建筑网建设通网站作用成都网络运营外包
前言
大家好,我是艾老虎尤,我在一篇官方的文章中,我了解到了markdown,原本我写博客一直是使用的富文本编译器,之前我也有同学叫我使用MD,但是我嫌它复杂,就比如说一个标题,我在富文本编译器上直接选中就行,使用MD的话还要在前面加#,不过现在看来,MD的使用并没有那么复杂,简单到常用的语法操作不超过十个,以至于我写下这篇博客,记录和分享自己的学习,这也是我第一次使用markdown编写博客。


一、什么是markdown?
一开始我也不知道什么是markdown,我也去互联网上搜索了相关信息,简单来 说,就是原本是一个程序员偷懒而创作的,如今却火遍全球,普吉到大众,它可以 让你抛弃鼠标,全程使用键盘完成标题,加粗,斜体,表格等功能,给你行 云流水般的写作体验。
2004年,一名叫做约翰·格鲁伯的小伙正在编写自己的的博客,那时候的博客都需要博主使用HTML语言来编写,即使是一段简单的加粗操作,也需要一串代码完成。
例如:
| HTML写法 | Markdown写法 |
|---|---|
<strong>粗体<strong> | **这是粗体** |
约翰显然对这种方式非常不满,他决定自己发明一种语言,一种易于阅读、易于撰写的纯文本语言——Markdown,使用markdown,你可以仅用符号进行文本编译,并自动转换成HTML语言,简单来讲,就是偷懒,他找来了18岁天才少年,亚纶·斯沃茨一起设计,3月,约翰开始公开测试markdown,8月发布了markdown1.0,十二月更新到1.0.1,再然后他就不再更新了,是的,markdown之父对markdown的维护到此为止,但后面他还会出场,此后几年,越来越多的人开始使用markdown,其人群也不再局限于程序员,任何热衷于文本写作的人都可以使用markdown,而markdown却一直没有一个统一的语法标准,直到2012年,几个程序员大牛在一起开了个会,决定统一markdown的语法标准,比如左右各一个表示斜体,左右各两个表示粗体等等,并将这个标准取名为Standard Markdown,这时候markdown之父约翰突然表示反对这个名字,原因很简单,一群人撇开自己这个原作者制定了一个规范,并把它成为标准,我不要面子吗?因此,最终Standard Markdown改名为Commonmark,并且越发普及。
二、Markdown优点
- 直接创建,没啥限制和要求。
- 排版简单,可读、直观、学习成本低。
- 支持插入图片,视频等等(根据平台不同而定)。
- 轻松的导出 HTML、.md 文件。
- 可跨平台同步数据。
- 随时可修改(不必像word等易混乱)。
…
三、Markdown基础语法
3.1 标题
在文本中插入空行即可生成段落,使得文章更加清晰易读,构建文档结构是编写内容时的首要任务。Markdown通过使用
#符号表示不同级别的标题,例如。
例如:
#一级标题
##二级标题
####三级标题
####四级标题
#####五级标题
######六级标题
效果:

注意:#和标题之间要有一个空格隔开,否则无法识别。
另外,上述操作还支持快捷键,我们以CSDN为例,Ctrl+Ahift+H
3.2 文本样式
为了突出文本的重要性,Markdown提供了多种强调方式。通过使用
*或_包裹文本,你可以设置文字为斜体或粗体。同时,有序列表和无序列表的标记使得表达逻辑关系和项目清单变得直观而简单,例如:
| 样式 | 写法 | 效果 |
|---|---|---|
| 加粗 | **加粗** | 加粗 |
| 加粗 | __加粗__ | 加粗 |
| 粗斜体 | ***粗斜体*** | 粗斜体 |
| 粗斜体 | ___粗斜体___ | 粗斜体 |
| 斜体 | *斜体* | 斜体 |
| 斜体 | _斜体_ | 斜体 |
| 标记文本 | ==标记文本== | 标记文本 |
| 删除文本 | ~~删除文本~~ |
注意:所有的语法都是英文状态下输入的。
| 快捷键 | 效果 |
|---|---|
| Ctrl+B | 加粗 |
| Ctrl+i | 斜体 |
3.2 列表
列表分为有序列表和无序列表
-
有序列表:使用
数字+.再加一个空格作为列表标记; -
无序列表:使用
*或者+或者-再加一个空格作为列表标记;
如下:
1. 列表 1
2. 列表 2
3. 列表 3* 列表1
* 列表2
* 列表3
效果:
-
列表 1
-
列表 2
-
列表 3
- 列表1
- 列表2
- 列表3
如果要控制列表的层级,则需要在符号 - 前使用 tab,如下:
- 无序列表 1
- 无序列表 2
- 无序列表 2.1
- 无序列表 2.2
3.3 图片
为了突出文本的重要性,Markdown提供了多种强调方式。通过使用
*或_包裹文本,你可以设置文字为斜体或粗体。同时,有序列表和无序列表的标记使得表达逻辑关系和项目清单变得直观而简单,例如:
图片的表述是这样的,也可以选择文件插入图片,但是我个人还是比较喜欢Ctrl+V,谁能拒绝Ctrl+V呢?

3.4 链接
想增加链接,有两种方法,第一种是
[]+(),[]里面是链接的名称,可以自定义,要注意的是这个格式规定的就是两个符号在一起,不能只写一个,第二种是<>,里面直接粘贴地址就行。
[链接名称](链接地址)
<链接地址>
效果:
这里是艾老虎尤的主页
https://blog.csdn.net/qq_69611919?type=blog
3.5 代码块
这里有两种格式,这里不好展示,我们直接看效果
第一种//```
第二种三个·`加上javascript
第一种效果:#include<stdio.h>
第二种效果:#include<stdio.h>
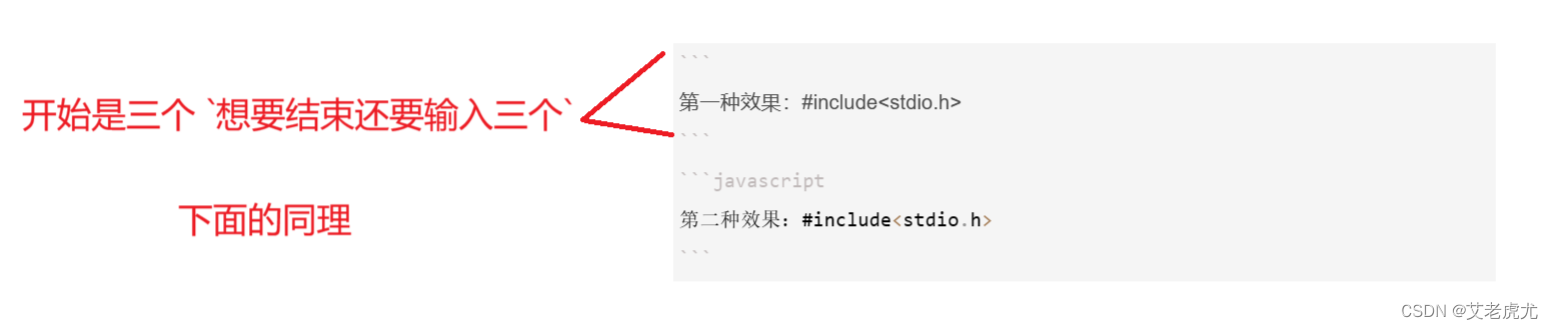
三个反引号后面什么都不输入的话,代码段是白色的,三个反引号后面可以写入代码的语言,例如C,C++,Java等,代码段就变成黑色的。
3.5 表格
表格使用|来分割不同的单元格,使用-来分隔表头和其他行,例如上面3.2,文本样式的表格,是以这样的格式打印出来的。

- :-:将表头及单元格内容左对齐
- -::将表头及单元格内容右对齐
- :-::将表头及单元格内容居中
如果直接写–的话,默认是剧中对齐。
代码:
|:-|:-:|-:|
|左对齐| 居中| 右对齐|
效果:
| :- | :-: | -: |
|---|---|---|
| 左对齐 | 居中 | 右对齐 |
在博客或技术文档中,表格通常扮演着关键的角色。Markdown的表格功能不仅可以用来呈现基本数据,还支持合并单元格、添加表头等高级功能。以下是一个示例:
| 姓名 | 评价 |
| ---- | ---------------------- |
| 张三 | :star::star::star: |
| 李四 | :star::star::star::star: |
效果
| 姓名 | 评价 |
|---|---|
| 张三 | ⭐️⭐️⭐️ |
| 李四 | ⭐️⭐️⭐️⭐️ |
3.6 脚注
脚注是对文本的备注,即对文本的补充说明,方便我们更好的理解,我们时长在论文中看到脚注,在Markdown中的使用方法。
脚注的格式是
[^1],然后在使用[^1]:对脚注进行解释,如果想写第二个脚注,只需要把[^1]该成[^2]即可。
代码格式:
一个具有注脚的文本。[^1][^1]: 注脚的解释
注意:脚注自动被搬运到最后面,请到文章末尾查看,并且脚注后方的链接可以直接跳转回到对应脚注的地方。
3.9 引用
引用的格式是在符号>后面书写文字,或者加一个空格再加文字,如下:
>这是一个引用
引用效果:
这是一个引用
引用也是可以嵌套定义的,如下:
>这是一个引用
>>这是一个引用
>>>这是一个引用
嵌套应用效果
这是一个引用
这是一个引用
这是一个引用
3.10 分割线
Markdown中给出了多种分割线的样式,我们可以使用分割线让文章结构更加的清晰。
分割线的使用,可以在一行中用三个-或者*来建立一个分割线.
但是注意:在分割线的上面空一行!!!
---
***
分割效果:
3.11 特殊符号
对于Markdown中的语法符号,前面加反斜线\即可以显示符号本身。
代码:
\\
\*
\_
\+
\.
等等
效果展示
\
*
_
+
.
等等
3.12 制作待办事项
这里的语法一点更要注意,先是-+空格+[ ]+空格+名称
[]里面必须要有x或者空格
- [ ] 计划1
- [x] 完成2
效果展示
- 计划1
- 完成2
四、总结
当代数字化世界中,内容的表达和分享已经变得前所未有的重要。Markdown作为一种轻量级的标记语言,以其简洁、易读易写的特性。
掌握Markdown,创作与分享更便捷
在信息传递日益多样化的今天,Markdown已经成为了内容创作者和写作爱好者的得力助手。通过使用简洁明了的符号,Markdown使得文本的格式化变得毫不费力。通过掌握Markdown的基础语法,你可以更专注于内容创作,而不用担心繁琐的排版问题。
标题,段落,和列表:构建清晰的结构
Markdown让构建文档结构变得轻而易举。通过在文本前加上不同数量的#,你可以轻松创建多级标题,使得阅读更加有层次感。段落则通过简单的空行分隔,而无需繁琐的HTML标签。而有序列表和无序列表的标记使得表达逻辑关系和项目清单变得直观而简单。
强调与链接:增强内容表达
为了突出文本的重要性,Markdown提供了强调和加粗的方式。通过使用*或_包裹文本,你可以为文字增加斜体或粗体效果。而插入链接也是轻而易举的,使用方括号包裹链接文本,紧跟着括号内输入链接地址,即可创建超链接,将读者引导到更多相关信息。
插入图片,引用和代码:丰富多彩的内容
博客内容不仅可以是纯文本,Markdown还支持插入图片、引用和代码块。通过,你可以嵌入图片,使得文章更具视觉吸引力。引用他人观点则变得容易,只需在文本前加上>符号。而通过使用反引号,你可以在文章中展示代码片段,让技术内容更加清晰明了。
表格与分割线:整理信息,优化布局
在介绍复杂数据或制作清晰布局时,Markdown的表格功能是无可替代的。通过|和-的组合,你可以轻松绘制表格,将信息整齐地展示出来。另外,插入分割线可以在内容之间划出清晰的界限,使得文章结构更加整洁。
开启高效创作之旅
Markdown语法的简洁和功能的强大,使得它成为创作者们的首选工具之一。通过你的博客,我们了解到了Markdown基础语法的精髓,它能够让我们在内容创作中事半功倍。无论是写作博客、撰写文档还是与他人分享信息,Markdown都将成为你高效创作的得力助手。让我们拥抱Markdown,以它为笔,创作出更加优雅、精彩的内容吧!