阿里买域名 电脑做网站门户网站管理系统
目录
一、引言
二、界面设计:简洁大方,操作便捷
三、功能评测:全面升级,满足多样需求
四、性能评测:稳定流畅,高效运行
五、总结与展望
ONLYOFFICE官网链接:ONLYOFFICE - 企业在线办公应用软件 | ONLYOFFICE
ONLYOFFICE 8.1版本桌面编辑器测评:卓越性能,引领办公新潮流
随着数字化办公的普及,一款高效、便捷的办公软件成为了每个职场人士不可或缺的助手。近期,ONLYOFFICE发布了备受瞩目的8.1版本桌面编辑器,以其卓越的性能和丰富的功能,再次引领了办公软件的新潮流。本文将为您带来ONLYOFFICE 8.1版本桌面编辑器的详细测评,并附带相关图片,让您全方位了解这款办公软件的魅力。
一、引言
ONLYOFFICE作为一款开源的办公软件套件,自诞生以来就凭借其强大的功能和稳定的性能赢得了广大用户的青睐。随着技术的不断迭代和更新,ONLYOFFICE 8.1版本桌面编辑器应运而生,为用户带来了更加出色的办公体验。接下来,我们将从界面设计、功能评测、性能评测等多个方面,为您揭示ONLYOFFICE 8.1版本桌面编辑器的魅力。
二、界面设计:简洁大方,操作便捷
ONLYOFFICE 8.1版本桌面编辑器的界面设计简洁大方,符合现代审美趋势。软件采用了直观的图标和菜单布局,使用户能够轻松上手。同时,软件还支持自定义界面主题和字体大小,满足不同用户的个性化需求。在界面细节方面,ONLYOFFICE 8.1版本也做得非常出色,如滚动条、工具栏等元素的设计都显得非常精致。
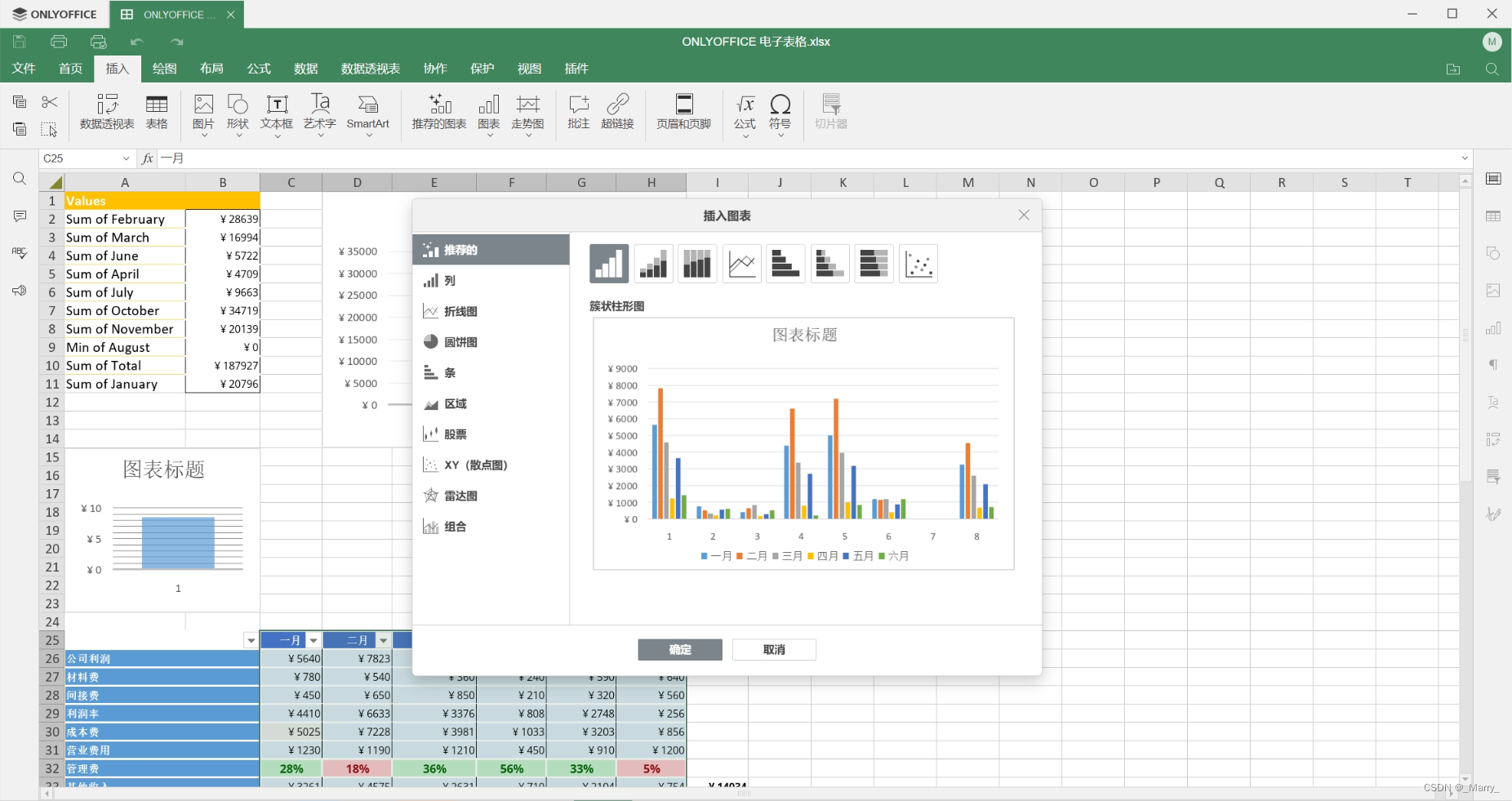
界面整体布局清晰,工具栏位于顶部,包含了常用的文件操作、编辑、视图等功能按钮。左侧是文档的结构视图,可以方便地查看和导航文档的各个部分。中央区域是文档的编辑区域,用户可以在这里输入文字、插入图片、表格等元素。右侧是样式和格式设置的面板,用户可以在这里快速调整文档的格式和样式。整个界面设计简洁大方,色彩搭配舒适,为用户提供了良好的视觉体验。
三、功能评测:全面升级,满足多样需求
-
文字处理功能:
ONLYOFFICE 8.1版本的文字处理功能十分强大,支持多种文本格式导入导出,如DOC、DOCX、ODT等。在文本编辑方面,软件提供了丰富的排版工具和样式设置选项,如字体、字号、颜色、段落格式等。此外,软件还支持多种插入元素,如图片、表格、超链接等,使得文档内容更加丰富多样。在协作方面,ONLYOFFICE 8.1版本支持实时多人协作编辑,用户可以轻松与他人共享和编辑文档。

-
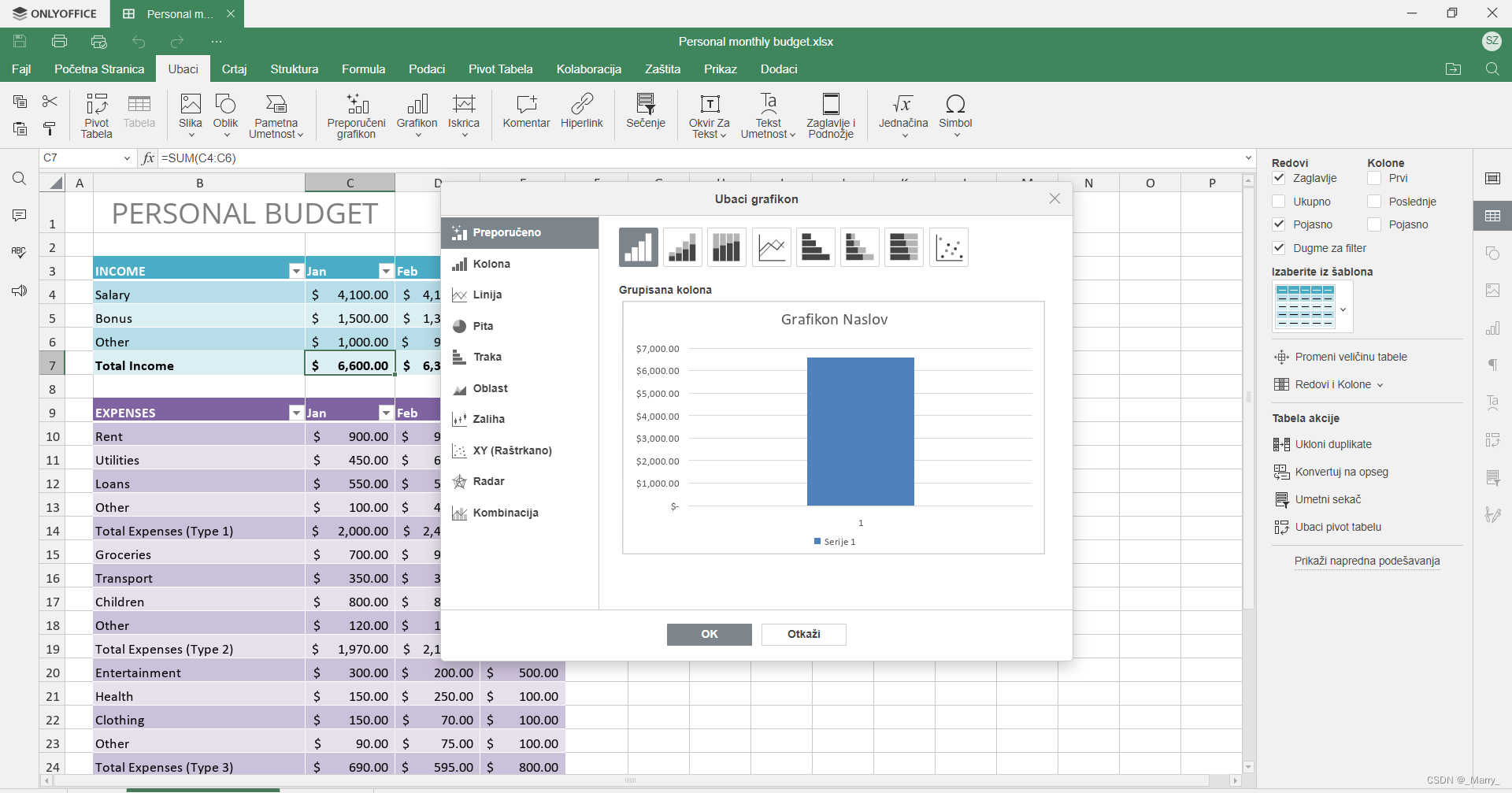
表格编辑功能:
ONLYOFFICE 8.1版本的表格编辑功能同样出色。软件支持多种表格格式导入导出,如XLS、XLSX、CSV等。在表格编辑方面,软件提供了丰富的函数和公式支持,用户可以轻松进行数据处理和分析。同时,软件还支持多种图表类型,如柱状图、折线图、饼图等,帮助用户更好地展示数据。在协作方面,ONLYOFFICE 8.1版本同样支持实时多人协作编辑表格。
-
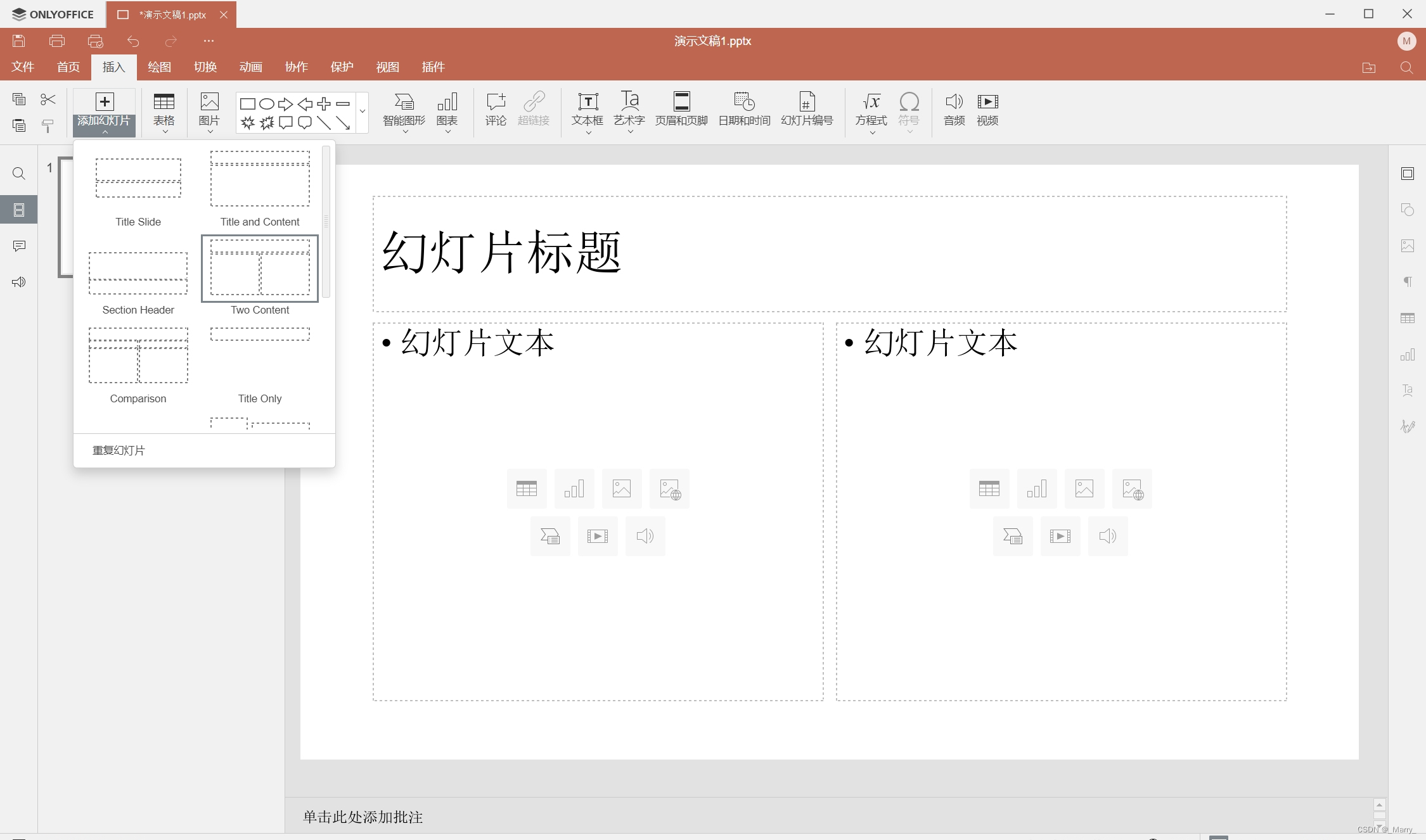
演示文稿功能:
ONLYOFFICE 8.1版本的演示文稿功能也非常强大。软件支持多种演示文稿格式导入导出,如PPT、PPTX、ODP等。在演示文稿编辑方面,软件提供了丰富的幻灯片布局和动画效果设置选项,使得演示文稿更加生动有趣。同时,软件还支持多种媒体元素插入,如音频、视频等,丰富演示内容。在协作方面,ONLYOFFICE 8.1版本同样支持实时多人协作编辑演示文稿。
四、性能评测:稳定流畅,高效运行
在性能方面,ONLYOFFICE 8.1版本桌面编辑器表现优秀。软件启动速度快,响应迅速,即使在处理大型文档或复杂表格时也能保持流畅的运行状态。此外,软件还具备出色的稳定性和兼容性,能够在不同操作系统和硬件环境下稳定运行。在安全性方面,ONLYOFFICE 8.1版本也做得非常出色,采用了多种安全措施保护用户数据安全。

五、总结与展望
通过本次测评可以看出,ONLYOFFICE 8.1版本桌面编辑器在界面设计、功能评测和性能评测等方面均表现出色。作为一款开源的办公软件套件,ONLYOFFICE 8.1版本不仅具备强大的功能和稳定的性能,还注重用户体验和安全性。未来,随着技术的不断进步和用户需求的不断变化,ONLYOFFICE将继续努力完善产品功能和提升用户体验,为用户带来更加优质的办公体验。
让我们共同期待ONLYOFFICE在办公软件领域的更多精彩表现!