服装定制网站的设计与实现seo文章生成器
设计测试用例方法之判定表
1、判定表:是一种表达逻辑判断的工具。
2、判定表:包含四部分
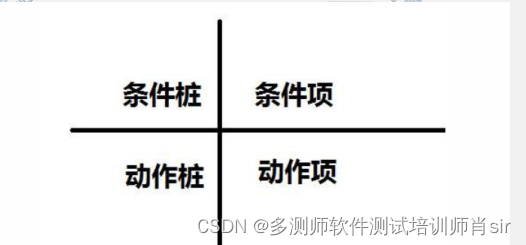
1)条件桩(condition stub):列出问题的 所有条件(通常条件次序无关紧要)。
2)条件项(condition entry):列出针对 它条件的取值(所有情况下的真假值)
3)动作桩(action stub):列出问题规定可采取的动作(顺序无约束)。
4)动作项(action entry):列出条件各种情况的应采取的 动作。
3、创建步骤:
1)确定规则的个数:若有N个条件,每一个条件下有2个值,则有2^n种规则。
2)列出所有条件桩与动作桩。
3)输入条件项。
4)输入动作项得到初始判定表。
5)简化(合并相似规则)。
6)编写测试用例
4、判定表的作用:
利用判定表将复杂的问题按照各种可能的 情况全部列举出来,能针对不同逻辑条件 的组合值,分别执行不同的操作
5、案例:
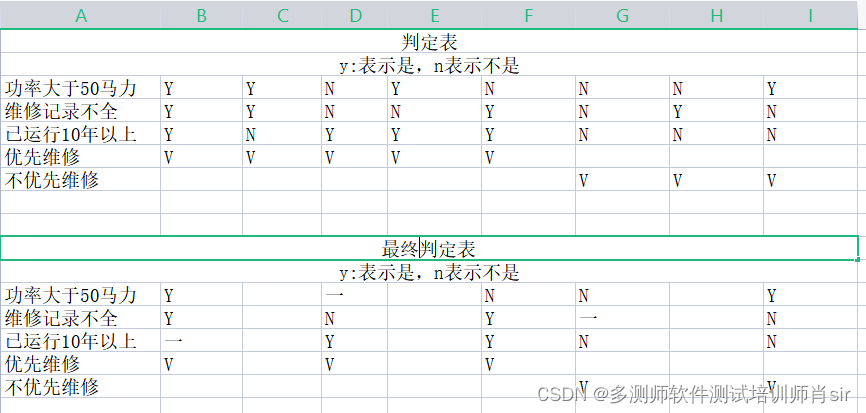
对功率大于50马力的机器且维修记录不全或已运行10年以上的机器,应给予优先的维修处理……”。请建立判定表。
理解:1、 功率大于50马力的机器 和维修记录不全(优先)
2、已运行10年以上的机器(优先)
条件桩:功率大于50马力、维修记录不全、已运行10年以上
条件项:满足、不满足
动作桩:优先维修、不优先维修
动作项:是、否
3个条件 2个水平数 2的3次方8种组合情况
初始判定表:

最终判定表:
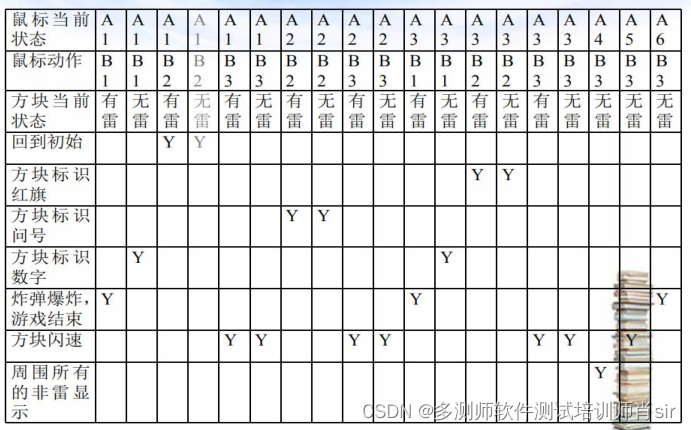
案例2:
扫雷游戏
网站1:(没有问号)http://www.minesweeper.cn/
网站2:https://saolei123.com/
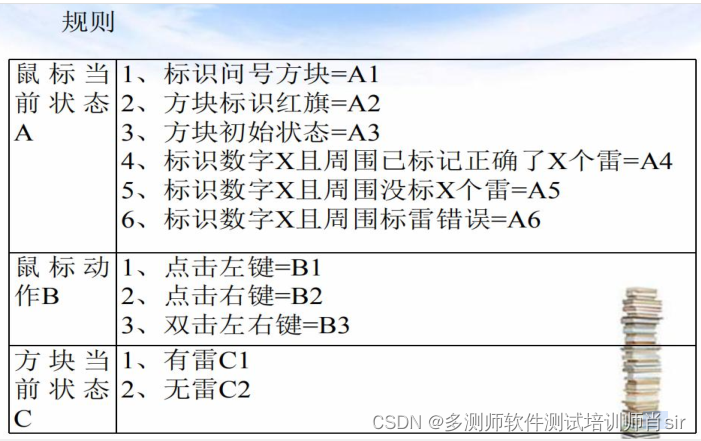
判定表-经典案例:扫雷游戏 条件:
- 方块当前状态:标识问号方块、方块初 始状态、方
块标识红旗标识数字X且周围 已标记了X个雷、标识
数字X且周围没有 标记完X个雷,标识数字X标雷错误 - 鼠标操作:左键、右键、双击
- 方块状态:有雷、无雷
动作: - 方块白色
- 方块标识问号
- 方块标识数字
- 方块旗子
- 炸弹爆炸,游戏结束
- 未标识方块闪速
- 周围所有的非雷显示
11.