlos Lassance, Myriam Bontonou, Ghouthi Boukli Hacene, Vincent Gripon, Jian Tang, Antonio Ortega, 2019
- Correlation Congruence for Knowledge Distillation, Baoyun Peng, Xiao Jin, Jiaheng Liu, Shunfeng Zhou, Yichao Wu, Yu Liu, Dongsheng Li, Zhaoning Zhang, 2019
- Be Your Own Teacher: Improve the Performance of Convolutional Neural Networks via Self Distillation, Linfeng Zhang, Jiebo Song, Anni Gao, Jingwei Chen, Chenglong Bao, Kaisheng Ma, 2019
- BAM! Born-Again Multi-Task Networks for Natural Language Understanding, Kevin Clark, Minh-Thang Luong, Urvashi Khandelwal, Christopher D. Manning, Quoc V. Le, 2019
- Self-Knowledge Distillation in Natural Language Processing, Sangchul Hahn, Heeyoul Choi, 2019
- Rethinking Data Augmentation: Self-Supervision and Self-Distillation, Hankook Lee, Sung Ju Hwang, Jinwoo Shin, 2019
- MSD: Multi-Self-Distillation Learning via Multi-classifiers within Deep Neural Networks, Yunteng Luan, Hanyu Zhao, Zhi Yang, Yafei Dai, 2019
- Efficient Video Classification Using Fewer Frames, Shweta Bhardwaj, Mukundhan Srinivasan, Mitesh M. Khapra, 2019
- Retaining Privileged Information for Multi-Task Learning, Fengyi Tang, Cao Xiao, Fei Wang, Jiayu Zhou, Li-Wei Lehman
- Data-Free Learning of Student Networks, Hanting Chen, Yunhe Wang, Chang Xu, Zhaohui Yang1, Chuanjian Liu, Boxin Shi, Chunjing Xu, Chao Xu, Qi Tian, 2019
- Positive-Unlabeled Compression on the Cloud, Yixing Xu, Yunhe Wang, Hanting Chen, Kai Han, Chunjing Xu, Dacheng Tao, Chang Xu, 2019
- When Does Label Smoothing Help?, Rafael Müller, Simon Kornblith, Geoffrey Hinton, 2019
- TinyBERT: Distilling BERT for Natural Language Understanding, Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, Qun Liu, 2019
- The State of Knowledge Distillation for Classification, Fabian Ruffy, Karanbir Chahal, 2019
- Distilling Task-Specific Knowledge from BERT into Simple Neural Networks, Raphael Tang, Yao Lu, Linqing Liu, Lili Mou, Olga Vechtomova, Jimmy Lin, 2019
- Channel Distillation: Channel-Wise Attention for Knowledge Distillation, Zaida Zhou, Chaoran Zhuge, Xinwei Guan, Wen Liu, 2020
- Residual Knowledge Distillation, Mengya Gao, Yujun Shen, Quanquan Li, Chen Change Loy, 2020
- ResKD: Residual-Guided Knowledge Distillation, Xuewei Li, Songyuan Li, Bourahla Omar, Fei Wu, Xi Li, 2020
- Dreaming to Distill: Data-free Knowledge Transfer via DeepInversion, Hongxu Yin, Pavlo Molchanov, Zhizhong Li, Jose M. Alvarez, Arun Mallya, Derek Hoiem, Niraj K. Jha, Jan Kautz, 2020
- MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tricks, Zhiqiang Shen, Marios Savvides, 2020
- MGD: Matching Guided Distillation, Kaiyu Yue, Jiangfan Deng, Feng Zhou, 2020
- Reducing the Teacher-Student Gap via Spherical Knowledge Disitllation, Jia Guo, Minghao Chen, Yao Hu, Chen Zhu, Xiaofei He, Deng Cai, 2020
- Regularizing Class-wise Predictions via Self-knowledge Distillation, Sukmin Yun, Jongjin Park, Kimin Lee, Jinwoo Shin, 2020
- Training data-efficient image transformers & distillation through attention, Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou, 2020
- Knowledge Distillation and Student-Teacher Learning for Visual Intelligence: A Review and New Outlooks, Lin Wang, Kuk-Jin Yoon, 2020
- Cross-Layer Distillation with Semantic Calibration,Defang Chen, Jian-Ping Mei, Yuan Zhang, Can Wang, Yan Feng, Chun Chen, 2020
- Subclass Distillation, Rafael Müller, Simon Kornblith, Geoffrey Hinton, 2020
- MobileStyleGAN: A Lightweight Convolutional Neural Network for High-Fidelity Image Synthesis, Sergei Belousov, 2021
- Knowledge Distillation: A Survey, Jianping Gou, Baosheng Yu, Stephen John Maybank, Dacheng Tao, 2021
- Refine Myself by Teaching Myself: Feature Refinement via Self-Knowledge Distillation, Mingi Ji, Seungjae Shin, Seunghyun Hwang, Gibeom Park, Il-Chul Moon, 2021
- Complementary Relation Contrastive Distillation,Jinguo Zhu, Shixiang Tang, Dapeng Chen, Shijie Yu, Yakun Liu, Aijun Yang, Mingzhe Rong, Xiaohua Wang, 2021
- Distilling Knowledge via Knowledge Review,Pengguang Chen, Shu Liu, Hengshuang Zhao, Jiaya Jia, 2021
- Hierarchical Self-supervised Augmented Knowledge Distillation, Chuanguang Yang, Zhulin An, Linhang Cai, Yongjun Xu, 2021
- Causal Distillation for Language Models, Zhengxuan Wu, Atticus Geiger, Josh Rozner, Elisa Kreiss, Hanson Lu, Thomas Icard, Christopher Potts, Noah D. Goodman, 2021
- How many Observations are Enough? Knowledge Distillation for Trajectory Forecasting, Alessio Monti, Angelo Porrello, Simone Calderara, Pasquale Coscia, Lamberto Ballan, Rita Cucchiara, 2022
- UniversalNER: Targeted Distillation from Large Language Models for Open Named Entity Recognition, Wenxuan Zhou, Sheng Zhang, Yu Gu, Muhao Chen, Hoifung Poon, 2023
Videos
- Dark knowledge, Geoffrey Hinton, 2014
- Model Compression, Rich Caruana, 2016
7 开源项目
PyTorch
- Attention Transfer
- Best of Both Worlds: Transferring Knowledge from Discriminative Learning to a Generative Visual Dialog Model
- Interpreting Deep Classifier by Visual Distillation of Dark Knowledge
- Mean teachers are better role models
- Relational Knowledge Distillation
- Knowledge Transfer via Distillation of Activation Boundaries Formed by Hidden Neurons
- Fast Human Pose Estimation Pytorch
- MEAL: Multi-Model Ensemble via Adversarial Learning
- MEAL-V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tricks
- Using Teacher Assistants to Improve Knowledge Distillation
- A Comprehensive Overhaul of Feature Distillation
- Contrastive Representation Distillation
- Transformer model distillation
- TinyBERT
- Data Efficient Model Compression
- Channel Distillation
- Dreaming to Distill: Data-free Knowledge Transfer via DeepInversion
- MGD: Matching Guided Distillation
- torchdistill: A Modular, Configuration-Driven Framework for Knowledge Distillation
- Knowledge Distillation on SSD
- distiller: A large scale study of Knowledge Distillation
- Knowledge-Distillation-Zoo: Pytorch implementation of various Knowledge Distillation (KD) methods
- A PyTorch implementation for exploring deep and shallow knowledge distillation (KD) experiments with flexibility
- Neural Network Distiller by Intel AI Lab: a Python package for neural network compression research.
- KD_Lib : A Pytorch Knowledge Distillation library for benchmarking and extending works in the domains of Knowledge Distillation, Pruning, and Quantization.
- Vision Transformer Distillation
- Cross-Layer Distillation with Semantic Calibration
- Refine Myself by Teaching Myself: Feature Refinement via Self-Knowledge Distillation
- Distilling Knowledge via Knowledge Review
- Hierarchical Self-supervised Augmented Knowledge Distillation
- Causal Distillation for Language Models
- UniversalNER
Lua
- Example for teacher/student-based learning
Torch
- Distilling knowledge to specialist ConvNets for clustered classification
- Sequence-Level Knowledge Distillation, Neural Machine Translation on Android
- cifar.torch distillation
- ENet-SAD
Theano
- FitNets: Hints for Thin Deep Nets
- Transfer knowledge from a large DNN or an ensemble of DNNs into a small DNN
Lasagne + Theano
- Experiments-with-Distilling-Knowledge
Tensorflow
- Deep Model Compression: Distilling Knowledge from Noisy Teachers
- Distillation
- An example application of neural network distillation to MNIST
- Data-free Knowledge Distillation for Deep Neural Networks
- Inspired by net2net, network distillation
- Deep Reinforcement Learning, knowledge transfer
- Knowledge Distillation using Tensorflow
- Knowledge Distillation Methods with Tensorflow
- Zero-Shot Knowledge Distillation in Deep Networks in ICML2019
- Knowledge_distillation_benchmark via Tensorflow2.0
Caffe
- Face Model Compression by Distilling Knowledge from Neurons
- KnowledgeDistillation Layer (Caffe implementation)
- Knowledge distillation, realized in caffe
- Cross Modal Distillation for Supervision Transfer
- Multi-Label Image Classification via Knowledge Distillation from Weakly-Supervised Detection
- Knowledge Distillation via Instance Relationship Graph
Keras
- Knowledge distillation with Keras
- keras google-vision’s distillation
- Distilling the knowledge in a Neural Network
-
https://github.com/PaddlePaddle/PaddleSlim/tree/release/2.0.0/docs/zh_cn/tutorials
-
https://github.com/FLHonker/Awesome-Knowledge-Distillation
-
https://github.com/dkozlov/awesome-knowledge-distillation