金鹏建设集团网站肇庆住房建设部网站
释义
集成学习很好的避免了单一学习模型带来的过拟合问题
根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类:
- Bagging(个体学习器间不存在强依赖关系、可同时生成的并行化方法) 流行版本:随机森林(random forest)
- Boosting(个体学习器间存在强依赖关系、必须串行生成的序列化方法) AdaBoost
example:
选男友: 美女选择择偶对象的时候,会问几个闺蜜的建议,最后选择一个综合得分最高的一个作为男朋友(bagging)
追女友: 3个帅哥追同一个美女,第1个帅哥失败->(传授经验: 姓名、家庭情况) 第2个帅哥失败->(传授经验: 兴趣爱好、性格特点) 第3个帅哥成功(boosting)
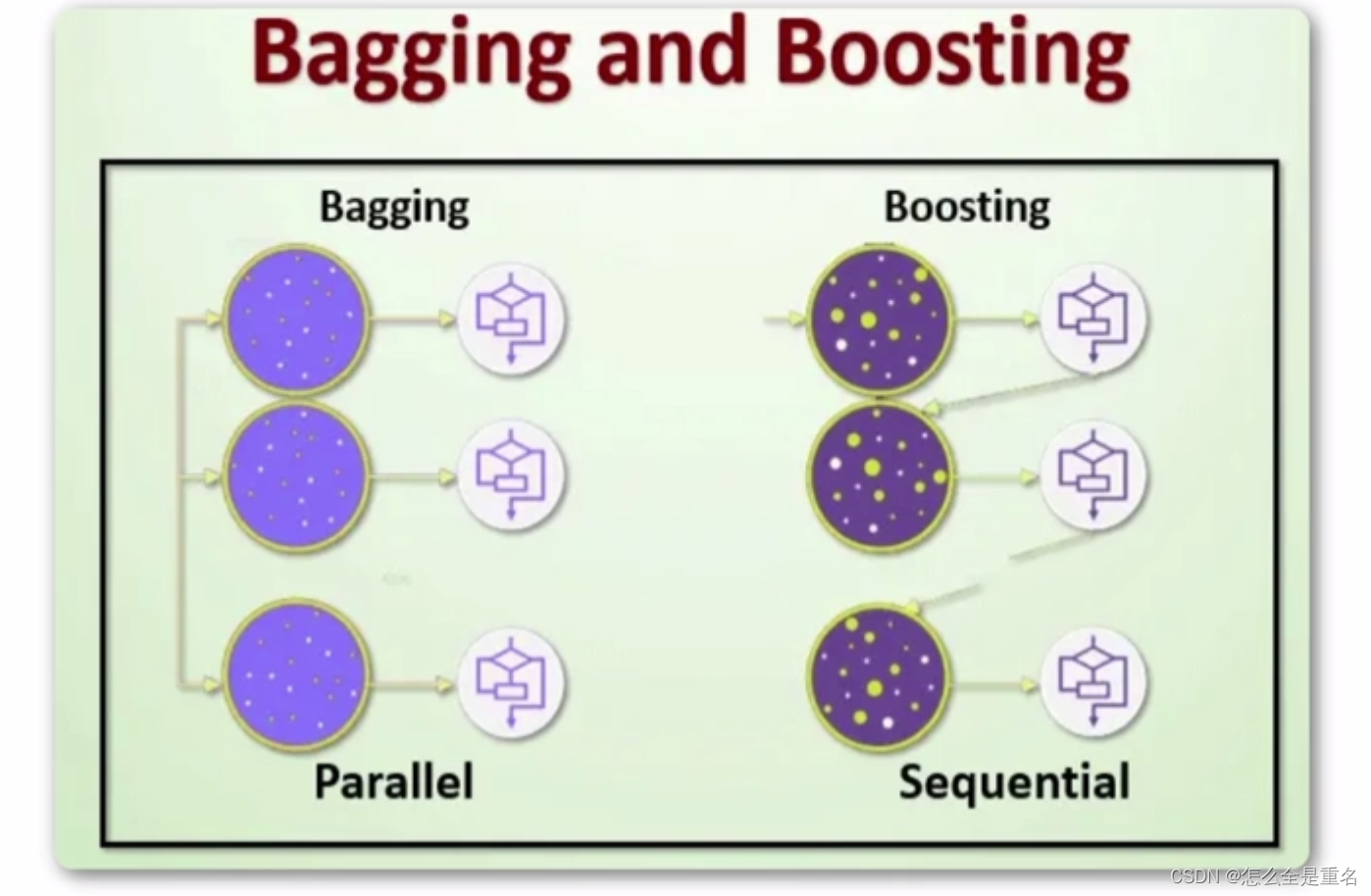
两者区别
bagging 是一种与 boosting 很类似的技术, 所使用的多个分类器的类型(数据量和特征量)都是一致的。
bagging 是由不同的分类器(1.数据随机化 2.特征随机化)经过训练,综合得出的出现最多分类结果;boosting 是通过调整已有分类器错分的那些数据来获得新的分类器,得出目前最优的结果。
bagging 中的分类器权重是相等的;而 boosting 中的分类器加权求和,所以权重并不相等,每个权重代表的是其对应分类器在上一轮迭代中的成功度。
自助采样法(bootstrap sampling):
给定包含m个样本的数据集,先随机取出一个样本放入采样集中并记录,再把该样本放回初始数据集,使得下次采样时该样本仍有可能被选中,这样,经过m次随机采样操作,我们得到含m个样本的采样集,初始训练集中有的样本在采样集里多次出现,有的则从未出现(平均37%没有取到)。
这些未取到的样本称为OOB(Out of Bag),可以使用这部分OOB的数据集作为测试集
Bagging的基本流程
基于每个采样集训练出一个基学习器,再将这些基学习器进行结合
- 对分类任务,使用简单投票法
- 对回归任务,使用简单平均法
随机森林
- 随机森林指的是利用多棵树对样本进行训练并预测的一种分类器。
- 决策树相当于一个大师,通过自己在数据集中学到的知识用于新数据的分类。但是俗话说得好,一个诸葛亮,玩不过三个臭皮匠。随机森林就是希望构建多个臭皮匠,希望最终的分类效果能够超过单个大师的一种算法。
原理
look
数据的随机性化
待选特征的随机化
使得随机森林中的决策树都能够彼此不同,提升系统的多样性,从而提升分类性能。
数据的随机化: 使得随机森林中的决策树更普遍化一点,适合更多的场景。
(有放回的准确率在: 70% 以上, 无放回的准确率在: 60% 以上)
采取有放回的抽样方式 构造子数据集,保证不同子集之间的数量级一样(不同子集/同一子集 之间的元素可以重复)
利用子数据集来构建子决策树,将这个数据放到每个子决策树中,每个子决策树输出一个结果。
然后统计子决策树的投票结果,得到最终的分类 就是 随机森林的输出结果。


RF的简单例子
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 加载鸢尾花数据集
data = load_iris()
X = data.data # 特征
y = data.target # 目标# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建随机森林分类器
clf = RandomForestClassifier(n_estimators=100, random_state=42)# 训练分类器
clf.fit(X_train, y_train)# 使用分类器进行预测
y_pred = clf.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)AdaBoost
Adaboost的原理
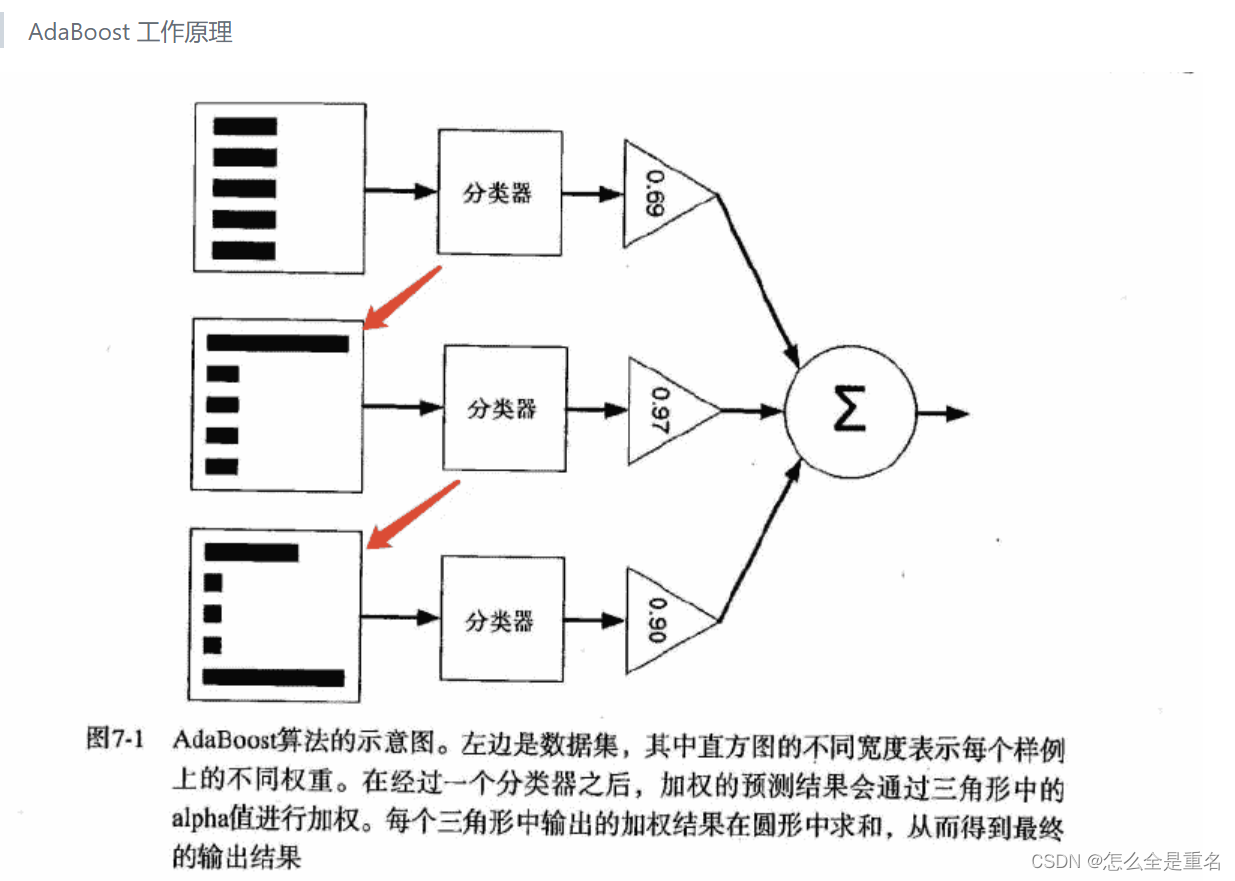
以分类为例,Adaboost算法通过提高前一轮分类器分类错误的样本的权值,而降低那些被分类正确的样本的权值。
需要注意的是,由于每个子模型要使用全部的数据集进行训练,因此 Adaboost算法中没有oob数据集,在使用 Adaboost 算法前,需要划分数据集:train_test_split。
相当于准备个错题本,花更多的时间处理错题
在使用Adaboost与决策树结合解决分类问题时,使用AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
ada_clf = AdaBoostClassifier(DecisionTreeClassifier(max_depth=2), n_estimators=500)
ada_clf.fit(X_train, y_train)
ada_clf.score(X_test, y_test)
同样的简单例子
from sklearn.datasets import load_iris
from sklearn.ensemble import AdaBoostClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 加载鸢尾花数据集
data = load_iris()
X = data.data # 特征
y = data.target # 目标# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建 AdaBoost 分类器(基分类器为决策树)
clf = AdaBoostClassifier(n_estimators=50, random_state=42)# 训练分类器
clf.fit(X_train, y_train)# 使用分类器进行预测
y_pred = clf.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)