万网速成网站大气简洁的WordPress主题
vivo 发布 2023 年度十大产品技术创新

近日,vivo 发布了「2023 年度科技创新」十大产品技术创新榜单,并将这些技术分为了 4 个板块。
「四大蓝科技」为 vivo 在去年推出的全新技术品牌,涵盖蓝晶芯片技术栈、蓝海续航系统、蓝心大模型、蓝河操作系统等。其中的 AI 蓝心大模型矩阵,在多个相关榜单的排名都是第一梯队的水准,并且覆盖十亿、百亿、千亿三个参数量级。
影像算力方面,vivo 发布的了 6nm 影像芯片 V3,能效提升了 30%,并且用 AIGC 等新技术,赋能手机影像。
性能创新方面,vivo 发布了自研电竞芯片 Q1,通过芯片优化设计和自研算法提升,实现真正的低时延插帧。


阿里全新多模态 AI 代理,可模拟人类操作手机

Mobile-Agent 是阿里巴巴和北京交通大学开发的可以模拟人类操作手机的自主多模态 AI 代理。该项目利用人工智能技术,特别是在多模态大型语言模型(如 GPT-4V)的应用,以实现移动设备代理的自主决策和交互。
Mobile-Agent 首先利用视觉感知工具来准确识别和定位应用程序前端界面中的视觉和文本元素。基于感知到的视觉上下文,它会自主规划和分解复杂的操作任务,并逐步导航移动应用程序进行操作。
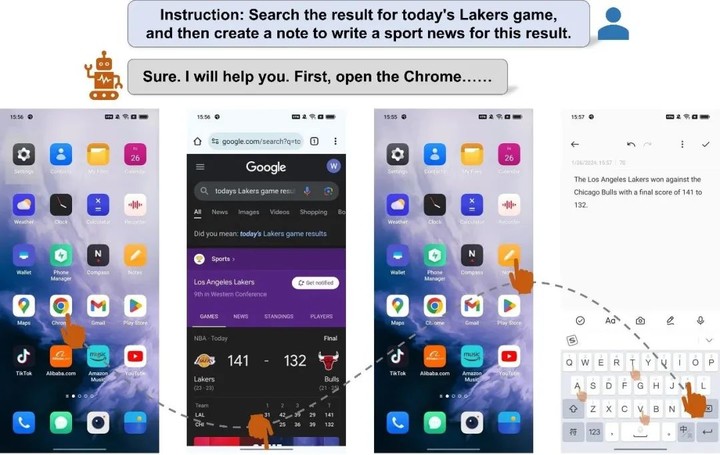
实验结果表明 Mobile-Agent 取得了显著的准确率和完成率。即使有挑战性的指令,例如多应用程序操作,Mobile-Agent 仍然可以完成要求。
Mobile-Agent 最大的特点为:
* 纯可视化解决方案,独立于 XML 和系统元数据。
* 操作范围不受限制,可进行多应用操作。
* 多种视觉感知工具,用于操作定位。
* 无需探索和培训,即插即用。