傻瓜式建站软件下载做外贸网站教程
数据库系统(Database System,DBS)由硬件和软件共同构成。硬件主要用于存储数据库中的数据,包括计算机、存储设备等。软件部分主要包括数据库管理系统、支持数据库管理系统运行的操作系统,以及支持多种语言进行应用开发的访问技术等。
数据库系统是指在计算机系统中引入数据库后的系统。完整的数据库系统结构关系如图所示:
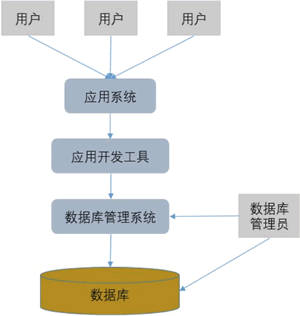
由图可知,一个完整的数据库系统一般由数据库、数据库管理系统、应用开发工具、应用系统、数据库管理员和用户组成。
数据库系统主要有以下 3 个组成部分:
- 数据库:用于存储数据的地方。
- 数据库管理系统:用于管理数据库的软件。
- 数据库应用程序:为了提高数据库系统的处理能力所使用的管理数据库库的软件补充。
数据库(DataBase,DB)提供了一个存储空间来存储各种数据,可以将数据库视为一个存储数据的容器。一个数据库可能包含许多文件,一个数据库系统中通常包含许多数据库。
数据库管理系统(Database Management System,DBMS)是用户创建、管理和维护数据库时所使用的软件,位于用户和操作系统之间,对数据库进行统一管理。DBMS 能定义数据存储结构,提供数据的操作机制,维护数据库的安全性、完整性和可靠性。
虽然已经有了 DBMS,但是在很多情况下,DBMS 无法满足对数据管理的要求。
数据库应用程序(DataBase Application)的使用可以满足对数据管理的更高要求,还可以使数据管理过程更加直观和友好。数据库应用程序负责与 DBMS 进行通信、访问和管理 DBMS 中存储的数据,允许用户插入、修改、删除数据库中的数据。
下面再简单介绍一下 DBMS 提供的一些功能,主要包括以下几个方面。
1) 数据定义功能
DBMS 提供数据定义语言(Data Definition Language,DDL),用户通过它可以方便地对数据库中的数据对象进行定义。
2) 数据操纵功能
DBMS 还提供数据操纵语言(Data Manipulation Language,DML),用户可以使用 DML 操作数据,实现对数据库的基本操作,如查询、插入、删除和修改等。
3) 数据库的运行管理
数据库在建立、运用和维护时由数据库管理系统统一管理、统一控制,以保证数据的安全性、完整性、多用户对数据的并发使用及发生故障后的系统恢复。例如:
- 数据的完整性检查功能保证用户输入的数据应满足相应的约束条件;
- 数据库的安全保护功能保证只有赋予权限的用户才能访问数据库中的数据;
- 数据库的并发控制功能使多个用户可以在同一时刻并发地访问数据库的数据;
- 数据库系统的故障恢复功能使数据库运行出现故障时可以进行数据库恢复,以保证数据库可靠地运行。
4) 提供方便、有效地存取数据库信息的接口和工具
编程人员可通过编程语言与数据库之间的接口进行数据库应用程序的开发。数据库管理员(Database Administrator,DBA)可通过提供的工具对数据库进行管理。
数据库管理员是维护和管理数据库的专门人员。
5) 数据库的建立和维护功能
数据库功能包括数据库初始数据的输入、转换功能,数据库的转储、恢复功能,数据库的重组织功能和性能监控、分析功能等。这些功能通常由一些使用程序来完成。