中国专业的网站建设营业推广名词解释
提示词工程基础🚀
在了解完了大语模型的基本知识,例如API的使用多轮对话,流式输出,微调,知识向量库等知识之后,接下来需要进一步补足的一个大块就是提示词工程,学习和了解提示词工程除了基本的提示词类型之外,不同的大模型对于提示词工程润色之后的提示词的反应如何,也是比较值得关注的一点,因此本文使用文心一言4.0,通义千问,ChatGPT4, Claude3,四种模型来实验一下各类的提示词。
文章目录
- 提示词工程基础🚀
- 1.什么是提示词工程
- 2.提示词要素
- 3.提示词的通用技巧
- 3.1 在提示词中明确指令
- 3.1.1 输入基础和改进之后的提示词模型的输出
- 3.1.2 结果对比分析
- 3.2 具体描述输出所要的格式
- 3.2.1 输入基础和改进之后的提示词模型的输出
- 3.2.2 结果对比分析
- 3.3精确描述想要的内容不要概括
- 3.3.1 输入基础和改进之后的提示词模型的输出
- 3.3.2 结果对比分析
- 3.4 以鼓励的方式向大模型提问
- 3.4.1 输入基础和改进之后的提示词模型的输出
- 3.4.2 结果对比分析
- 4.整体结果分析
- 结束
https://www.promptingguide.ai/zh
首先分享一个网站这是我在谷歌上搜索到的,一个非常好的提示词学习网站,不但由简单到难的总结了提示词工程中的各种概念要素和提示词的各类技术,后面还包括了一些工具,笔记,还有一些提示词领域的优秀的论文,并不断的对论文进行更新,根据这个网站的逻辑,这篇文章首先测试一下其中的通用提示词技巧,最如果有什么错误或者不完善的非常欢迎沟通交流。
1.什么是提示词工程
这里先引用上面的提示词指南中对提示词工程的介绍:
提示工程(Prompt Engineering)是一门较新的学科,关注提示词开发和优化,帮助用户将大语言模型(Large Language Model, LLM)用于各场景和研究领域。 掌握了提示工程相关技能将有助于用户更好地了解大型语言模型的能力和局限性。
我个人的感觉的话就是针对不同类型的问题然后找出一些通用的提示结构从而让回答的正确率和质量更高。
2.提示词要素
这里我认为提示词指南网站里的解释非常好,我就直接给粘过来,然后补充点自己的理解。
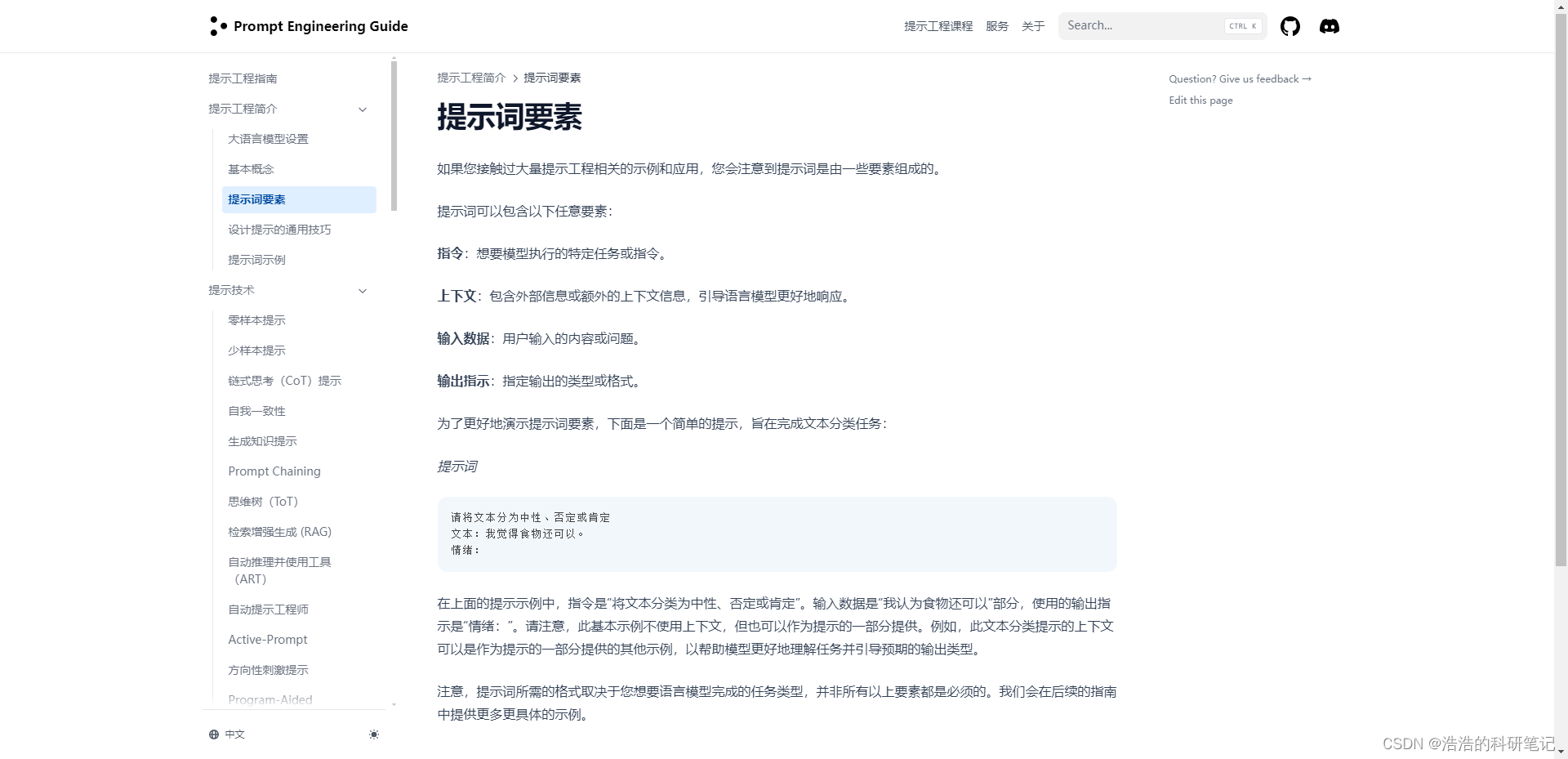
提示词的四要素:
指令:想要模型执行的特定任务或指令。
上下文:包含外部信息或额外的上下文信息,引导语言模型更好地响应。
输入数据:用户输入的内容或问题。
输出指示:指定输出的类型或格式。
一般来说我们在使用大模型的时候,都是直接输入指令和数据,但是如果能有效的提供上下文和输出格式,则一般而言回答的质量会更高。
3.提示词的通用技巧
3.1 在提示词中明确指令
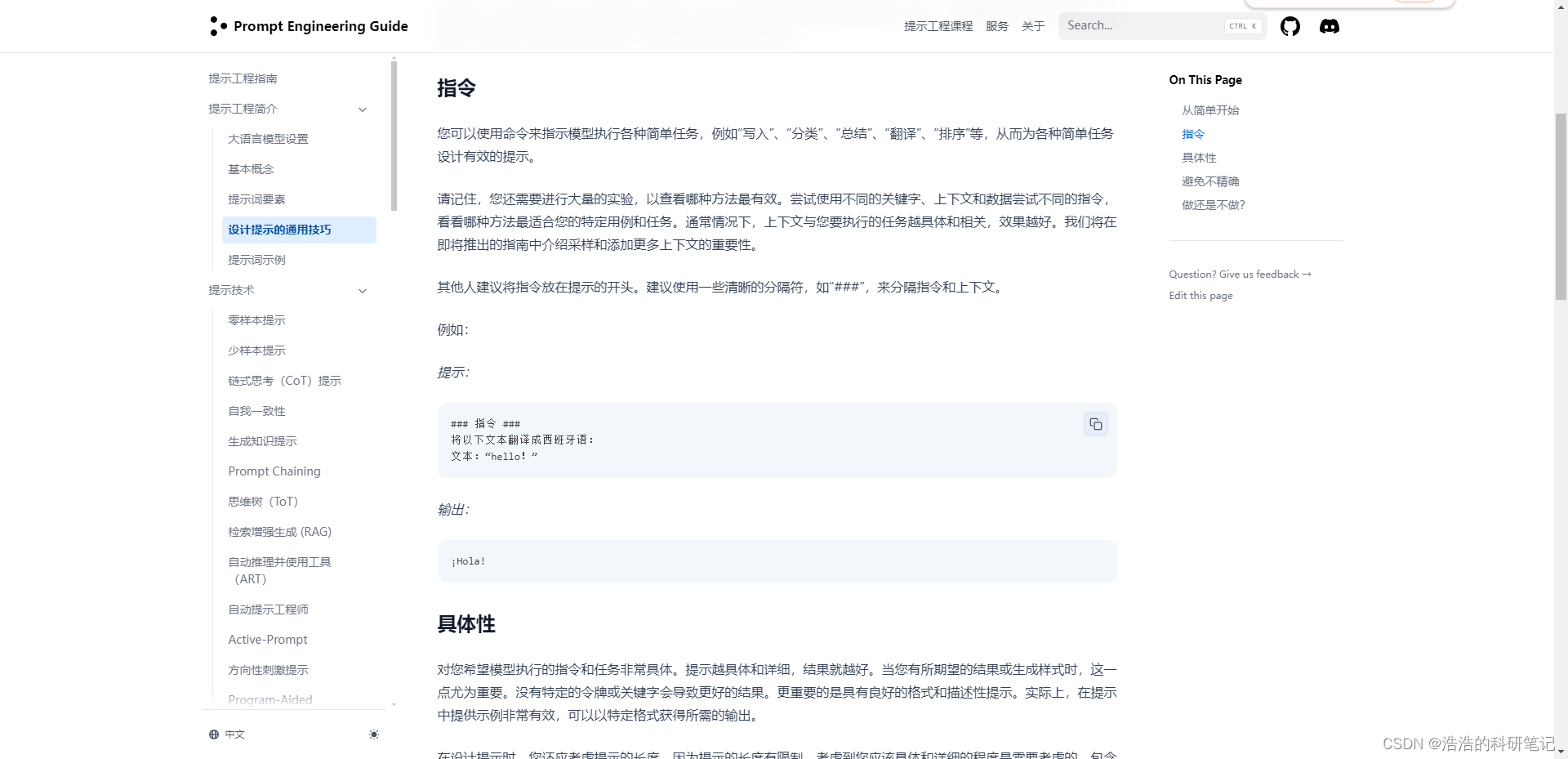
明确指令的过程中的要点如下:
- 使用例如“写入”、“分类”、“总结”、“翻译”、“排序”等明确的提示词
- 将“###指令###”放在开头
接下来我们分别测试三种
将“hello!”翻译成西班牙语
将以下文本翻译成西班牙语:
文本:“hello!”
### 指令 ###
将以下文本翻译成西班牙语:
文本:“hello!”
为了避免多轮对话的记忆,因此每次实验都新开一个会话
3.1.1 输入基础和改进之后的提示词模型的输出












3.1.2 结果对比分析
下面是我自我感受的一个测试结果,纯个人感受,文心一言的基础效果给差是因为,只有文心一言的基础结果输出时候,翻译出的西班牙语少了开头的一个符号(但我不知道重要不重要不太懂西班牙语),剩下的情况翻译的情况都基本是正确的,虽然额外的表示方式或是信息不同。
| 模型名称 | 基础效果 | 使用提示技巧效果 | 特点 | 相关任务推荐建议 |
|---|---|---|---|---|
| 文心一言4.0 | 差 | 良好 | 无 | 不是很推荐 |
| 通义千问 | 良好 | 良好 | 只输出结果 | 需要精简回答时推荐 |
| GPT4 | 良好 | 良好 | 结果前会铺垫一句描述 | 对话场景推荐 |
| Claude3 | 良好 | 良好 | 会自动切换回答语言 | 需自动切换语言时推荐 |
3.2 具体描述输出所要的格式

接下来测试两种文本:
提取以下文本中的地名。
输入:“虽然这些发展对研究人员来说是令人鼓舞的,但仍有许多谜团。里斯本未知的香帕利莫德中心的神经免疫学家 Henrique Veiga-Fernandes 说:“我们经常在大脑和我们在周围看到的效果之间有一个黑匣子。”“如果我们想在治疗背景下使用它,我们实际上需要了解机制。”
提取以下文本中的地名。
所需格式:
地点:<逗号分隔的公司名称列表>
输入:“虽然这些发展对研究人员来说是令人鼓舞的,但仍有许多谜团。里斯本未知的香帕利莫德中心的神经免疫学家 Henrique Veiga-Fernandes 说:“我们经常在大脑和我们在周围看到的效果之间有一个黑匣子。”“如果我们想在治疗背景下使用它,我们实际上需要了解机制。”
3.2.1 输入基础和改进之后的提示词模型的输出








3.2.2 结果对比分析
在通用提示词中明确指令前文测试结果,这里两个地名都识别出来了我认为是正确,然后识别出来一个的我就给了差。然后较好是有时候正确有时候错误我就给了较好。
| 模型名称 | 基础效果 | 使用提示技巧效果 | 特点 | 相关任务推荐建议 |
|---|---|---|---|---|
| 文心一言4.0 | 差 | 差 | 无 | 不是很推荐 |
| 通义千问 | 良好 | 较好 | 不改进提示词前正确,改进有时正确有时错误 | 推荐不改进提示词使用 |
| GPT4 | 差 | 差 | 无 | 不是很推荐 |
| Claude3 | 差 | 良好 | 不改进之前错误,改进之后正确 | 推荐改进提示词之后使用 |
3.3精确描述想要的内容不要概括

向高中学生解释提示工程的概念。
使用 2-3 句话向高中学生解释提示工程的概念。
3.3.1 输入基础和改进之后的提示词模型的输出








3.3.2 结果对比分析
然后由于这是一个开放性问题没有正确答案,大家总结的也都不错但是有个明显的区别。
- 国内的两个模型文心一言和通义千文把提示工程认为是一种提示作用的行为然后讲述出来
- 国外的两个模型把提示工程认为提示工程是大模型中的提示词工程而进行输出描述。
我个人认为在这方面国外的两个模型的表现要更好或者更符合当前科技背景一些。
3.4 以鼓励的方式向大模型提问

测试的两个文本如下
以下是向客户推荐电影的代理程序。不要询问兴趣。不要询问个人信息。客户:请根据我的兴趣推荐电影。
代理:
以下是向客户推荐电影的代理程序。代理负责从全球热门电影中推荐电影。它应该避免询问用户的偏好并避免询问个人信息。如果代理没有电影推荐,它应该回答“抱歉,今天找不到电影推荐。”
顾客:请根据我的兴趣推荐一部电影。
客服:
3.4.1 输入基础和改进之后的提示词模型的输出








3.4.2 结果对比分析
这里除了GPT4,其他模型都没有完成拒绝推荐的指令,因此GPT在理解复杂指令方面还是表现出了领先的优势。
4.整体结果分析
- 随着大模型的发展,提示词工程的通用技巧之后的模型绝大多数情况下都好于改善了之前,但也有更差的情况,个人认为随着大模型的发展,提示词工程的作用在不断的降低。如果把上述四种提示词基础功能分别对应四种任务的话我粗略的给每个模型排个名仅供参考。
| 模型名称 | 明确指令任务 | 中实体识别任务 | 精确内容任务 | 附加条件任务 | 综合排名(求和) |
|---|---|---|---|---|---|
| 文心一言4.0 | 4 | 3 | 3 | 2 | 4 |
| 通义千问 | 1 | 1 | 3 | 2 | 3 |
| GPT4 | 1 | 3 | 1 | 1 | 1 |
| Claude3 | 1 | 2 | 1 | 2 | 1 |
- GPT在中文实体识别任务中不如通义千问和Claude3其他任务中全处在最优水平,而且在理解复杂逻辑方面遥遥领先
- Claude各方面能力相当均衡没有明显的短板
- 国产模型在整体能力上距离世界领先水平还有一段空间,加油我们自己大模型一定会越来越好。
结束
这个对比就到这,毕竟花了好多钱开了这这些大模型,争取把能测试都测试一遍,后面从零样本提示开始做实验,进一步看一下各个模型在面对复杂情况下表现和提示词能起到的作用。