网页与网站的区别与联系网易企业邮箱怎么绑定
1、MC协议帧
MC协议可以在串口通信,也可以在以太网通信,有A-1E和Qna-3E两种模式,这两种都是三菱PLC通信协议中比较常用的两种,一般我们使用比较多的是以太网通信,对于FX5U系列/Q系列/Qna系列/L系列的PLC,通常会使用QnA兼容3E帧,对于FX3U系列,我们需要加以太网模块,采用A兼容1E帧。
A-1E是三菱PLC通信协议中最早的一种,它是一种基于二进制通信协议的协议,适用于三菱FX系列PLC和A系列PLC。该协议支持点对点通信和多点通信,可以实现PLC之间的数据交换和远程监控等功能。
Qna-3E模式是三菱PLC通信协议中较新的一种,它是一种基于ASCII码通信协议的协议,适用于三菱Q系列PLC和FX5U系列PLC。该协议支持点对点通信和多点通信,可以实现PLC之间的数据交换、远程监控和远程编程等功能。
2、A-1E协议介绍
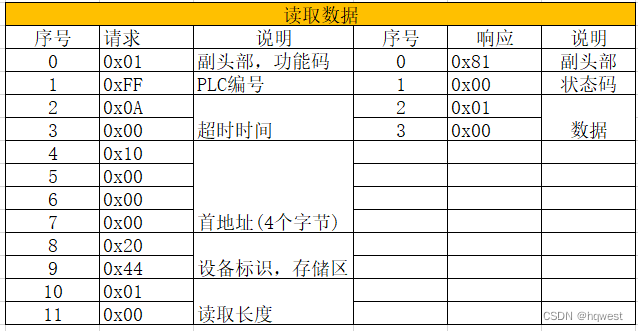
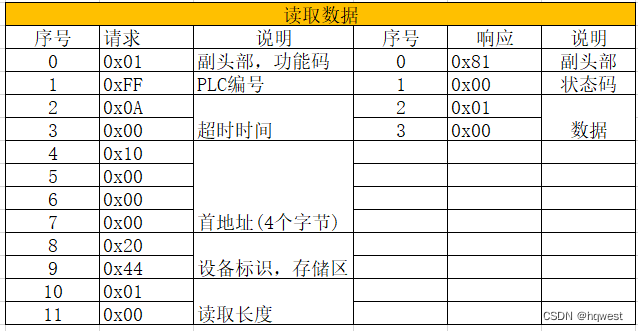
1、读取数据的报文结构
可以看到读取数据发送12个字节,响应4个字节,各个字节的意义如下(0x表示16进制),注意响应并不一定是4个字节,如果读取长度不是一个,则响应肯定大于4个字节,具体看后面的实例操作,总之结构就是如下表示:
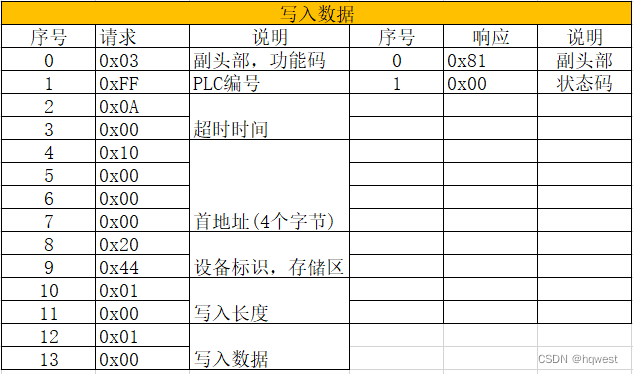
2、写入数据的报文结构
可以看到写入数据发送14个字节,响应2个字节,各个字节的意义如下(0x表示16进制),注意请求不一定是14个字节,如果写入的长度不止一个长度,则报文字节肯定大于14,总之报文结构如下:
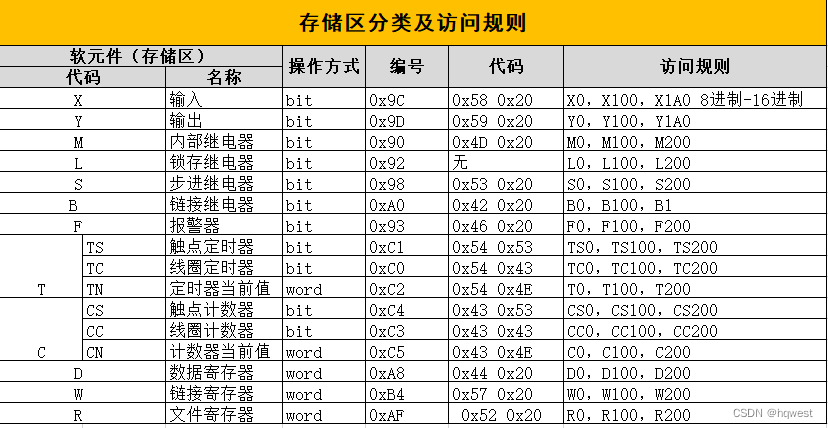
3、软元件分类及访问规则
注意这个操作方式中的bit和word,bit就是一个位,二进制中的位bit,0或1算一个位,word叫字,一个字就16位,就是2个字节,一个字节是8位,2个字节就是16位,也就是16个bit,在C#中就是2个ascii码,比如01就是2个字节,就是一个word,简单讲就是word占2个字节,另外0X是16进制的表示。
4、命令类型(功能码,副头部)
上述不管是读取还是写入的请求报文中,第一个字节是功能码,也就是指命令类型,A-1E的命令类型具体如下:
0x00 批量位读取
0x01 批量字读取
0x02 批量位写入
0x03 批量字写入
0x04 随机位写入
0x05 随机字写入
注意响应报文中的状态码00表示正常
3、模拟器介绍
这里我们介绍两个模拟器,所讲的模拟器就是一个三菱的MC服务器,也就是说是一台虚拟的PLC,如果没有模拟器,那就需要一台真实的PLC硬件,但是FX5U之类的PLC价格要好几K以上,屌丝者成本较大,承担不起,对于很多学习者,培训者,爱好者花大洋有些心疼,所以提供2个模拟器,这个模拟器就是一台真实的PLC设备。
1、HslCommunicationDemo-v11.8.1
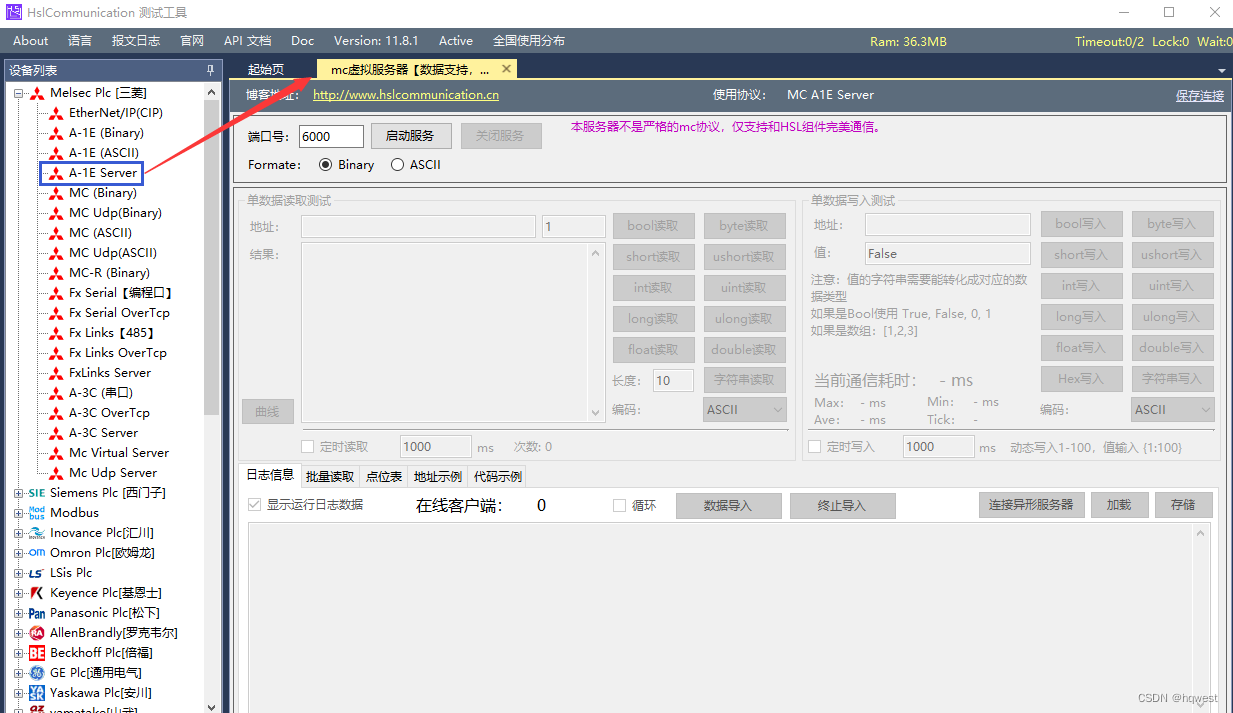
这个是一个强大的工业通信工具,在业界有很高的知名度,具体信息看这个地址( http://www.hslcommunication.cn/):
胡工科技
胡工科技
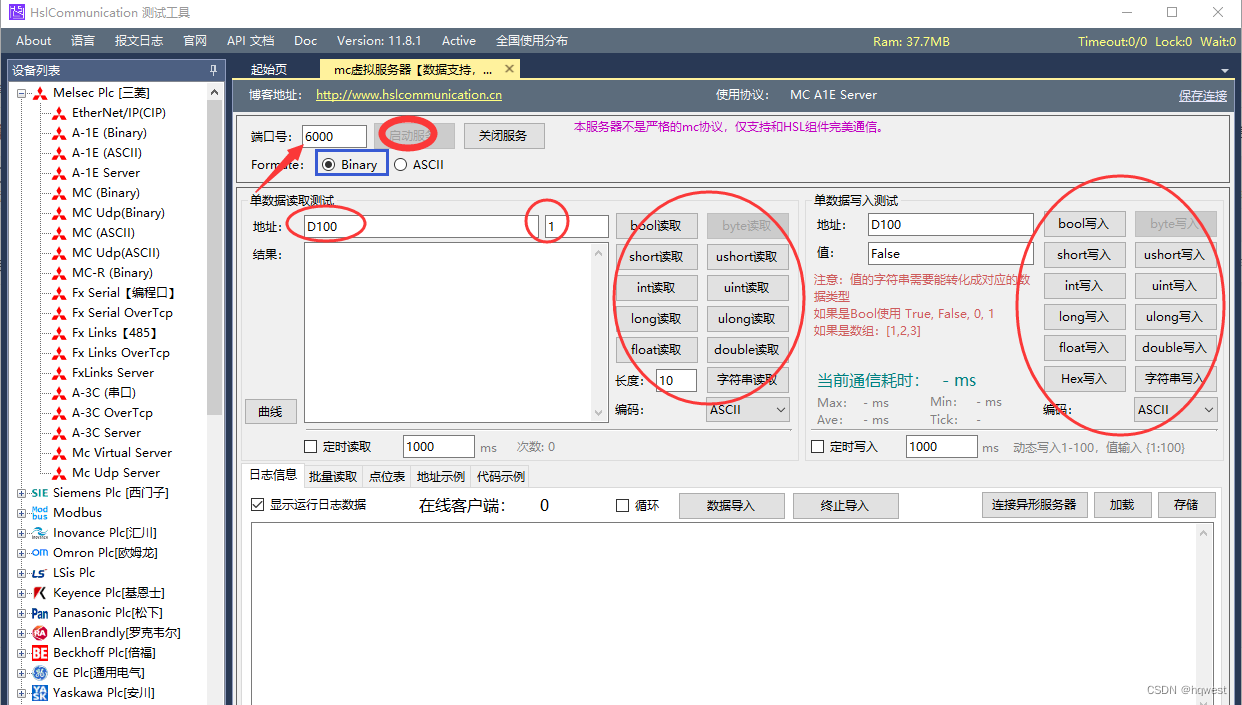
2、本人自研的模拟器,自定Logo,飞常屌,帅逼列
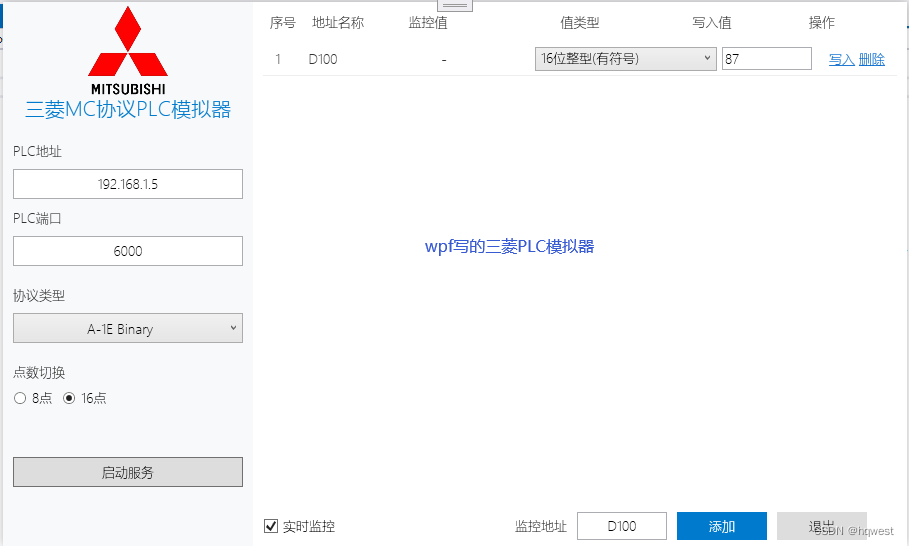
3、为什么要模拟器?
上面介绍的2个模拟器与三菱gx work3自带的gx simulator3的模拟器有什么不同?
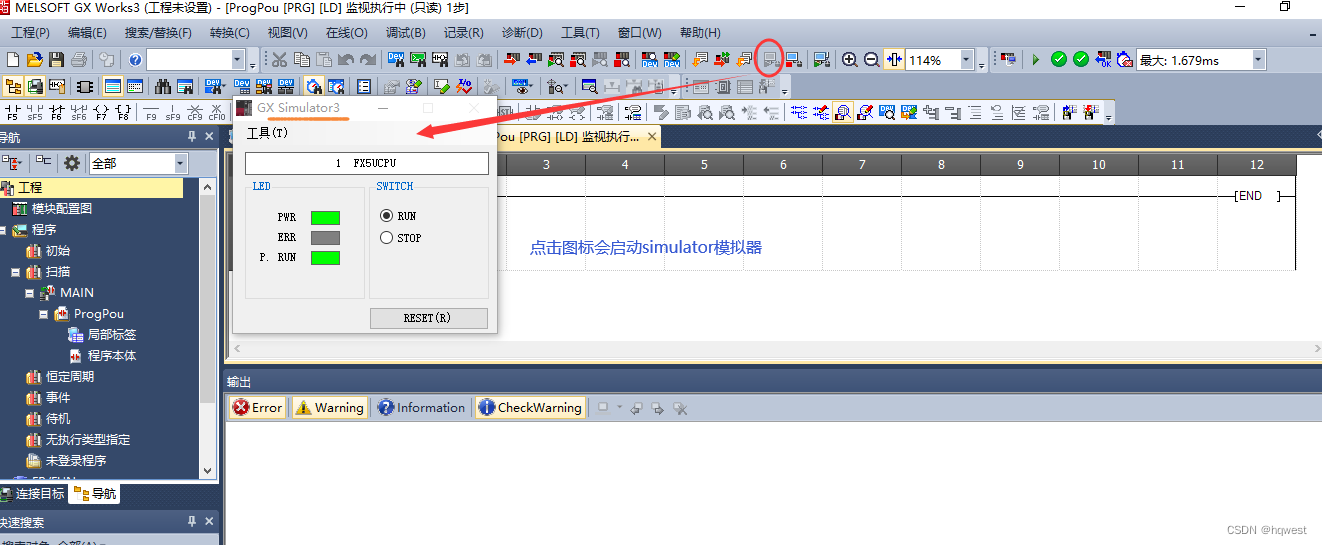
simulator3是模拟运行PLC程序的,它没有提供任何外界接口供外部应用程序调用,串口也好,网口也好,都没有,也就是说外部的应用程序,java,C#,python等无法与simulator3通讯,你写一个通信程序是无法与simulator3通信,从而无法读取和写入Plc程序,当然如果你有真家伙,那是例外,所以上面的2个模拟器就是真实的虚拟PLC硬件,小伙伴们,能明白这个意思吗?
4、你有真家伙,设备PLC的TCP参数方法如下
1、下载 GX Works3
这个过程在前面的文章已介绍过。
C#上位机与三菱PLC的通信01--搭建仿真环境
2、新建工程,选择自己的 PLC 型号,这里用的是 FX5U 系列
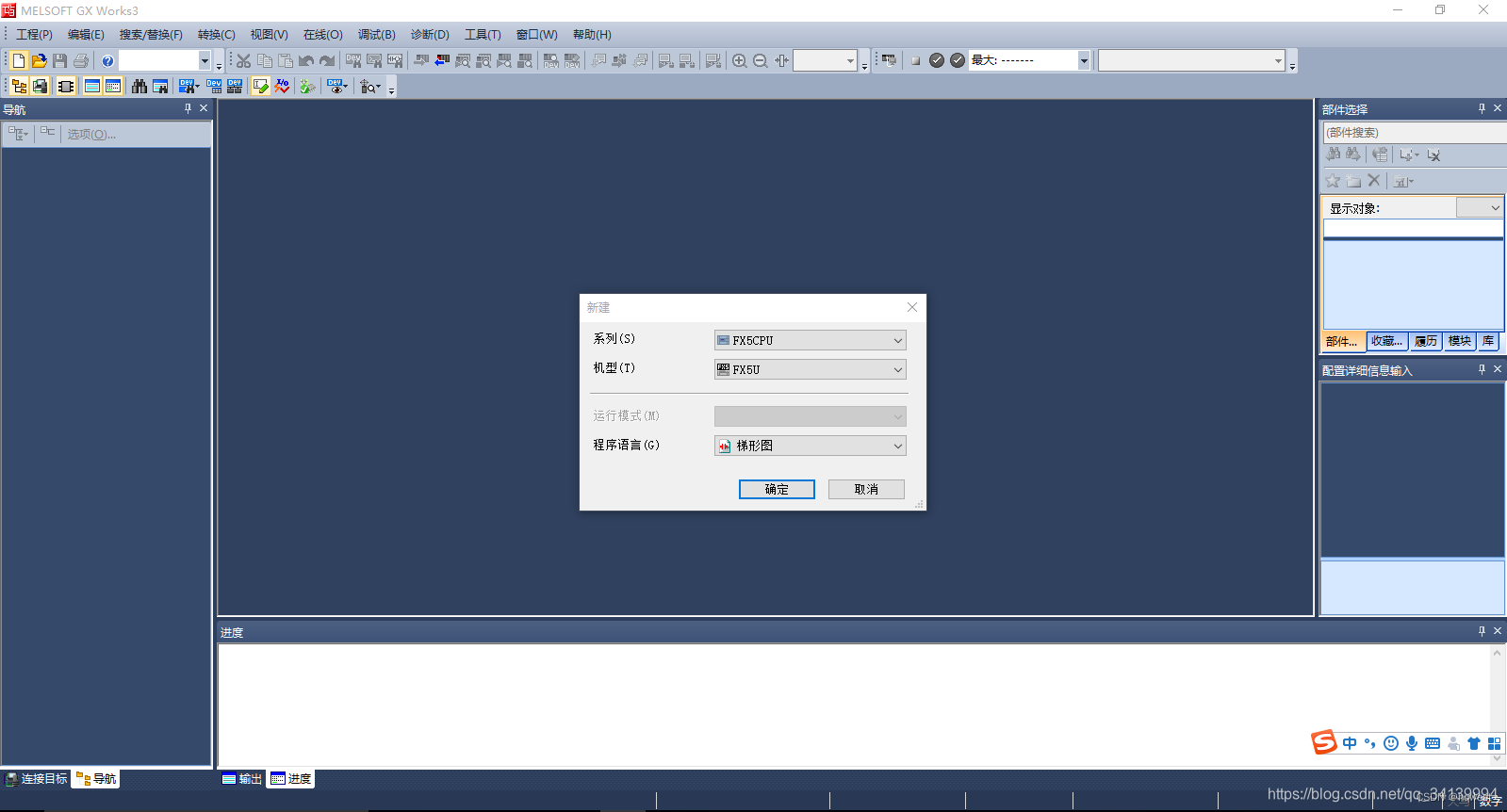
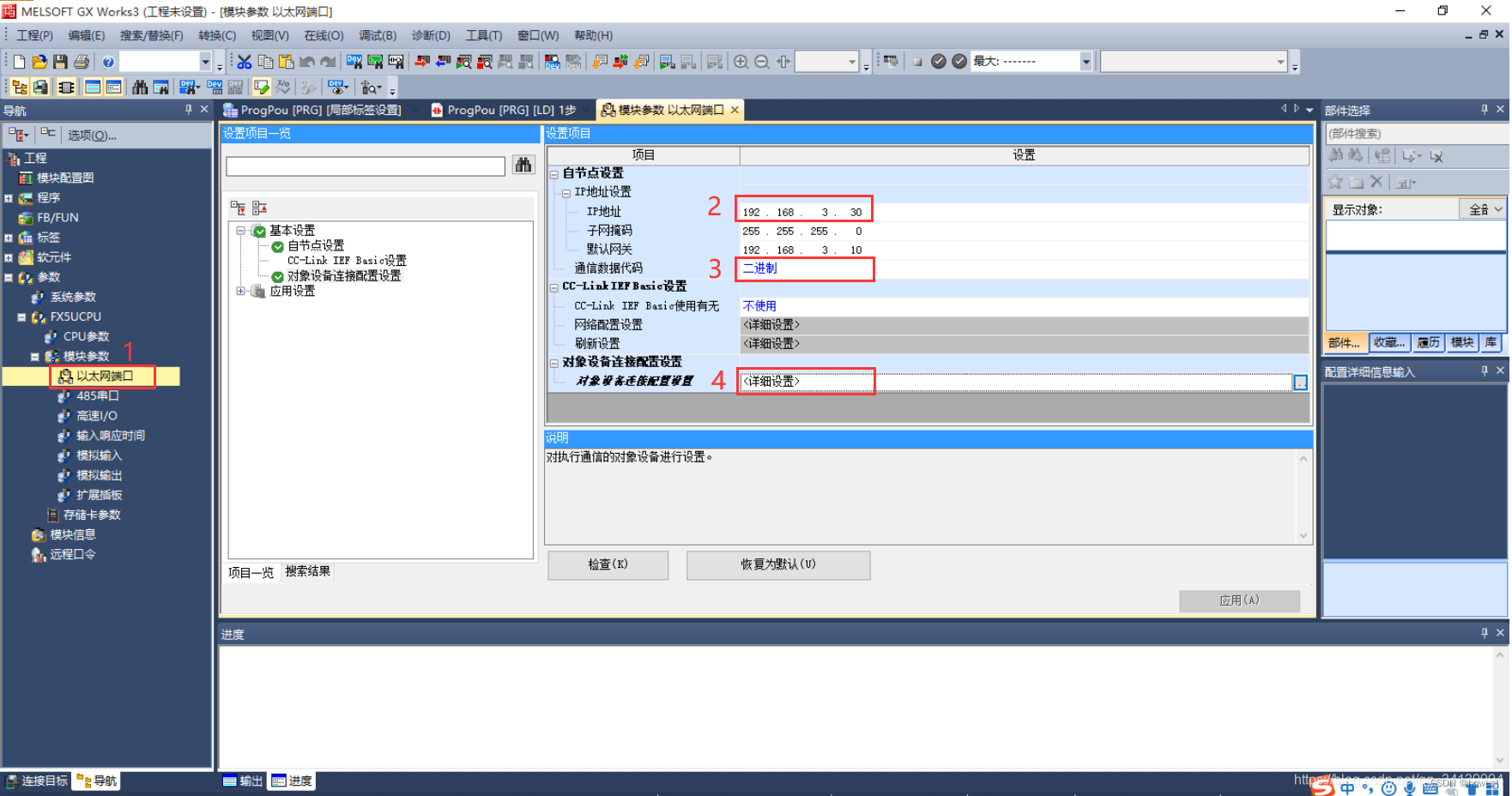
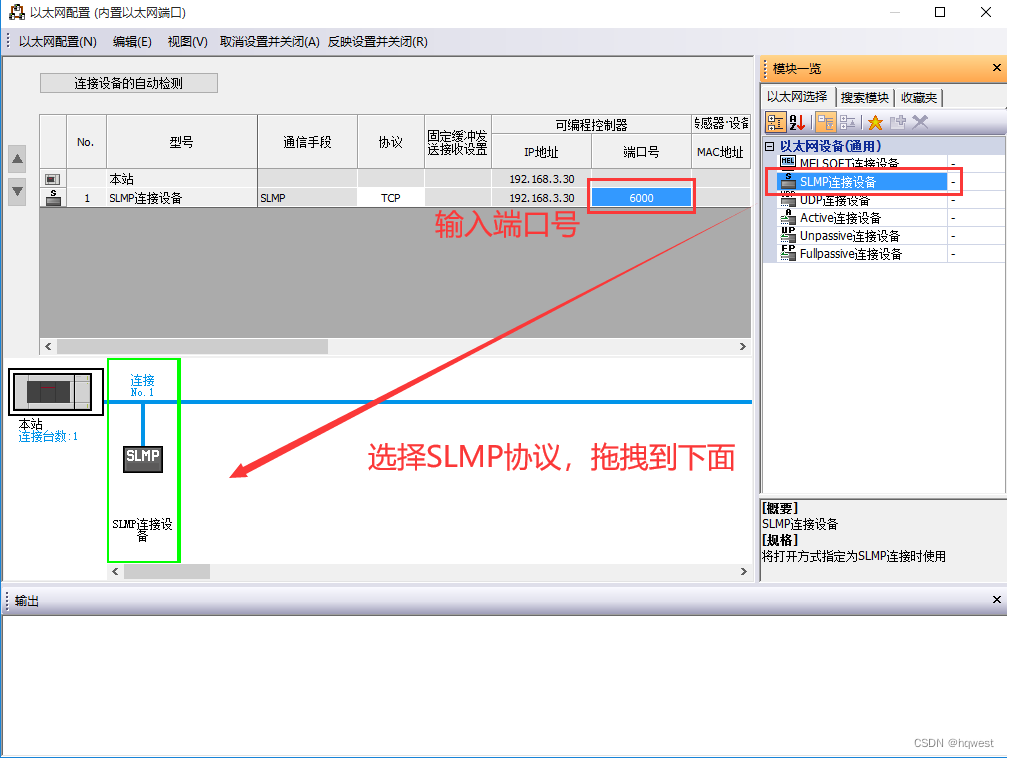
3、设置 PLC 以太网端口
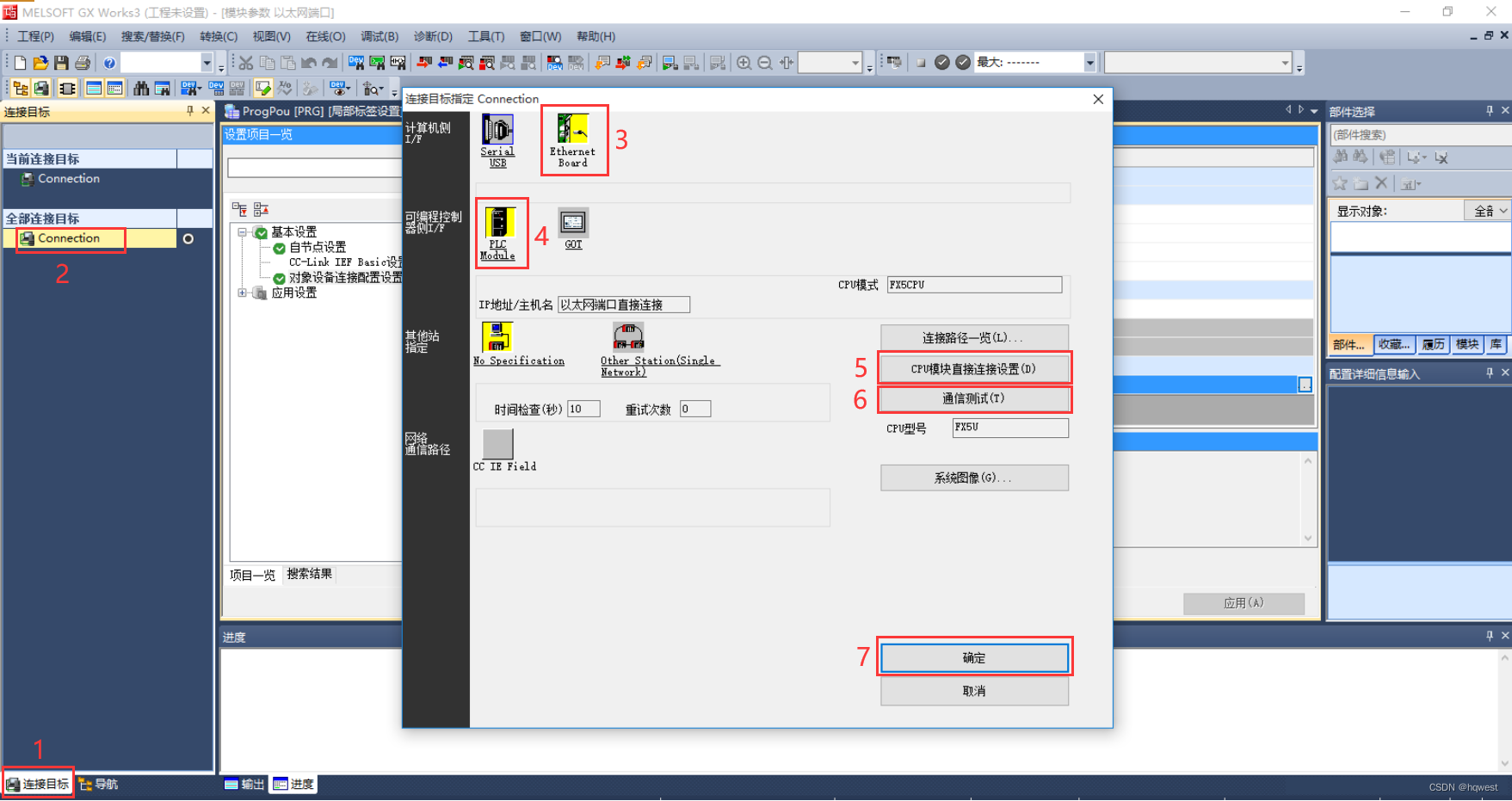
4、测试plcl连接
5、把配置写入 PLC
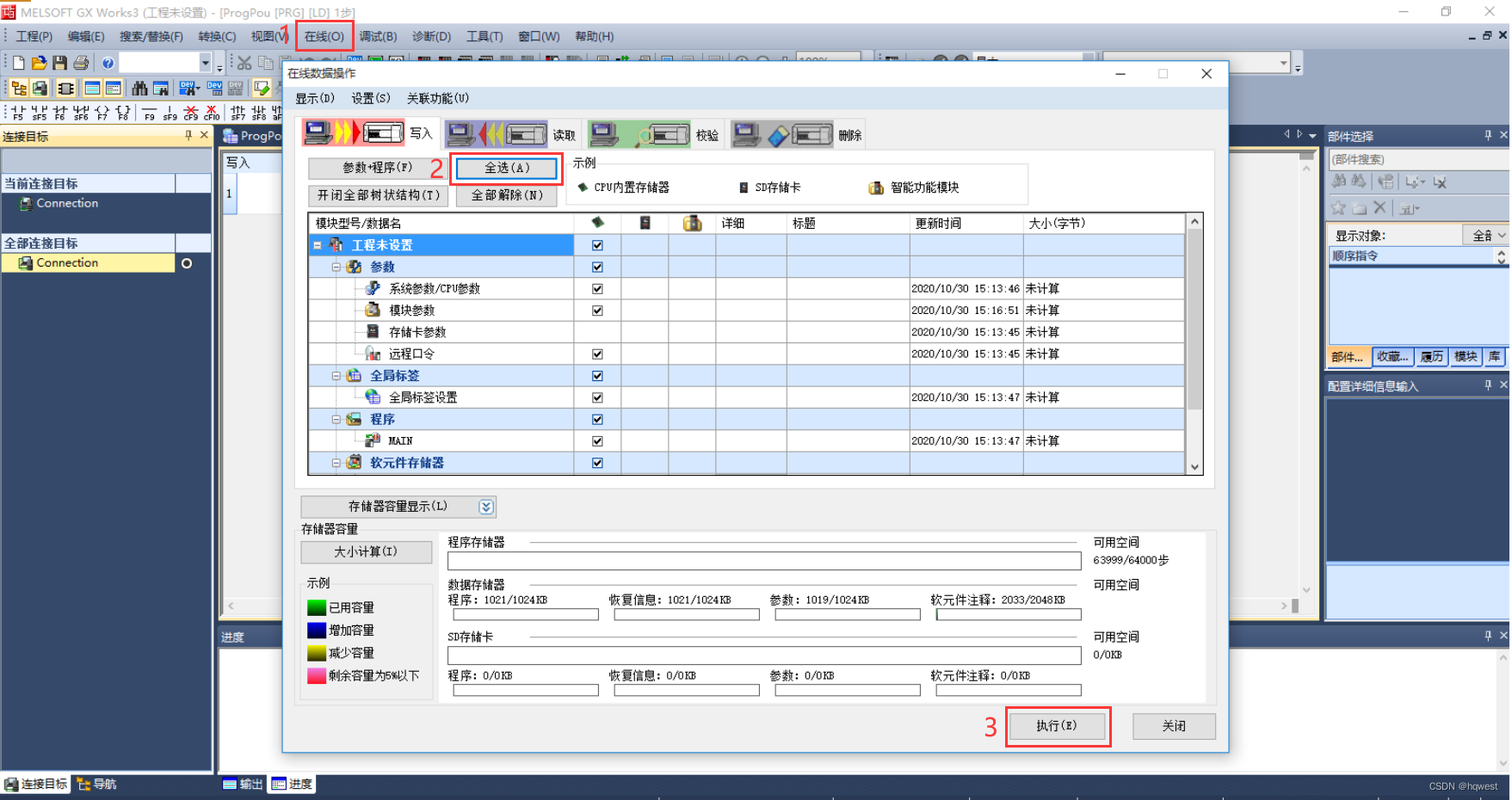
跳出弹窗,全部选择 “是”,写入完成之后需要给 PLC 断电重启
4、工具软件
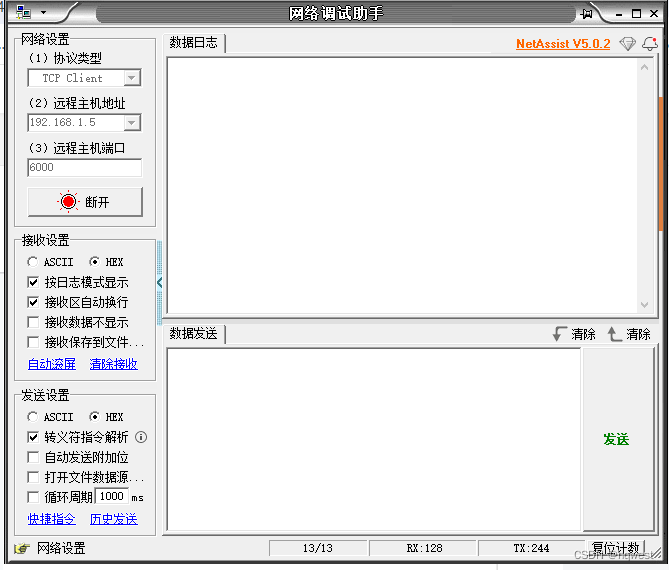
因为是需要发送tcp的报文,无论是A-1E还是Qna-3E,它们都是网络报文,需要TCP网络通信,所以这个工具软件就是发送和接收报文,从而达到分析报文的目的。这个远程主机地址就是Plc的IP地址,远程主机端口就是PLC的端口,PLC作为TCP服务器,工具软件作为TCP客户端。
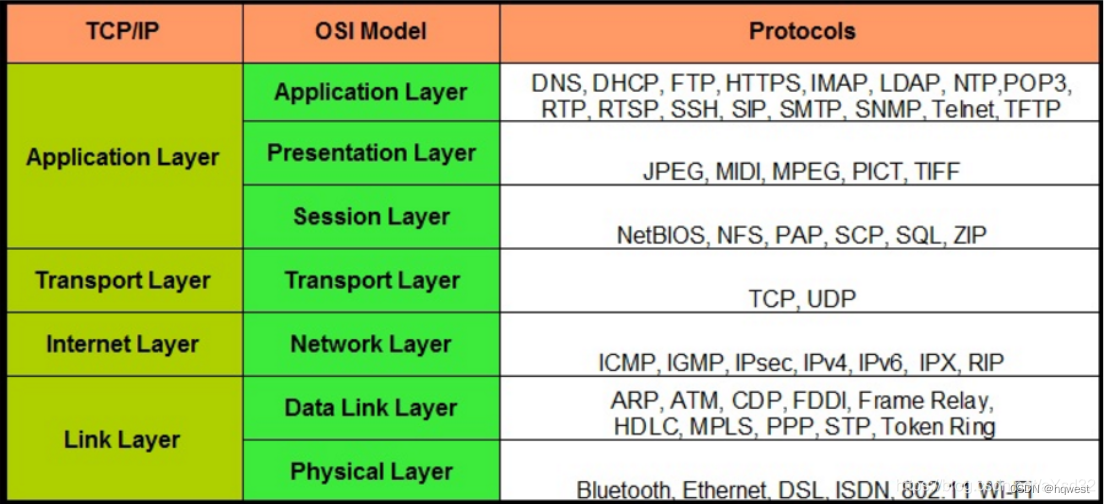
TCP面向连接,提供可靠交付,有流量控制、拥塞控制,面向字节流(从上层传下的数据进行分割,分割成合适运输的数据块)只能是一对一连接。
3、A-1E报文解析
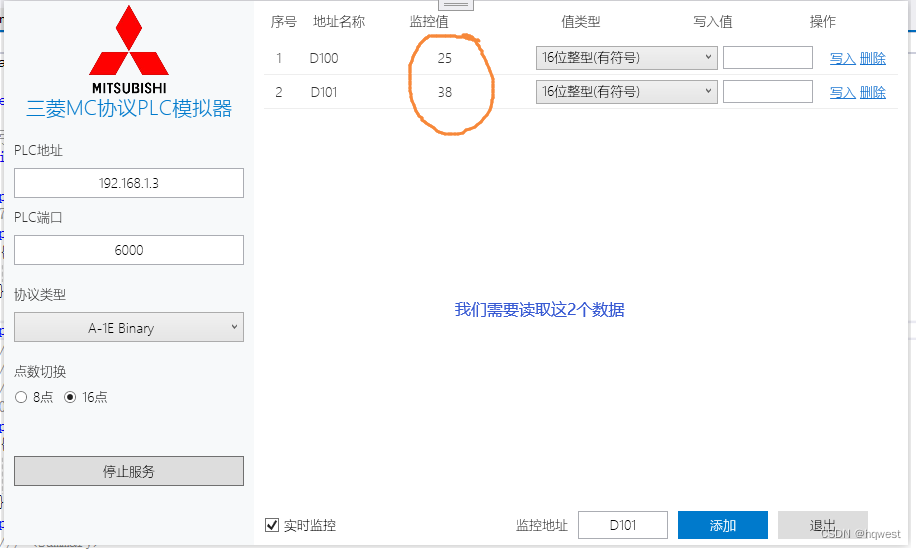
1、读取D100地址开始的2个int类型数据
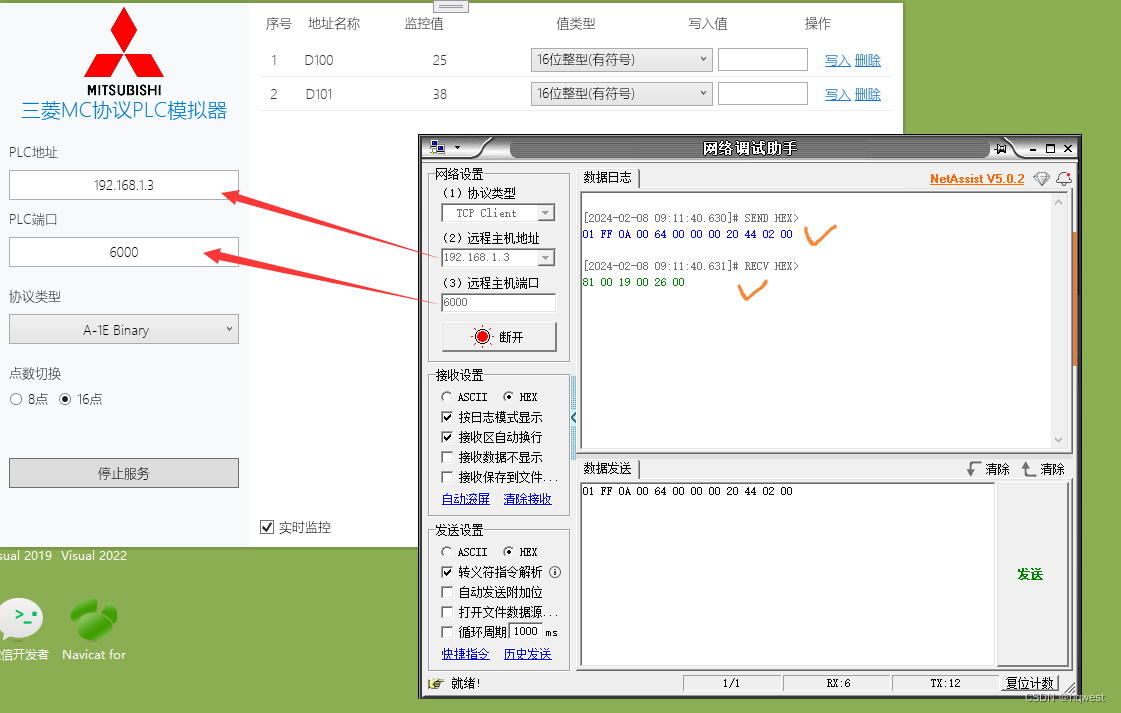
发送:01 FF 0A 00 64 00 00 00 20 44 02 00,占12个字节
01:副头部,也叫功能码,也叫命令类型(0x00 批量位读取、0x01 批量字读取、0x02 批量位写入、0x03 批量字写入、0x04 随机位写入、0x05 随机字写入)
FF:PLC编号
0A 00:超时时间,超时时间是以单位:250ms。
64 00 00 00:地址占4个字节,要读取的地址是100,换成16进制就是64,那为什么是64 00 00 00,这里需要掌握什么是小端处理,小端是三菱的数据设置方式,也有其他PLC是大端处理,大端与小端格式是什么意思,自行百度消化,小端的意思是低位放前面,高位放后面,64用4个字节来表示的话就是00 00 00 64,按小端处理的要求就是前后倒置,所以是64 00 00 00
20 44:存储区,查前面的表就是44 20,同样按小端处理,高位放后面,低位放前面,就变成了20 44。
02 00:读取2个数据,长度是2,长度占2个字节,所以是00 02,按小端处理要求就是02 00
响应:81 00 19 00 26 00 ,占6个字节
81:副头部
00:状态码,表示正常
19 00:要将1900变成0019,为什么了?刚才说了是小端处理,那么得到的数据19是低位,00是高位,所以是0019,即19,它换成10进制就是25。
26 00 :同样2600就是38 。
与实际数据一致,读取成功。

2、 通过A1E进行D102的双字 DWord(Float) 读取,即读取float类型--4Byte
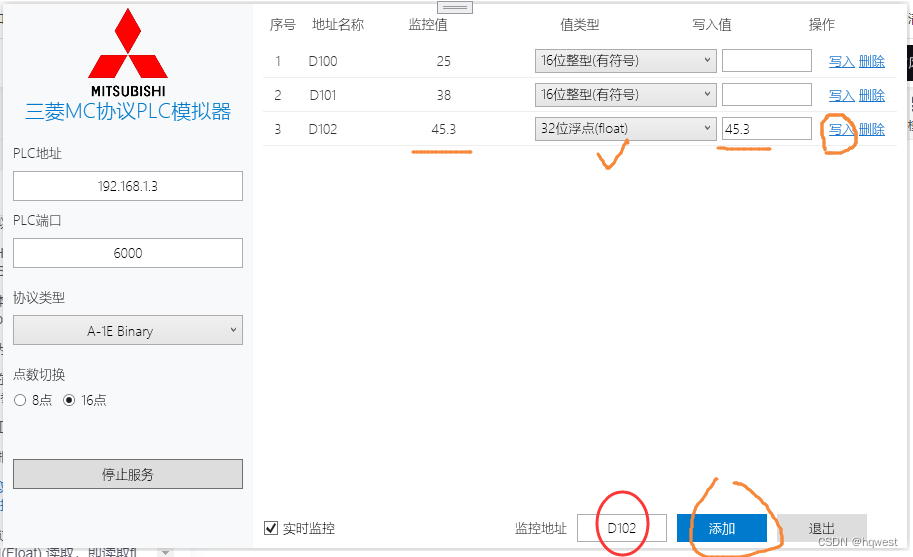
发送:01 FF 0A 00 66 00 00 00 20 44 04 00
01:副头部,也叫功能码,也叫命令类型(0x00 批量位读取、0x01 批量字读取、0x02 批量位写入、0x03 批量字写入、0x04 随机位写入、0x05 随机字写入)
FF:PLC编号
0A 00:超时时间,超时时间是以单位:250ms。
66 00 00 00:地址占4个字节,要读取的地址是102,换成16进制就是66
20 44:存储区,查前面的表就是44 20,同样按小端处理,高位放后面,低位放前面,就变成了20 44。
04 00:读取1个float类型的数据,占4个字节,所以是00 04,按小端处理要求就是04 00,word占2个字节,float占4个字节,记住就搞定了。
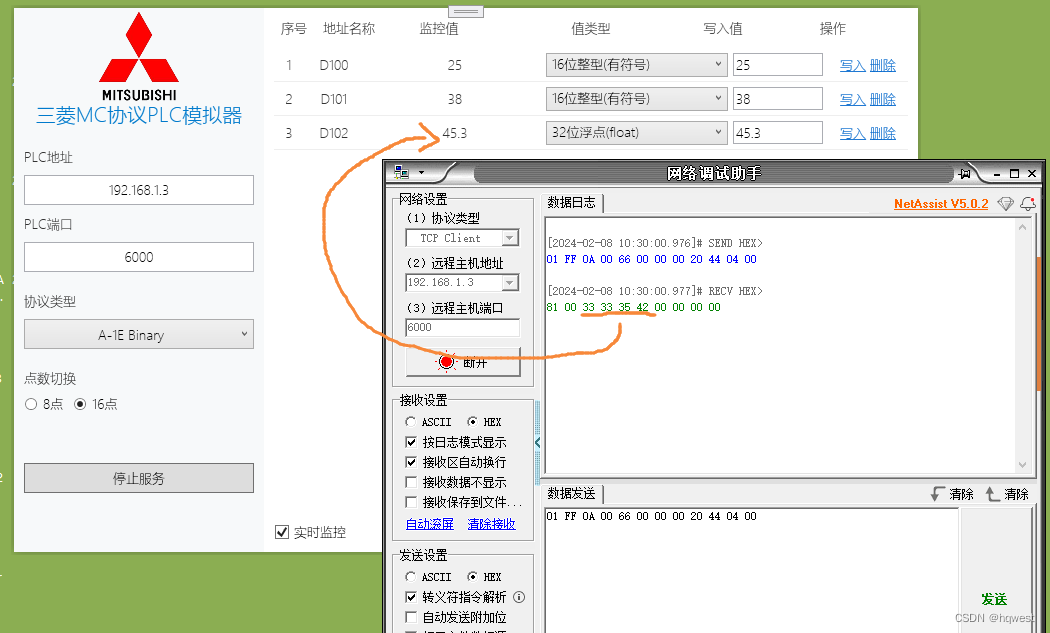
接收:81 00 33 33 35 42 00 00 00 00
81:副头部
00:状态码,表示正常
33 33 35 42:这个是字节byte,不能直接看出是45.3,它需要在程序代码中进行处理,比如代码Console.WriteLine(BitConverter.ToSingle(temp));//字节数组转换成float数据,这个工具软件不能处理,所以你看到的是33 33 35 42。
3、通过A1E进行位的读取M16,M区的地址要转换成16进制,即读取bool类型数据
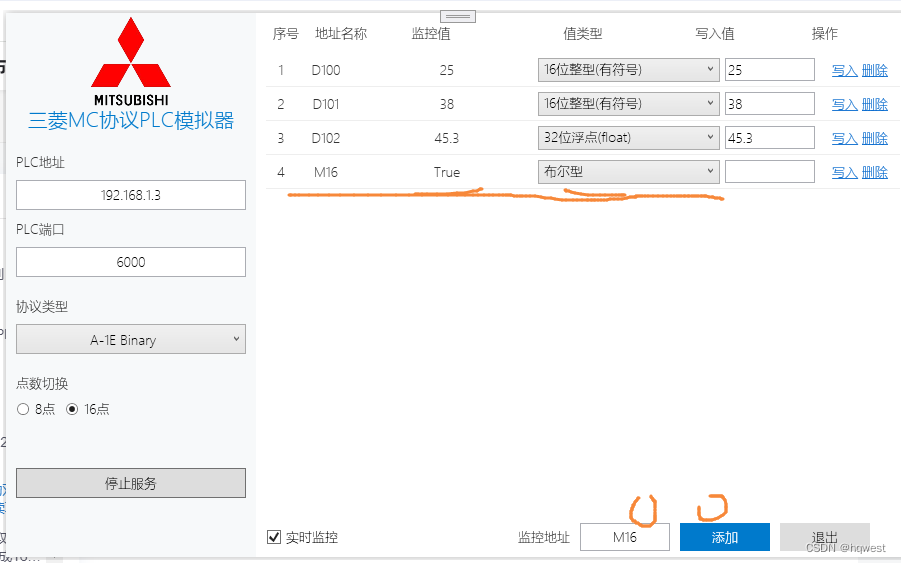
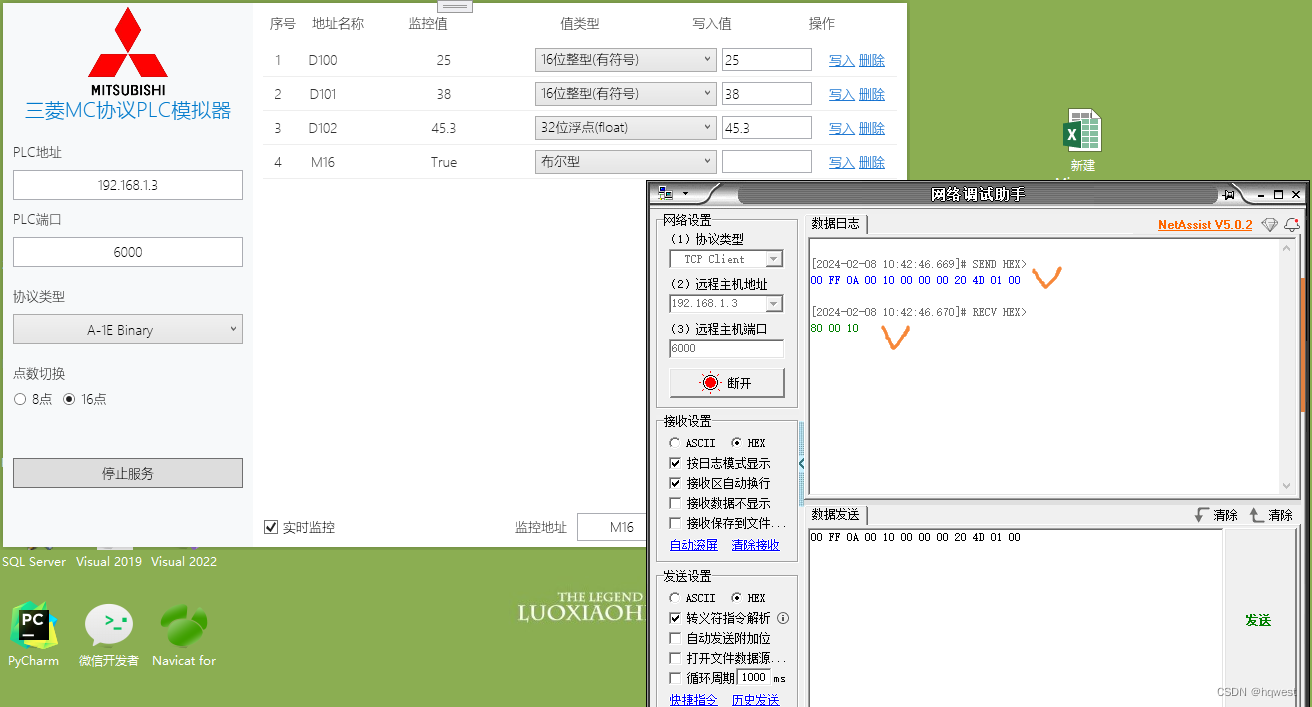
发送:00 FF 0A 00 10 00 00 00 20 4D 01 00
00:副头部,也叫功能码,也叫命令类型(0x00 批量位读取、0x01 批量字读取、0x02 批量位写入、0x03 批量字写入、0x04 随机位写入、0x05 随机字写入)
FF:PLC编号
0A 00:超时时间,超时时间是以单位:250ms。
10 00 00 00:地址占4个字节,要读取的地址是16,换成16进制就是10
20 4D:存储区,查前面的表就是4D 20,同样按小端处理,高位放后面,低位放前面,就变成了20 4D。
01 00:读取1个bool类型的数据,占1个字节,所以是01 00
接收:80 00 10
80:副头部
00:状态码,表示正常成功
10:10是一个字节,其中1就是true,后面的0不要用了,同样的,这个工具软件处理不了,需要在程序代码中处理,但结果一定是OK的。
4、通过A1E进行字的写入,即向 D20,D21写入34,45
先看报文结构,再开始搞事。
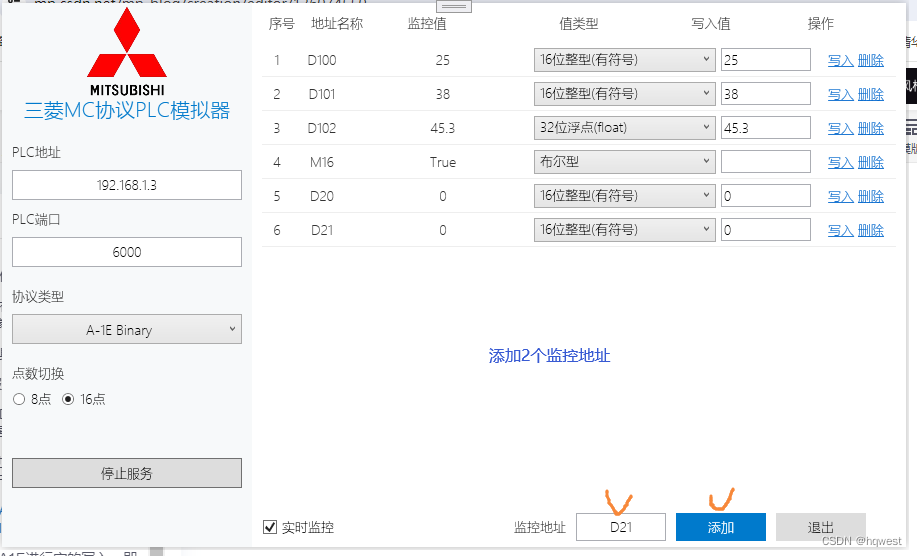
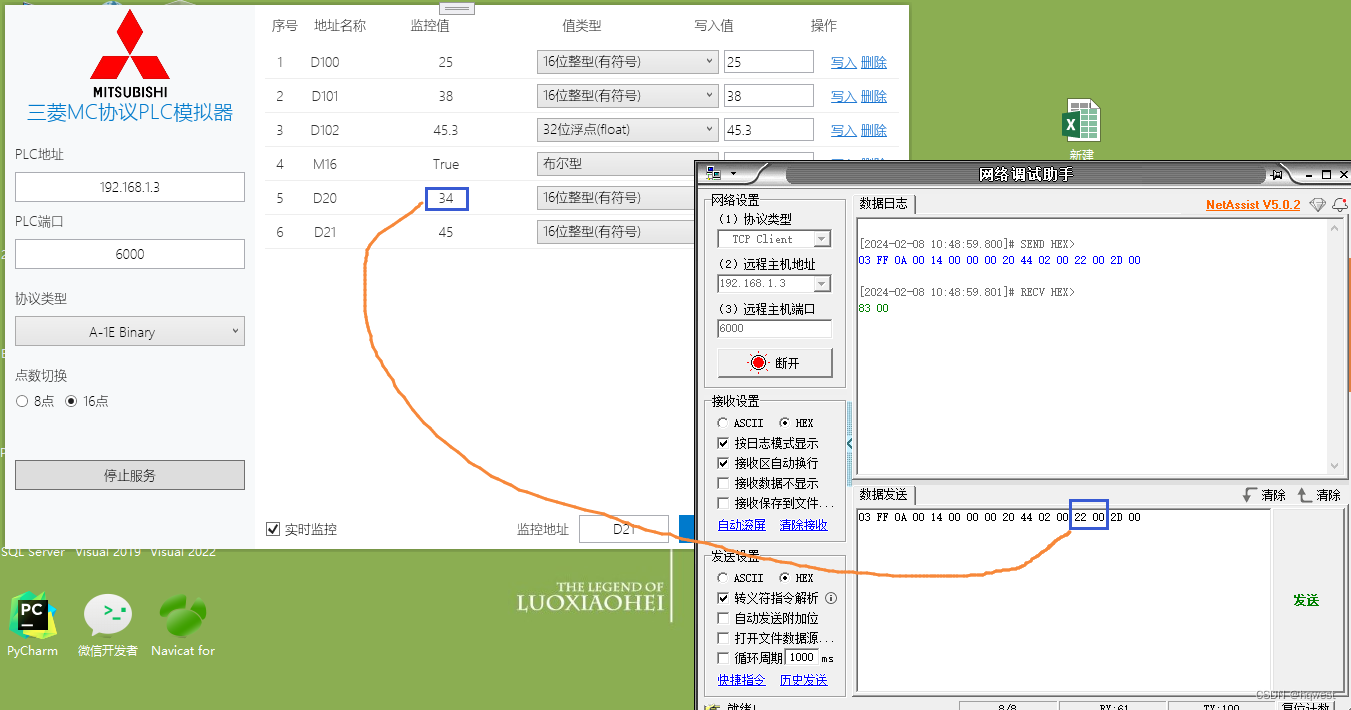
发送:03 FF 0A 00 14 00 00 00 20 44 02 00 22 00 2D 00
03:副头部,也叫功能码,也叫命令类型(0x00 批量位读取、0x01 批量字读取、0x02 批量位写入、0x03 批量字写入、0x04 随机位写入、0x05 随机字写入)
FF:PLC编号
0A 00:超时时间,超时时间是以单位:250ms。
14 00 00 00:地址占4个字节,要读取的地址是20,换成16进制就是14
20 44:存储区,查前面的表就是44 20,同样按小端处理,高位放后面,低位放前面,就变成了20 44。
02 00:写入长度2个
22 00:要写入的数据是34,换成16进制就是22,用2个字节表示就是0022,按小端处理要求就是2200
2D 00:要写入的数据是45,换成16进制就是2D,用2个字节表示就是002D,按小端处理要求就是2D00
接收:83 00
83:副头部
00:状态码,表示正常成功
5、通过A1E向 D30 写入一个Float数据24.5,一个float占4个字节
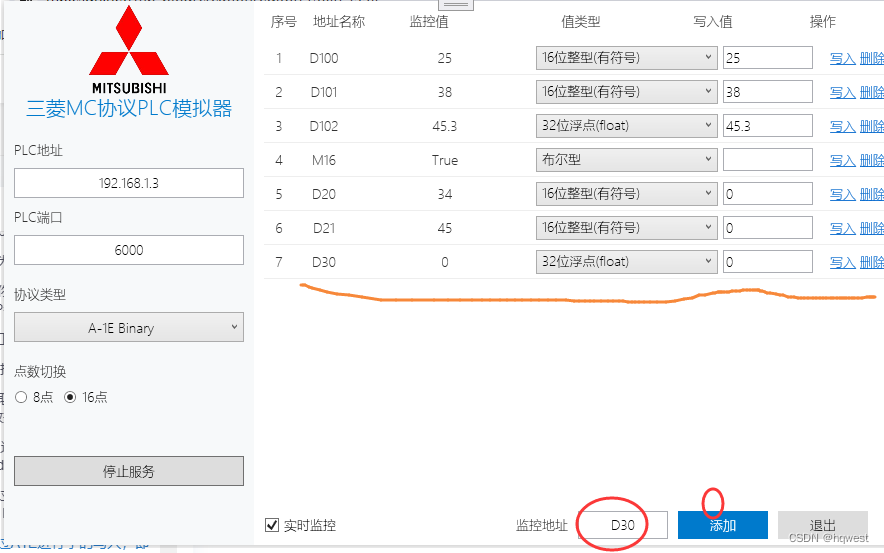
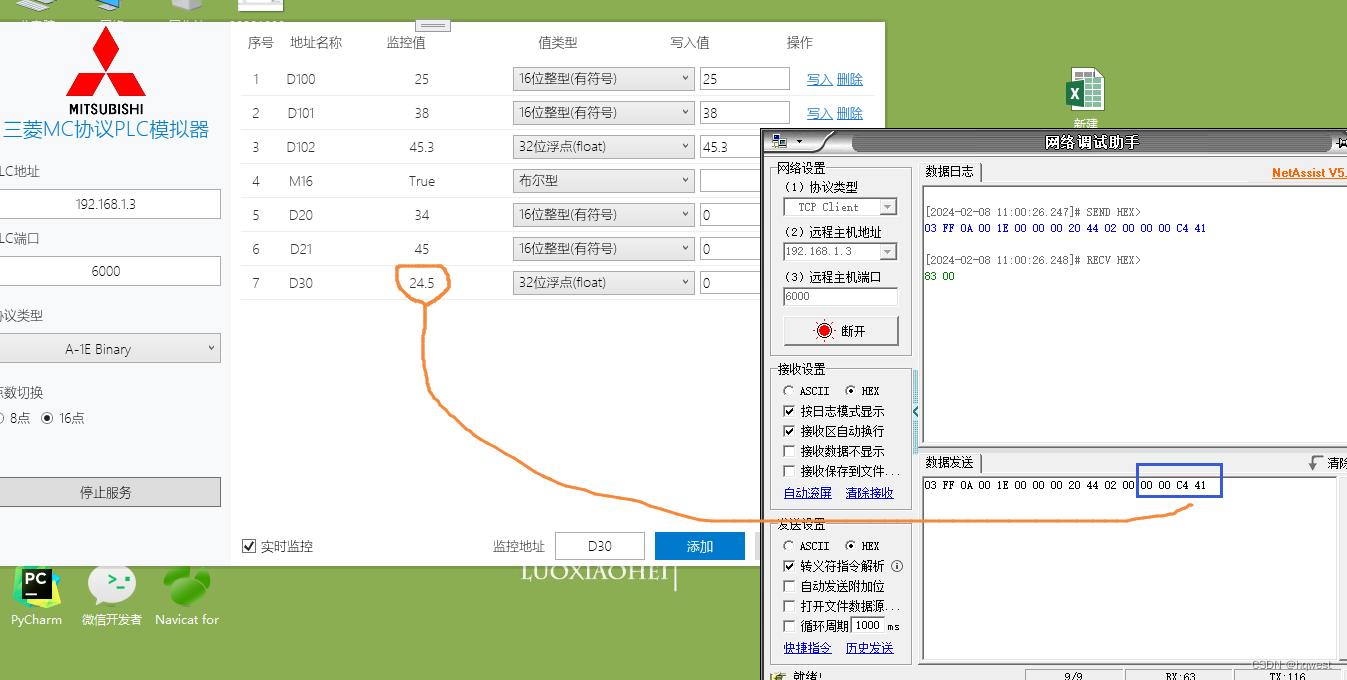
发送:03 FF 0A 00 1E 00 00 00 20 44 02 00 00 00 C4 41
03:副头部,也叫功能码,也叫命令类型(0x00 批量位读取、0x01 批量字读取、0x02 批量位写入、0x03 批量字写入、0x04 随机位写入、0x05 随机字写入)
FF:PLC编号
0A 00:超时时间,超时时间是以单位:250ms。
1E 00 00 00:地址占4个字节,要读取的地址是30,换成16进制就是1E
20 44:存储区,查前面的表就是44 20,同样按小端处理,高位放后面,低位放前面,就变成了20 44。
02 00:写入长度2个,为什么不是01而是02,因为float占2个word的长度。
00 00 C4 41:要写入的数据是24.5,换成字节就是C4 41
接收:83 00
83:副头部
00:状态码,表示正常成功
4、小结
到目前为止,还没有网上有哪个文章有我如此的报文分析,操作实例,一大批都是抄来抄去,仅以此文章献给最爱的粉丝,希望对各位大师有些启示。
原创真的不容易,走过路过不要错过,点赞关注收藏又圈粉,共同致富。
原创真的不容易,走过路过不要错过,点赞关注收藏又圈粉,共同致富。
原创真的不容易,走过路过不要错过,点赞关注收藏又圈粉,共同致富。
