网站平台建设所需开发工具企业展厅策划设计公司排名
二叉树采用二叉链表存储:编写计算整个二叉树高度的算法
(二叉树的高度也叫二叉树的深度)
代码思路:
首先你要明白什么是树的高度,简言之就是树有多少层,如下图:
下面这棵树的高度就是4
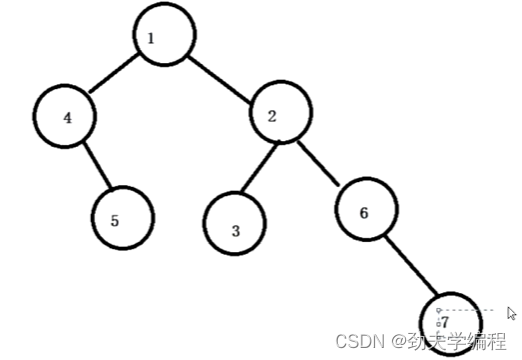
首先我们观察根节点,根节点左子树高度是2,右子树高度是3
那么我们取左右子树高度较大值3,再加上根节点自己一个,那根节点高度就是3+1=4
那么问题来了,我们怎么知道根节点左右子树高度呢?
那就遍历一下根节点左右子树呗,问题转换成求结点左右子树高度,
再然后问题就转换成,求根节点左右子树的子树高度了。。。
这样是不是就是我们熟悉的递归啊。
代码实现如下:
int BiTreeDepth(BiTree T) {if (T != NULL) {//递归退出条件return 0;}int i = 0;//标记左子树高度int j = 0;//标记右子树高度if (T->lchild) {//如果还有左子树,往下递归i = BiTreeDepth(T->lchild);}else {i = 0;}if (T->rchild) {//如果还有右子树,往下递归j = BiTreeDepth(T->rchild);}else {j = 0;}return i >= j ? i+1 : j+1;//向上一层结点返回该子树的深度,注意这里要+1因为还有一个根节点高度
}