自己做网站外包电力建设网站
广播风暴(broadcast storm)简单的讲是指当广播数据充斥网络无法处理,并占用大量网络带宽,导致正常业务不能运行,甚至彻底瘫痪,这就发生了“广播风暴”。一个数据帧或包被传输到本地网段 (由广播域定义)上的每个节点就是广播;由于网络拓扑的设计和连接问题,或其他原因导致广播在网段内大量复制,传播数据帧,导致网络性能下降,甚至网络瘫痪,这就是广播风暴。
首先,广播风暴的产生有两种可能性:
1、不合理的网络划分。比如很多客户机处于同一个网段内。由于ARP、DHCP都是广播包的形式,那么有时候就会产生广播风暴。
2、环路。环路时,数据包会不断的重复传输,也一样会产生广播风暴。
这两者中,环路的情况比较恶性,需要网管人员立即进行排除;而网段划分引起的广播风暴比较良性,一般对网络的影响较小。
二层广播风暴产生原因

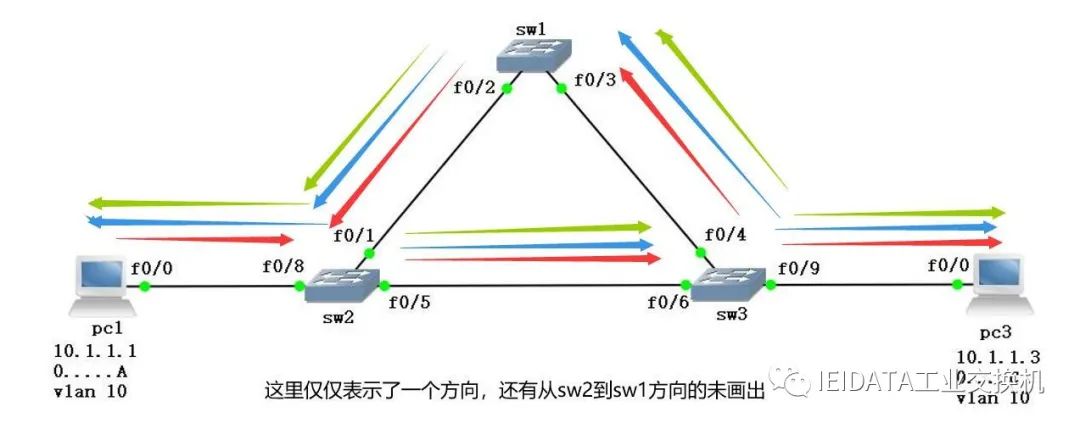
注:这里只讨论一个方向
首先pc1发送arp请求到达sw2以后形成一个交换机的mac地址表

从f0/8接口学习到的mac地址)0........A, 属于vlan 10
然后在判断Dmac,当Dmac为12个F时,然后在自己所有vlan 10 的接口内(除了F0/8)以及trunk链路接口泛洪
同样sw3收到来自sw2的arp也形成一个mac地址表:

然后泛洪给 pc3 和 sw1
!!!***注:在到达pc3以前dmac都是12个F(二层广播)
到达sw1以后形成一个交换机的mac地址表

然后sw1又接着泛洪给sw2,形成一个交换机的mac地址表

!!!***注:此时dmac都是12个F(二层广播)
由于在 sw2 时 dmac 为12个F,所以接着泛红给 sw3,然后 sw3 泛洪给 pc3 和 sw1,然后 sw1 又泛洪给 sw2.....................这样来回往复,最终形成二层广播风暴
二层广播风暴图解:
危害:
广播风暴对网络的危害是非常大的,将严重消耗设备资源及网络带宽,cpu利用率过高......最终导致网络瘫痪........
如何判断当前是否出现了二层广播风暴:
1、成片区域上网特别卡(延迟时间100-300ms) PC通过console线登录到交换机,通过命令行的方式发现交换机的CPU利用率特别 高(95%-100%)
2、查看MAC地址表,出现了MAC地址偏移的现象(一个相同的 MAC地址在不同的接口学习到)如图:
转存失败重新上传取消
3、查看 0/8 和 0/1接口的速率统计,从设备开机到现在,接口一共收到了多少 广播包,一分钟,再看这个接口收到了多少广播包,看一分钟之内增加了多少广播 包,成百上千的话肯定是产生了二层广播风暴
4、查看机房交换机接口的状态灯,正常情况下是绿色且定期的闪烁(有流量在传 输),如果说其中有一个接口呈黄色且快速闪烁,很难判断 但如果是所有的接口呈黄色且快速闪烁,基本上可以判断产生了二层广播风暴
二层广播风暴产生的一般原因,除了不合理的网络划分和环路,还有以下几种:
1、网络设备原因:我们经常会有这样一个误区,交换机是点对点转发,不会产生广播风暴。在我们购买网络设置时,购买的交换机,通常是智能型的Hub,却被奸商当做交换机来卖。这样,在网络稍微繁忙的时候,肯定会产生广播风暴了。
2、网卡损坏:如果网络机器的网卡损坏,也同样会产生广播风暴。损坏的网卡,不停向交换机发送大量的数据包,产生了大量无用的数据包,产生了广播风暴。由于网卡物理损坏引起的广播风暴,故障比较难排除,由于损坏的网卡一般还能上网,我们一般借用Sniffer局域网管理软件,查看网络数据流量,来判断故障点的位置。
3、网络病毒:目前,一些比较流行的网络病毒,Funlove、震荡波、RPC等病毒,一旦有机器中毒后,会立即通过网络进行传播。网络病毒的传播,就会损耗大量的网络带宽,引起网络堵塞,引起广播风暴。
4、黑客软件的使用:目前,一些上网者,经常利用网络执法官、网络剪刀手等***软件,对网吧的内部网络进行***,由于这些软件的使用,网络也可能会引起广播风暴。
如何解决这个问题:
在面对网络广播风暴发生时,要冷静分析广播风暴产生的原因,可运用排除法、替换法和网线插拔法等多种方法综合运用,一步一步地进行故障排除,快速定位引发广播风暴的故障点,查出引发广播风暴的原因,及时采取相应措施来消灭广播风暴。总的来看,要解决广播风暴的问题,可以从以下几个方面入手:
1、在局域网中安装WSUS补丁服务器,保证局域网所有计算机都能及时打上最新的补丁。
2、最好在局域网内安装网络版的防毒服务器,如无条件这,起码也得保证单机版的防毒软件的病毒库是经常更新的。
3、检查每一台计算机的网卡、网线和交换机的每一个端口,检查是否有故障。
4、当广播风暴发生时,观察交换机的指示灯不啻为很好的方法,可直接观察网络连通性及网络流量。
要避免广播风暴,可以采用恰当划分VLAN、缩小广播域、隔离广播风暴,还可在千兆以太网口上启用广播风暴控制,最大限度地避免网络再次陷入瘫痪。当端 口接受到大量的广播、单播或组播的包时,就会发生广播风暴。转发这些包会导致网络速度变慢或超时,在交换机上借助对端口的广播风暴控制可以有效避免硬件损 坏或链路故障导致的广播风暴的网络瘫痪。
从海翎光电小编的实际经验来看,90%以上的网络广播风暴是病毒所致,因此,要加强网络 病毒的防治,加强对网络线路运行状态的监控,及时发现和处理网络上的异常流量和病毒***等问题,并制定计算机安全管理制度,确保网络线路的正常运行。