网站的运营和维护行业平台网站开发
没有 API,应用之间的通信将会被扼杀;软件开发者将不断重写并执行相同功能的软件;创新的脚步将会放缓。
API 随处可见。大到一个软件系统,小到几行程序,只要具备了一定的特征,都可以被称作 API。那么,什么是 API?它有哪些特征呢?
API 的定义
(封装好的)、可以实现特定功能的、可供其它模块调用的程序就叫做 API。API 的形象化表示如图 1 所示。
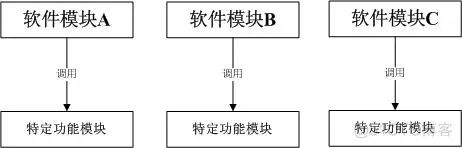
图 1 API 的形象化表示
1 所示,“特定功能模块” 可以被 “软件模块 A”、“软件模块 B” 和 “软件模块 C” 调用,那么该 “特定功能模块” 就是一个 API。
电商 API 接口:企业级数据 电商 API 接口
API 的特征
API,它有可能被很多的模块调用,其主要特征包括:
第一,其实现的功能具备通用性,很多的软件模块都涉及到该功能。
第二,其功能具备稳定性,已经过了严格的测试。
第三,其执行效率较高,已经过一定的优化。
API 的实例
/**********************************************************************
*功能描述:将字符串中的大写字母变为小写字母
*输入参数: *pszInStr-输入/输出字符串iInLen-字符串长度
*输出参数: *pszInStr-输入/输出字符串
*返 回 值: 0-成功 -1-失败
*其它说明: 无
*修改日期 版本号 修改人 修改内容
* ---------------------------------------------------------------------
* 20150330 V1.0 Zhou Zhaoxiong 创建
***********************************************************************/
INT32 StrToLowerCase(UINT8 *pszInStr, UINT32 iInLen)
{UINT32 iLoopFlag = 0;if (pszInStr == NULL) // 判断输入字符串是否为空{printf("StrToLowerCase: Input string is NULL!");return -1; // 返回-1表示该函数执行失败}for (iLoopFlag = 0; iLoopFlag < iInLen; iLoopFlag ++){pszInStr[iLoopFlag] = tolower(pszInStr[iLoopFlag]);}return 0; // 返回0表示该函数执行成功
}
API 来使用。当软件程序中涉及到需要将大写字母变为小写字母时,都可以直接调用该函数而不需重新编写。