幻灯网站源码建设厅网站查询三类人员
在 2022 年 NVIDIA GTC 主题演讲中,NVIDIA 首席执行官黄仁勋介绍了基于全新 NVIDIA Hopper GPU 架构的全新 NVIDIA H100 Tensor Core GPU。
文章目录
- 前言
- 一、NVIDIA H100 Tensor Core GPU 简介
- 二、NVIDIA H100 GPU 主要功能概述
- 1. 新的流式多处理器 (SM) 具有许多性能和效率改进。
- 主要新功能包括:
- 2. 新的 transformer 引擎结合使用软件和定制的 NVIDIA Hopper Tensor Core 技术,该技术专为加速 transformer 模型训练和推理而设计。
- 3. HBM3 内存子系统的带宽比上一代增加了近 2 倍。
- 4. 50 MB L2 缓存架构可缓存大部分模型和数据集以供重复访问,从而减少对 HBM3 的迁移。
- 5. 与 A100 相比,第二代多实例 GPU (MIG) 技术为每个 GPU 实例提供大约 3 倍的计算容量和近 2 倍的内存带宽。
- 6. 新的机密计算支持可保护用户数据,抵御硬件和软件攻击,并在虚拟化和 MIG 环境中更好地隔离和保护虚拟机 (VM)。
- 7. 与上一代 NVLink 相比,第四代 NVIDIA NVLink 的全缩减操作带宽增加了 3 倍,一般带宽增加了 50%,总带宽为 900 GB/秒,适用于以 PCIe Gen 7 带宽运行的多 GPU IO。
- 8. 第三代 NVSwitch 技术包括驻留在节点内部和外部的交换机,用于连接服务器、集群和数据中心环境中的多个 GPU。
- 9. 新的 NVLink 交换机系统互连技术和基于第三代 NVSwitch 技术的新型二级 NVLink 交换机引入了地址空间隔离和保护,使多达 32 个节点或 256 个 GPU 能够通过 NVLink 以 2:1 锥形胖树拓扑进行连接。
- 10. PCIe Gen 5 提供 128 GB/秒的总带宽(每个方向 64 GB/秒),而第 4 代 PCIe 的总带宽为 64 GB/秒(每个方向 32 GB/秒)。
- 三、NVIDIA H100 GPU 架构深入
- 1. 基于全新 NVIDIA Hopper GPU 架构的 NVIDIA H100 GPU 具有多项创新:
- 2. 许多其他新的架构功能使许多应用程序能够实现高达 3 倍的性能提升。
- 3. NVIDIA H100 是第一款真正的异步 GPU。
- 4. 现在只需要少量的 CUDA 线程就可以使用新的 Tensor Memory Accelerator 来管理 H100 的全部内存带宽,而大多数其他 CUDA 线程可以专注于通用计算,例如新一代 Tensor Core 的预处理和后处理数据。
- 5. H100 通过一个称为线程块集群的新级别来扩展 CUDA 线程组层次结构。
- 6. 编排越来越多的片上加速器和各种通用线程组需要同步。
- 7. NVIDIA 异步事务屏障使集群内的通用 CUDA 线程和片上加速器能够高效同步,即使它们位于不同的 SM 上。
- 8. 为 H100 GPU 提供动力的完整 GH100 GPU 采用为 NVIDIA 定制的台积电 4N 工艺制造,具有 800 亿个晶体管、814 mm2 的芯片尺寸和更高频率的设计。
- 9. NVIDIA GH100 GPU 由多个 GPU 处理集群 (GPC)、纹理处理集群 (TPC)、流式多处理器 (SM)、L2 缓存和 HBM3 内存控制器组成。
- 10. GH100 GPU 的完整实施包括以下单元:
- 11. 采用 SXM5 板型的 NVIDIA H100 GPU 包括以下单元:
- 12. 采用 PCIe Gen 5 主板外形的 NVIDIA H100 GPU 包括以下单元:
- 13. 与基于台积电 7nm N7 工艺的上一代 GA100 GPU 相比,使用台积电 4N 制造工艺使 H100 能够提高 GPU 内核频率,提高每瓦性能,并包含更多的 GPC、TPC 和 SM。
- 四、H100 SM architecture H100 SM 架构
- 1. H100 SM 基于 NVIDIA A100 Tensor Core GPU SM 架构构建,由于引入了 FP8,H100 SM 的每 SM 浮点计算能力是 A100 峰值的四倍,并且在所有以前的 Tensor Core 、 FP32 和 FP64 数据类型上,A100 原始 SM 计算能力是时钟对时钟的两倍。
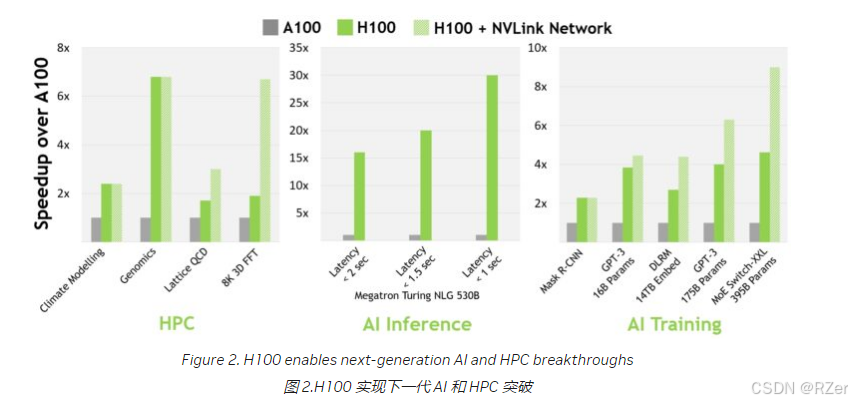
- 2. 与上一代 A100 相比,新的 Transformer 引擎与 NVIDIA Hopper FP8 Tensor Core 相结合,在大型语言模型上提供高达 9 倍的 AI 训练速度和 30 倍的 AI 推理速度。
- 3. 新的 NVIDIA Hopper 第四代 Tensor Core、Tensor Memory Accelerator 以及许多其他新的 SM 和通用 H100 架构改进共同在许多其他情况下将 HPC 和 AI 性能提高了 3 倍。
- 五、H100 SM 主要功能摘要
- 1. 第四代 Tensor 核心:
- 2. 新的 DPX 指令将动态编程算法的速度比 A100 GPU 快 7 倍。
- 3. 与 A100 相比,IEEE FP64 和 FP32 的芯片到芯片处理速率提高了 3 倍,因为每个 SM 的时钟对时钟性能提高了 2 倍,此外还有额外的 SM 数量和更高的 H100 时钟。
- 4. 256 KB 的组合共享内存和 L1 数据缓存,比 A100 大 1.33 倍。
- 5. 新的异步执行功能包括一个新的 Tensor Memory Accelerator (TMA) 单元,它可以在全局内存和共享内存之间高效传输大型数据块。
- 6. 新的线程块集群功能公开了跨多个 SM 的局部性控制。
- 7. 分布式共享内存支持跨多个 SM 共享内存模块的加载、存储和原子的直接 SM 到 SM 通信
- 六、H100 Tensor Core 架构
- 1.Tensor Core 是专门用于矩阵乘法和累加 (MMA) 数学运算的高性能计算核心,可为 AI 和 HPC 应用程序提供突破性的性能。
- 2. Tensor Core 首先在 NVIDIA V100 GPU 中引入,并在每一代新的 NVIDIA GPU 架构中进一步增强。
- 3. 与 A100 相比,H100 中新的第四代 Tensor Core 架构为每个 SM 提供两倍的原始密集和稀疏矩阵数学吞吐量(时钟对时钟),考虑到 H100 比 A100 更高的 GPU Boost 时钟,甚至更高。
- 七、NVIDIA Hopper FP8 数据格式
- 1. H100 GPU 增加了 FP8 Tensor Core,以加速 AI 训练和推理。
- 八、用于加速动态编程的新 DPX 指令
- 九、H100 计算性能摘要
- 十、H100 GPU 层次结构和异步改进
- 十一、Thread block clusters 线程块集群
- 十二、分布式共享内存
- 十三、Asynchronous execution 异步执行
- 十四、Tensor 内存加速器
- 十五、Tensor 内存加速器
- 十六、异步事务屏障
- 十七、H100 HBM 和 L2 高速缓存架构
- 十八、H100 HBM3 和 HBM2e DRAM 子系统
- 十九、H100 L2 cache H100 L2 缓存


前言
这篇文章将带您了解新的 H100 GPU ,并介绍 NVIDIA Hopper 架构 GPU 的重要新功能。
一、NVIDIA H100 Tensor Core GPU 简介
NVIDIA H100 Tensor Core GPU 是我们的第九代数据中心 GPU,旨在为大规模 AI 和 HPC 提供比上一代 NVIDIA A100 Tensor Core GPU 高一个数量级的性能飞跃。H100 继承了 A100 的主要设计重点,以改善 AI 和 HPC 工作负载的强大扩展,并显著提高架构效率。

对于当今主流的 AI 和 HPC 模型,具有 InfiniBand 互连功能的 H100 可提供高达 A100 30 倍的性能。新的 NVLink 交换机系统互连针对一些最大和最具挑战性的计算工作负载,这些工作负载需要跨多个 GPU 加速节点的模型并行性才能适应。这些工作负载又实现了一次代际性能飞跃,在某些情况下,性能再次是 H100 的三倍,使用 InfiniBand。
二、NVIDIA H100 GPU 主要功能概述
1. 新的流式多处理器 (SM) 具有许多性能和效率改进。
主要新功能包括:
-
与 A100 相比,新的第四代 Tensor Core 的芯片到芯片速度提高了 6 倍,包括每 SM 加速、额外的 SM 数量和更高的 H100 时钟。与上一代 16 位浮点选项相比,在每个 SM 的基础上,Tensor Core 在等效数据类型上提供的 MMA(矩阵乘法累加)计算速率是 A100 SM 的 2 倍,使用新 FP8 数据类型的 A100 的 4 倍。稀疏性功能利用深度学习网络中的细粒度结构化稀疏性,将标准 Tensor Core 运算的性能提高了一倍
-
与 A100 GPU 相比,新的 DPX 指令将动态编程算法的速度提高了 7 倍。两个示例包括用于基因组学处理的 Smith-Waterman 算法,以及用于通过动态仓库环境为机器人队列寻找最佳路线的 Floyd-Warshall 算法。
-
与 A100 相比,IEEE FP64 和 FP32 的芯片到芯片处理速率提高了 3 倍,因为每个 SM 的时钟对时钟性能提高了 2 倍,此外还有额外的 SM 数量和更高的 H100 时钟。
-
新的线程块群集功能支持以大于单个 SM 上单个线程块的粒度对位置进行编程控制。这通过向编程层次结构添加另一个级别来扩展 CUDA 编程模型,现在包括线程、线程块、线程块集群和网格。集群支持跨多个 SM 并发运行的多个线程块,以同步和协作获取和交换数据。
-
分布式共享内存允许跨多个 SM 共享内存模块的加载、存储和原子的直接 SM 到 SM 通信。
-
新的异步执行功能包括一个新的 Tensor Memory Accelerator (TMA) 单元,该单元可以在全局内存和共享内存之间高效传输大块数据。TMA 还支持集群中线程块之间的异步复制。还有一个新的异步事务屏障,用于执行原子数据移动和同步。
2. 新的 transformer 引擎结合使用软件和定制的 NVIDIA Hopper Tensor Core 技术,该技术专为加速 transformer 模型训练和推理而设计。
Transformer 引擎智能地管理 FP8 和 16 位计算并在 FP8 和 16 位计算之间动态选择,在每一层中自动处理 FP8 和 16 位之间的重新转换和缩放,与上一代 A100 相比,在大型语言模型上提供高达 9 倍的 AI 训练速度和高达 30 倍的 AI 推理速度。
3. HBM3 内存子系统的带宽比上一代增加了近 2 倍。
H100 SXM5 GPU 是世界上第一款采用 HBM3 显存的 GPU,可提供一流的 3 TB/秒内存带宽。
4. 50 MB L2 缓存架构可缓存大部分模型和数据集以供重复访问,从而减少对 HBM3 的迁移。
5. 与 A100 相比,第二代多实例 GPU (MIG) 技术为每个 GPU 实例提供大约 3 倍的计算容量和近 2 倍的内存带宽。
现在首次提供具有 MIG 级 TEE 的机密计算功能。最多支持 7 个单独的 GPU 实例,每个实例都有专用的 NVDEC 和 NVJPG 单元。现在,每个实例都包含自己的一组性能监控器,这些监控器可与 NVIDIA 开发人员工具配合使用。
6. 新的机密计算支持可保护用户数据,抵御硬件和软件攻击,并在虚拟化和 MIG 环境中更好地隔离和保护虚拟机 (VM)。
H100 实现了世界上第一个原生机密计算 GPU,并通过 CPU 以全 PCIe 线速扩展了可信执行环境 (TEE)。
7. 与上一代 NVLink 相比,第四代 NVIDIA NVLink 的全缩减操作带宽增加了 3 倍,一般带宽增加了 50%,总带宽为 900 GB/秒,适用于以 PCIe Gen 7 带宽运行的多 GPU IO。
8. 第三代 NVSwitch 技术包括驻留在节点内部和外部的交换机,用于连接服务器、集群和数据中心环境中的多个 GPU。
节点中的每个 NVSwitch 都提供 64 个第四代 NVLink 链路端口,以加速多 GPU 连接。交换机总吞吐量从上一代的 7.2 Tbits/秒增加到 13.6 Tbits/秒。新的第三代 NVSwitch 技术还为集体操作提供硬件加速,包括多播和 NVIDIA SHARP 网络内减少。
9. 新的 NVLink 交换机系统互连技术和基于第三代 NVSwitch 技术的新型二级 NVLink 交换机引入了地址空间隔离和保护,使多达 32 个节点或 256 个 GPU 能够通过 NVLink 以 2:1 锥形胖树拓扑进行连接。
这些连接的节点能够提供 57.6 TB/秒的全对全带宽,并且可以提供令人难以置信的 1 exaFLOP FP8 稀疏 AI 计算。
10. PCIe Gen 5 提供 128 GB/秒的总带宽(每个方向 64 GB/秒),而第 4 代 PCIe 的总带宽为 64 GB/秒(每个方向 32 GB/秒)。
PCIe Gen 5 使 H100 能够与最高性能的 x86 CPU 和 SmartNIC 或数据处理单元 (DPU) 连接。
还包括许多其他新功能,以改进强扩展、减少延迟和开销,并从总体上简化 GPU 编程。
三、NVIDIA H100 GPU 架构深入
1. 基于全新 NVIDIA Hopper GPU 架构的 NVIDIA H100 GPU 具有多项创新:
-
新的第四代 Tensor Core 在更广泛的 AI 和 HPC 任务上执行比以往更快的矩阵计算。
-
新的 transformer 引擎使 H100 的 AI 训练速度提高了 9 倍,AI 速度提高了 30 倍。与上一代 A100 相比