能够做简历的网站手工制作代加工接单网
目录
- 1 DNS运用
- 1.1 DNS功能作用
- 1.2 DNS配置实践
- 2 DNS生产最佳实践方案
- 2.1 全球加速功能
- 2.2 不同运营商的加速方案
- 2.3 全球业务高可用方案
- 2.4 跨地域负载均衡
- 3 DNS域名劫持解决方案
- 4 CDN剖析
- 4.1 CDN原理
- 4.2 缓存过期配置处理流程
- 4.3 缓存配置规则
- 5 CDN运用
- 6 CDN最佳实践方案
- 6.1 ECS源站加速
- 6.2 OSS资源加速
- 6.3 CDN缓存命中率优化
1 DNS运用
1.1 DNS功能作用
-
负载均衡
DNS负载均衡, 原理是给用户返回不同的IP地址, 例如:
主机记录 记录类型 线路类型 记录值 TTL www A 默认 200.202.101.1 600 www A 默认 200.202.101.2 600 www A 默认 200.202.101.3 600 www A 默认 200.202.101.4 600 解析返回得到的 IP 地址是可以是轮询, 也可以是随机得到的 IP 地址
-
健康检查:
支持ping、telnet、http(s)协议实时健康检查,获取应用服务运行状态。
-
故障切换
支持根据健康检查结果自动或者手工进行failover切换操作,实现主备切换、自动修改故障域名的解析,对异常的地址(服务)进行故障隔离或切换。
-
智能DNS
支持根据不同运营商、区域进行智能DNS解析,实现用户就近访问。
-
阿里云DNS免费版 vs 付费版
参数项 参数值 免费版 最低TTL值 最低1秒 最低2秒 子域名级别 最高10级 最高2级 A记录负载均衡 带权重的A记录轮询,最多支持90条 带权重的A记录轮询,最多支持10条 URL转发 URL显性转发+URL隐性转发,最多支持6条 URL显性转发+URL隐性转发,最多支持2条 泛解析 √ √ 运营商线路 默认、移动、联通、电信、教育网 默认、移动、联通、电信、教育网 运营商线路细分 移动(省份)、联通(省份)、电信(省份)、教育网(省份),共135条线路 不支持 海外线路细分 亚洲、大洋洲、欧洲、北美、南美、非洲 6大洲34个国家及地区 海外 搜索引擎线路 搜索引擎、谷歌、百度、必应、有道、雅虎 谷歌、百度、必应 更多区别, 详情
1.2 DNS配置实践
主要步骤: 创建实例 -> 配置访问策略 -> 主域名设置CNAME解析到实例的CNAME接入域名。
-
创建两台虚拟机
两台虚拟机都部署相同的服务(app-server), 用于高可用的测试验证。
-
创建地址池
这里指向一台主节点。
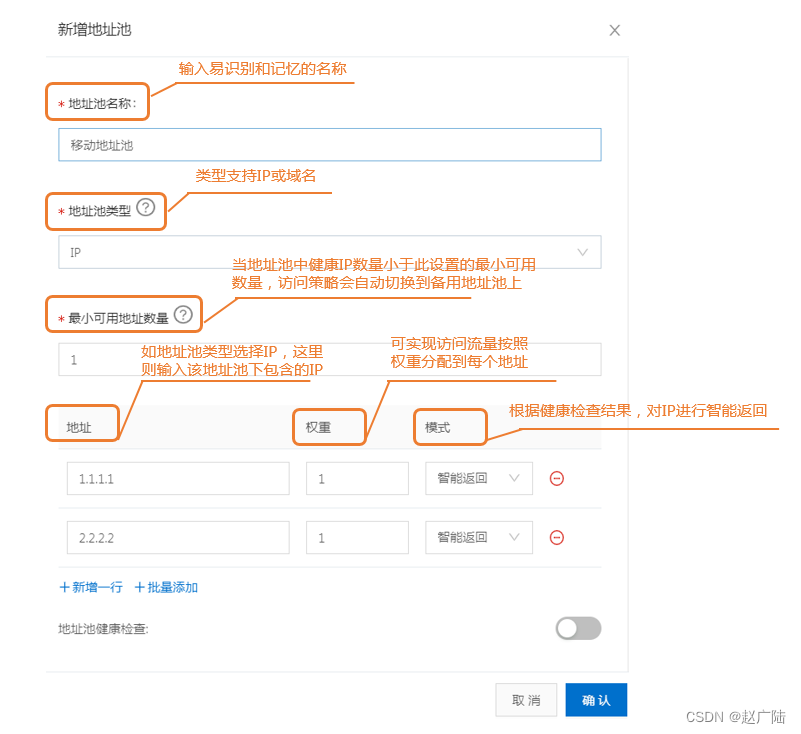
- 访问策略配置
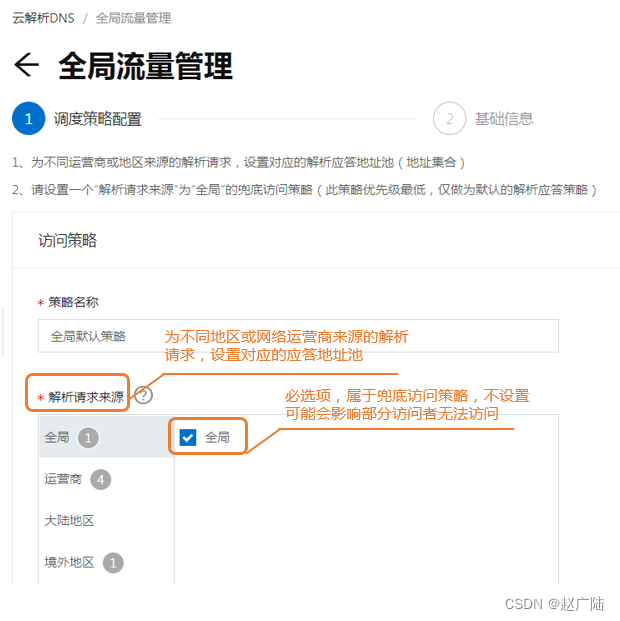
配置地址池信息, 如果出现故障, 可以自动切换至备用地址池。
备用地址池指向另外一台云服务器。
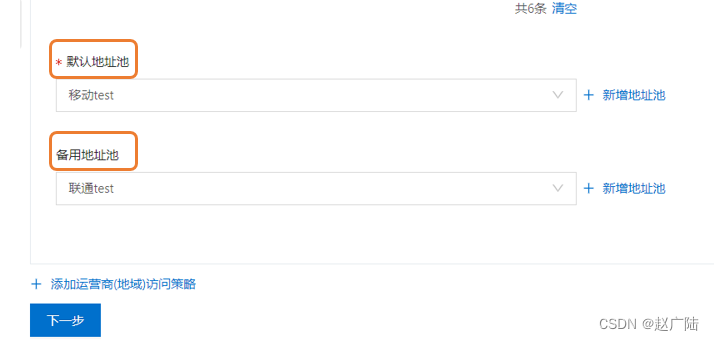
- 全局配置
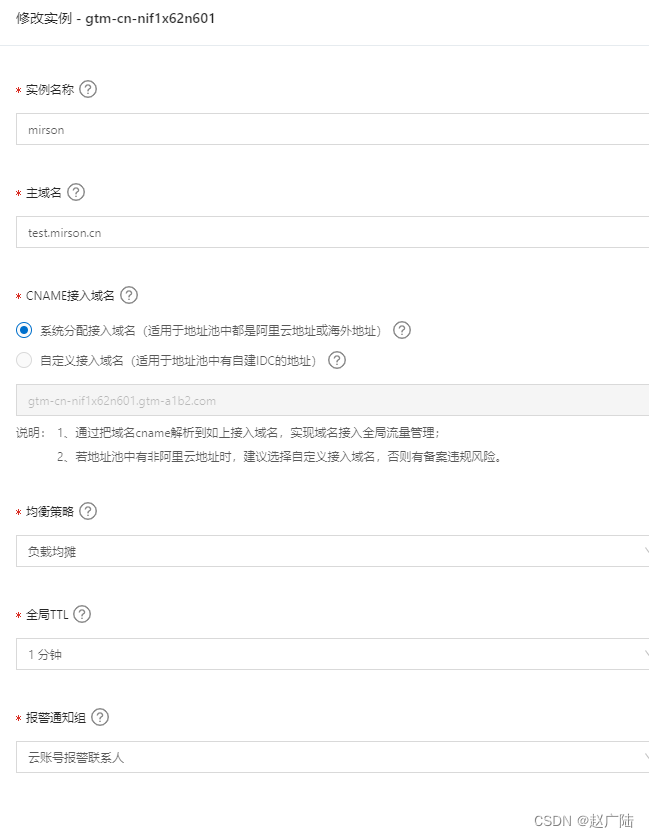
这里可以采用系统分配生成的cname域名, 主域名是用户访问应用服务使用的域名,必须填写真实主域名, 这里主域名是配置: test.mirson.cn。
- 开启健康检查
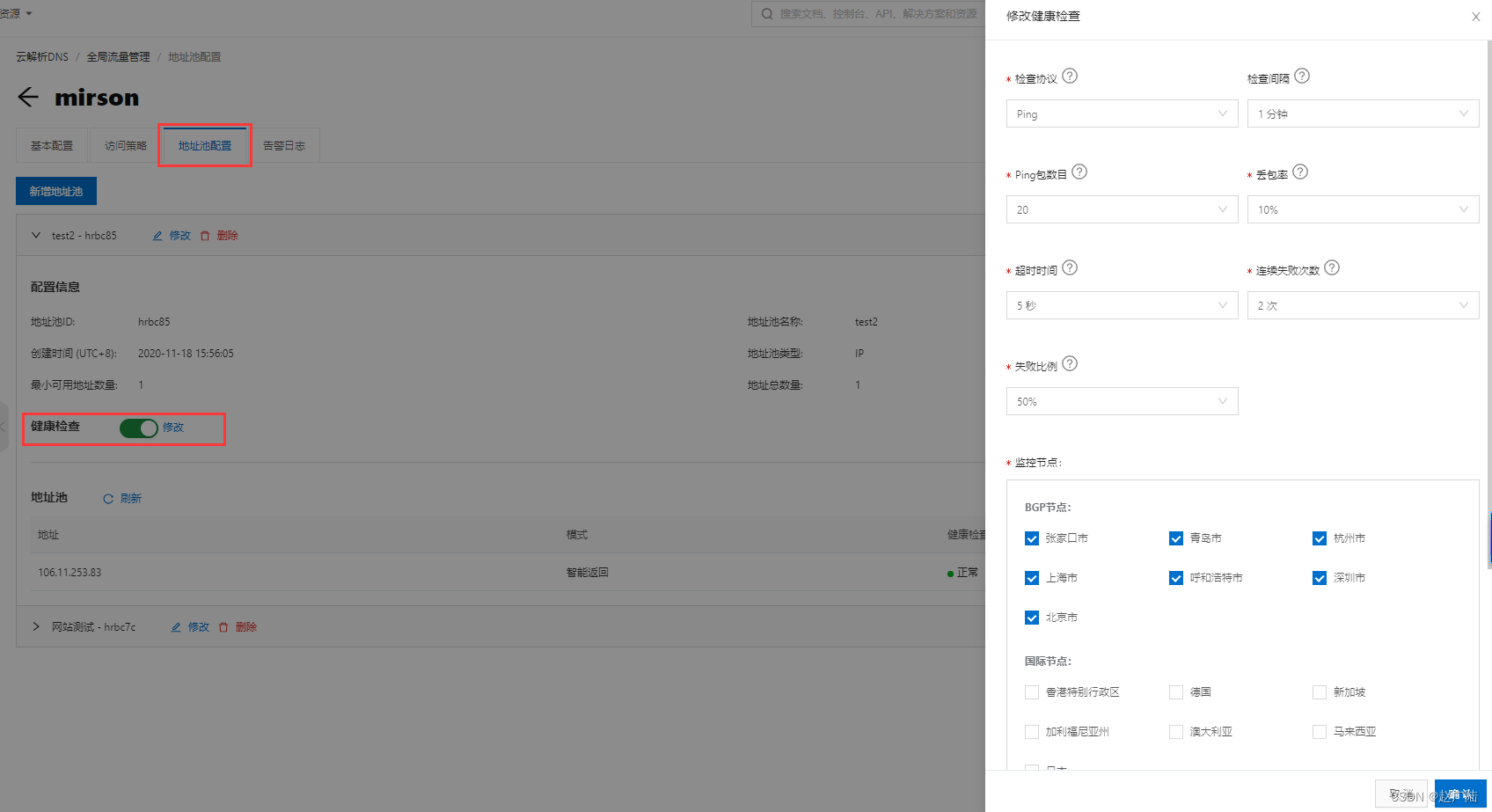
需要对地址池里的IP地址配置健康检查,以获取应用服务的可用性,从而达到根据应用服务地址可用性的状态实现自动故障隔离以及故障自动切换。
-
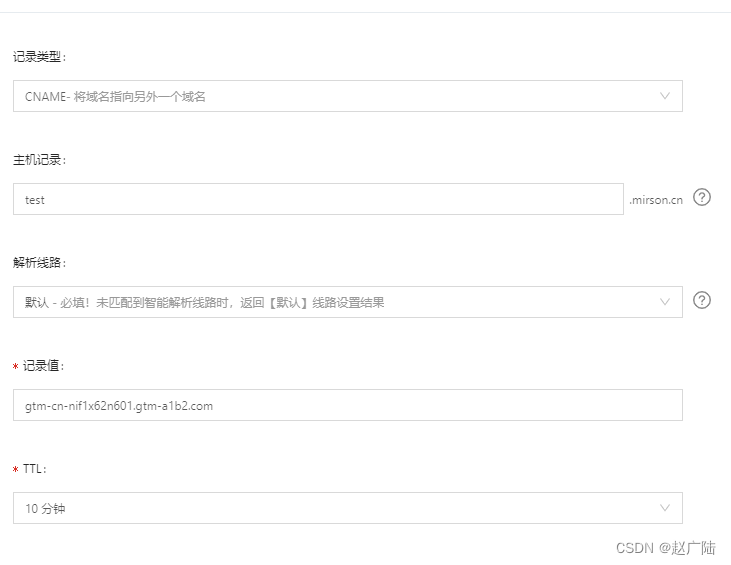
DNS解析设置
最后, 在解析设置里面, 添加记录。这里面的记录值要填写上面所设置的cname域名信息。
-
测试
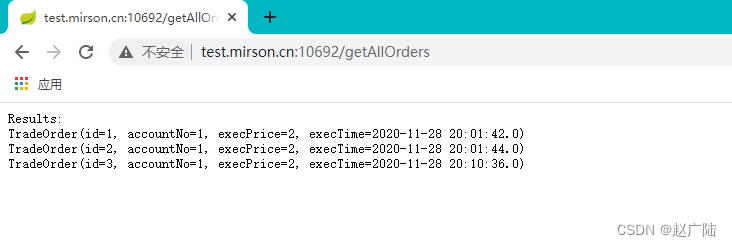
通过访问test.mirson.cn会指向连接池所配置的IP信息。
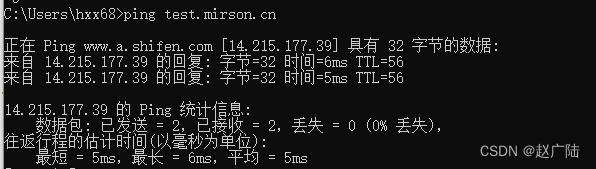
通过域名进行访问:
-
故障测试
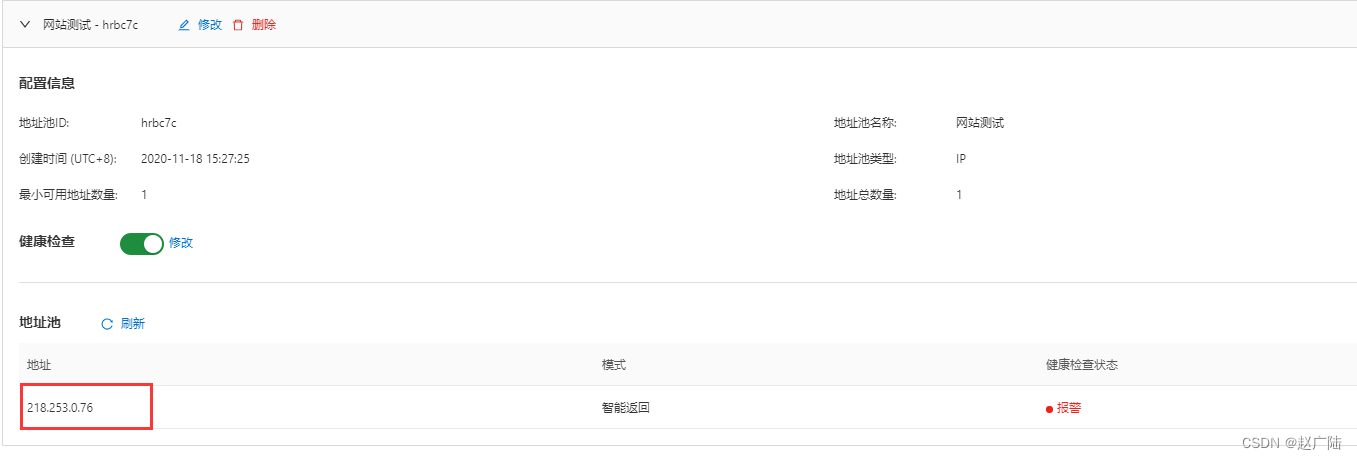
将地址池改为218.253.0.76不可用地址或停止服务, 开启健康检查后,会自动出现报警提示,并切换为备用地址池。
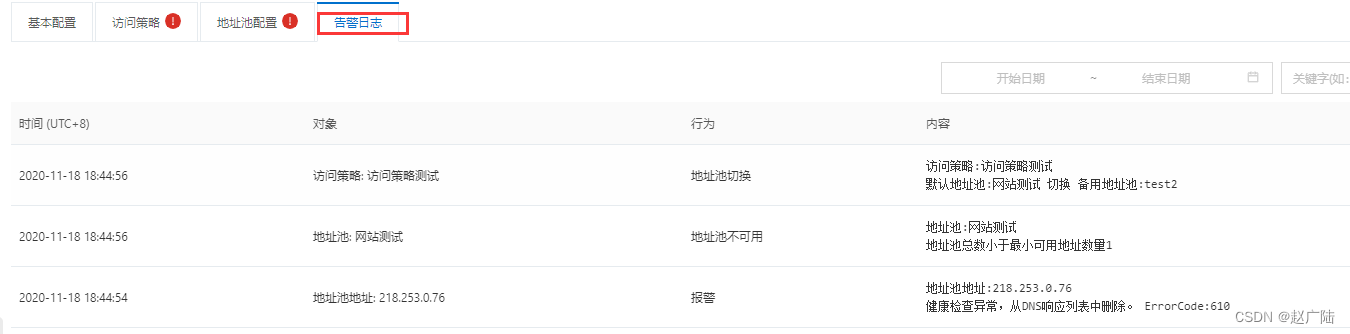
查看告警日志, 可以看到详细信息
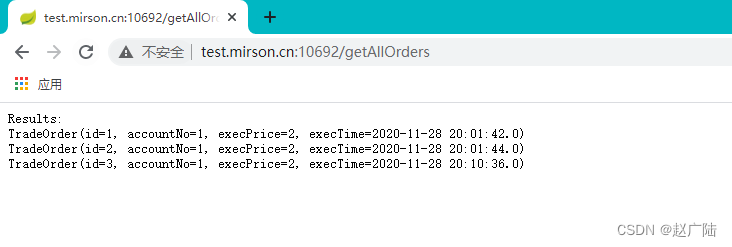
访问服务:
2 DNS生产最佳实践方案
2.1 全球加速功能
全球加速可以为不同地域的客户端智能返回不同的加速IP,降低解析时延,如果是面向国际的服务,是需要开启此功能, 如果只是国内使用, 可以不用开启。
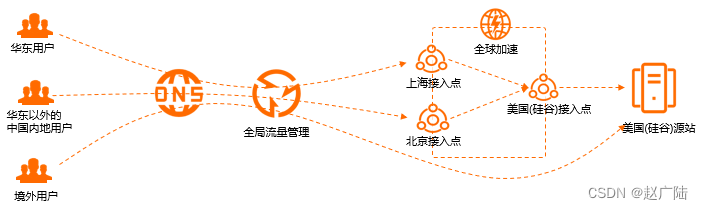
- 华东区域客户端访问Web服务会智能解析到全球加速上海加速IP。
- 华东以外的其他中国内地区域客户端访问Web服务会智能解析到全球加速北京加速IP。
- 境外区域客户端访问Web服务会直接走境外线路到美国(硅谷)源站IP。
详细操作, 查阅官方文档。
2.2 不同运营商的加速方案
不同运营商会有自身专有的网络, 如果跨运营商访问存在不稳定的情况, 可以开启此功能。
实现原理:
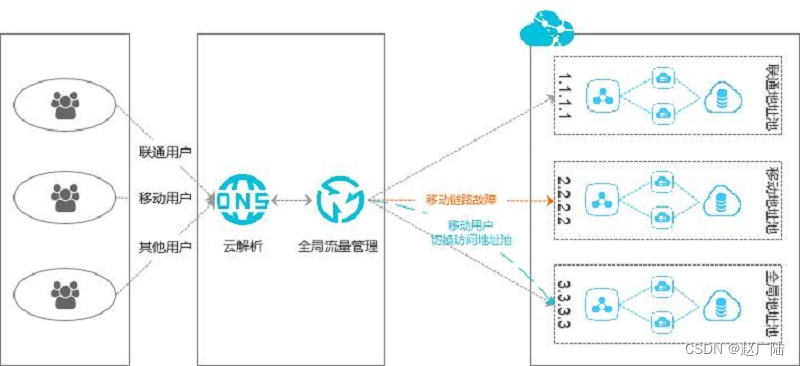
- 联通用户通过域名,访问应用服务的联通IP地址:1.1.1.1 。
- 移动用户通过域名,访问应用服务的移动IP地址:2.2.2.2 。
- 其他用户通过域名,访问应用服务的默认电信IP地址:3.3.3.3 。
详细操作, 查阅官方文档。
2.3 全球业务高可用方案
部署方案:
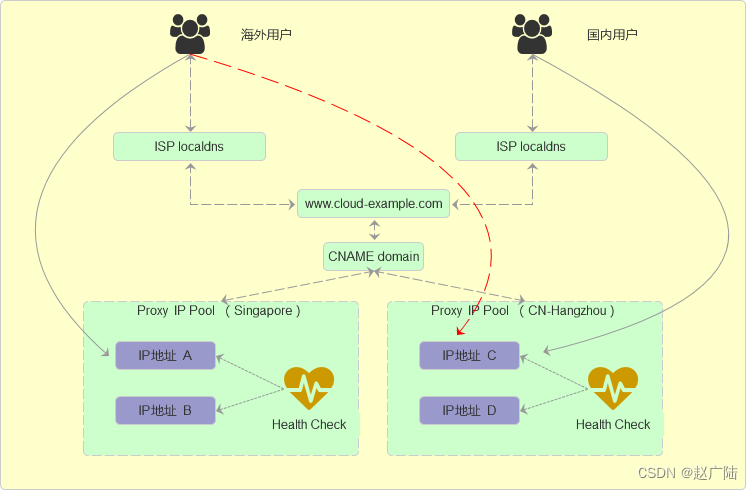
为了实现全球用户都能获得较好的访问质量,通常企业会在中国大陆和海外分别部署至少两套以上的接入服务点,后端数据服务仍然使用一套。通过DNS服务,对于不同地区的用户请求流量做智能调度,将用户访请求流量路由至不同的接入服务点。出现故障灾难时,各接入站点自建互相备份,最终实现业务的高可用。
操作配置说明
2.4 跨地域负载均衡
企业应用服务一般会有多个IP,且多个IP地址可能分布于不同地区。可以采用流量平均分配原则,对多个IP地址进行负载均摊,实现用户访问同一个应用服务域名时多个IP地址同时承担用户的访问请求。
实现方案:
平均分配与加权分配配置
3 DNS域名劫持解决方案
-
域名劫持
域名劫持又称DNS劫持,是指在劫持的网络范围内拦截域名解析的请求,域名劫持通常相伴的措施是封锁正常DNS的IP, 这样就可以采用虚假的IP来代替真实的IP。
常见的域名劫持问题:
- 广告劫持:用户正常页面指向到广告页面。
- 恶意劫持:域名指向IP被改变,将用户访问流量引到挂马,盗号等对用户有害页面的劫持。
- 本地DNS缓存:为了降低跨网流量及用户访问速度进行的一种劫持,导致域名解析结果不能按时更新。
-
HTTPDNS解决方案
HTTPDNS是仅面向移动App域名劫持解决方案,具有域名防劫持、精准调度的特性。
优势特性:
-
域名防劫持
域名解析请求直接发送至HTTPDNS服务器,绕过运营商Local DNS,避免域名劫持问题。
-
调度精准
直接获取客户端 IP ,基于客户端 IP 获得最精准的解析结果,让客户端就近接入业务节点。
-
实时生效
可以实现毫秒级低解析延迟的域名解析效果。
-
-
使用配置
流程:
操作配置
4 CDN剖析
4.1 CDN原理
-
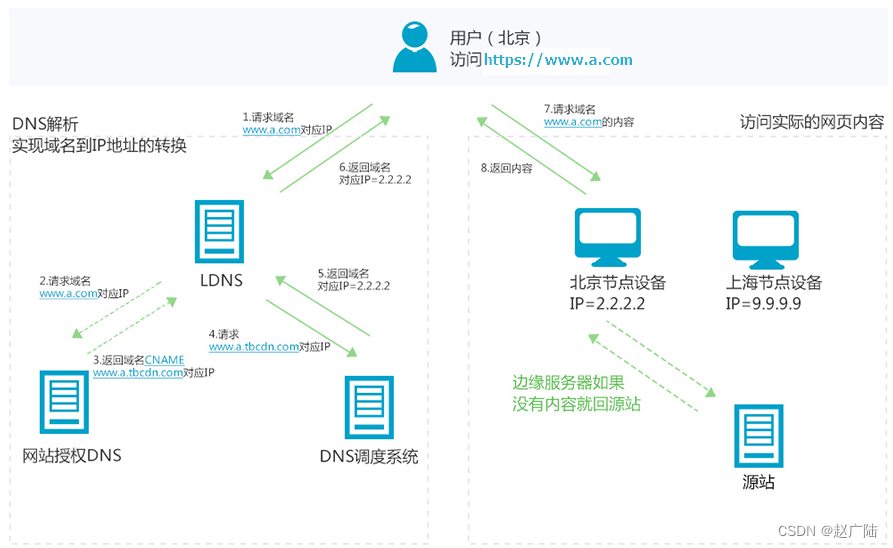
当终端用户(北京)向
www.a.com下的指定资源发起请求时,首先向LDNS(本地DNS)发起域名解析请求。 -
LDNS检查缓存中是否有
www.a.com的IP地址记录。如果有,则直接返回给终端用户;如果没有,则向授权DNS查询。 -
当授权DNS解析
www.a.com时,返回域名CNAMEwww.a.tbcdn.com对应IP地址。 -
域名解析请求发送至阿里云DNS调度系统,并为请求分配最佳节点IP地址。(用户从北京访问,返回最近的北京节点信息。)
-
LDNS获取DNS返回的解析IP地址。
-
用户获取解析IP地址。
-
用户向获取的IP地址发起对该资源的访问请求。
-
如果该IP地址对应的节点已缓存该资源,则会将数据直接返回给用户。
-
如果该IP地址对应的节点未缓存该资源,则节点向源站发起对该资源的请求。
可以根据缓存策略做相应配置(针对静态资源配置指定目录和文件后缀名的缓存过期时间和优先级,资源过期后,自动从CDN节点删除。)
-
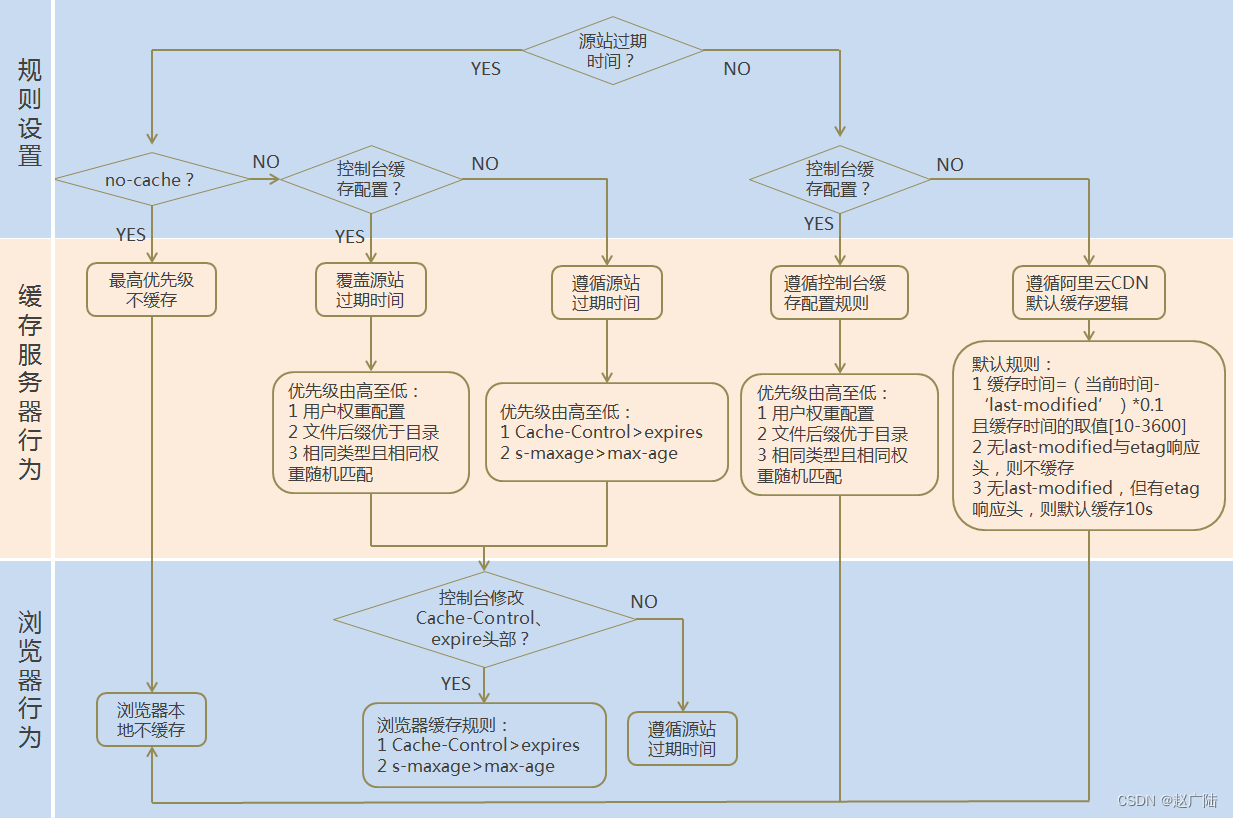
4.2 缓存过期配置处理流程
4.3 缓存配置规则
默认的缓存时间计算规则, 要符合3个条件:
- t =(curtime-last_modified)*0.1 【结果是时间差的10%】
- t = max(10s,t) 【最小要大于10S】
- t = min(t,3600s)【最大不能超过3600s】
缓存规则示例解析:
- 如果last-modified
为20140801 00:00:00,当前时间为20140801 00:01:00, (curtime-Last_modified)*0.1=6s,那么缓存时间为10s(因为最小值要大于10s)。 - 如果
last-modified为20140801 00:00:00,当前时间为20140802 00:00:00,(curtime-Last_modified)*0.1=8640s,那么缓存时间为3600s。 - 如果last-modified
为20140801 00:00:00,当前时间为20140801 00:10:00`,(curtime-Last_modified)*0.1=60s,那么缓存时间为60s。
5 CDN运用
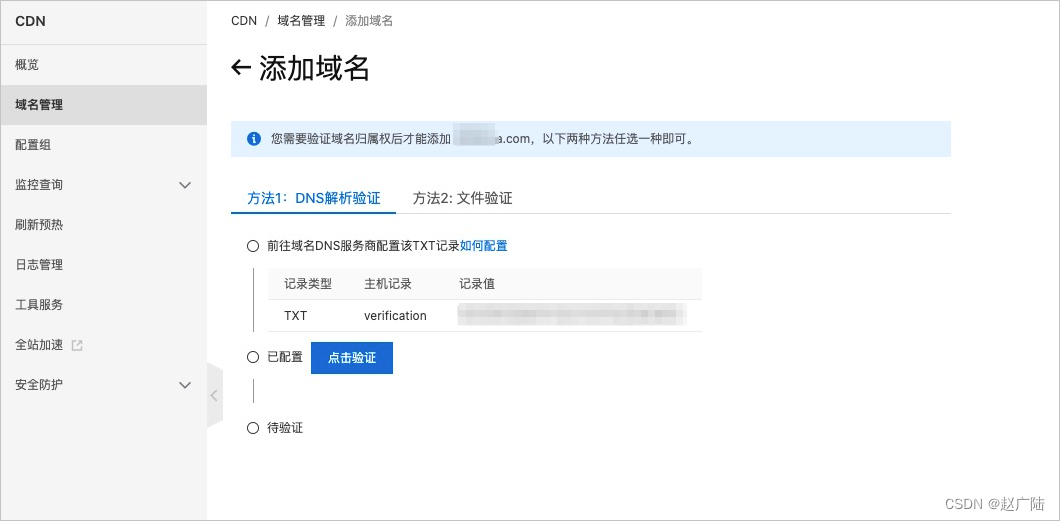
- 验证域名所属权
-
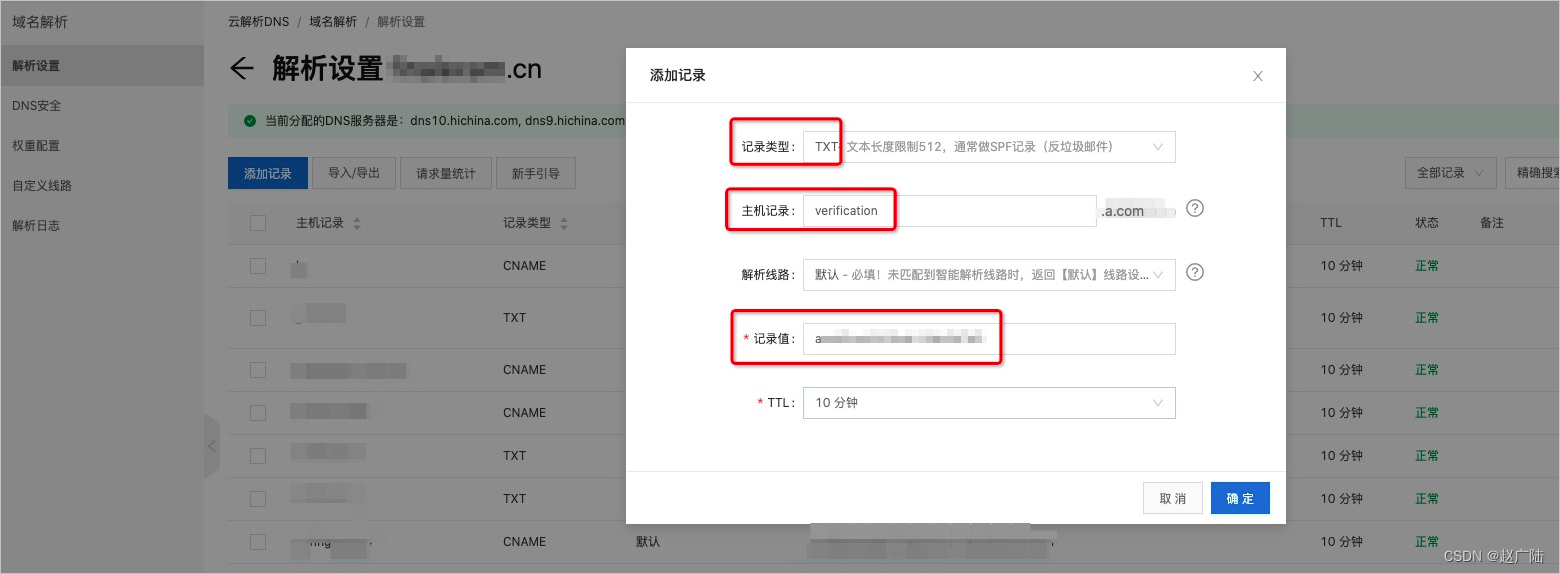
域名验证设置
如果是阿里云申请的域名, 设置起来比较简单, 直接添加一条验证记录:
如果是其他第三方域名, 可以采用文件验证方式。
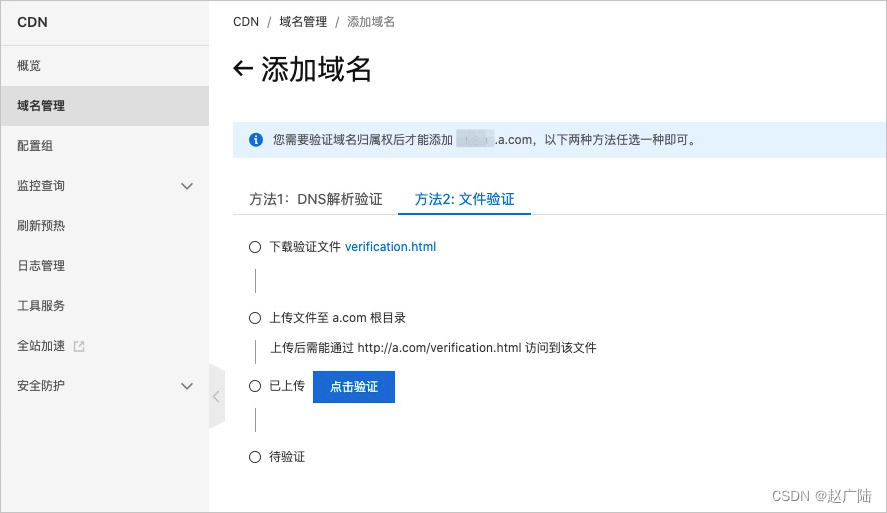
下载verification.html验证文件,上传到您的域名源站服务器的根目录。
- 添加域名
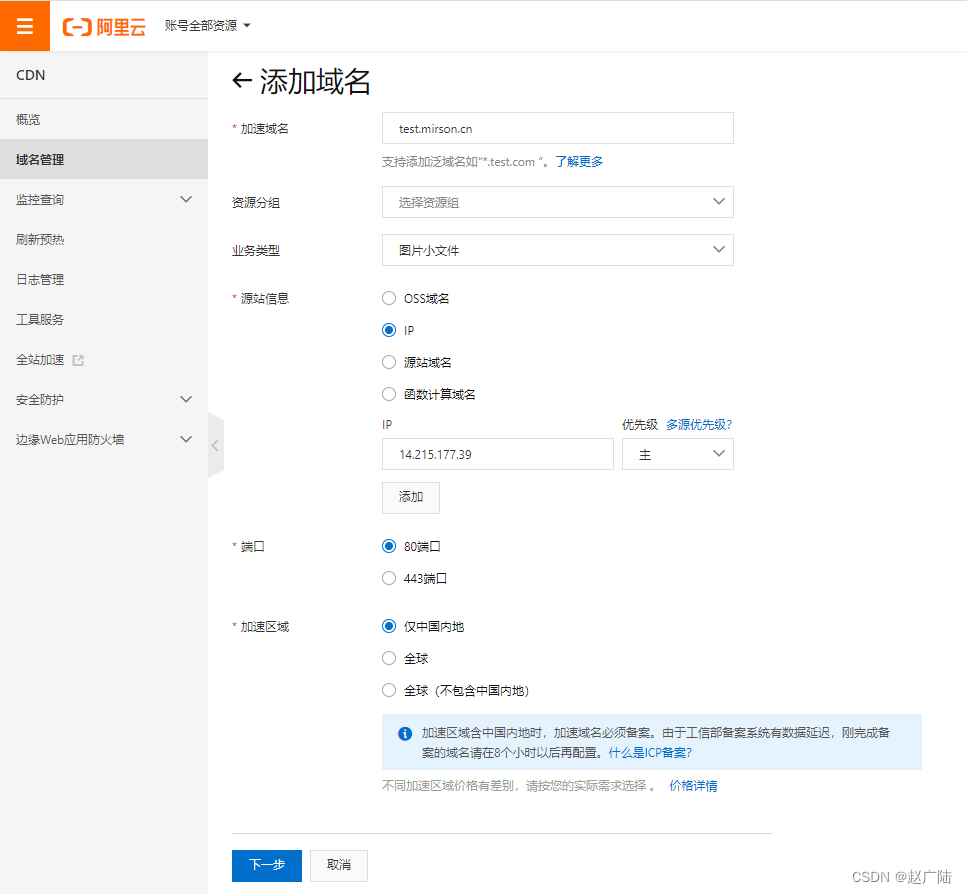
这里所填写的加速域名是需要先备案。
业务类型有五种, 根据需要选择不同配置:
-
图片小文件
内容多为小型的静态资源 (如小文件、图片、网页样式文件等),推荐您选择图片小文件业务类型。
-
大文件下载
内容为较大的文件(大于20MB的静态文件),推荐选择大文件下载业务类型。
-
视频点播加速
如果需要加速音频或视频文件,例如音乐、视频的点播业务场景,推荐选择此类型。
-
全站加速
网站或应用含有大量动静态内容混合,且较多为动态资源请求,可以使用全站加速,静态内容高速缓存,动态内容通过阿里云的最优链路算法及协议层优化快速回源获取。
-
安全加速
网站易遭受攻击且必须兼顾加速的业务场景,则需要使用安全加速功能,提升全站安全性。例如金融交易、电商网站等。
-
配置CNAME
阿里云的配置流程:
- 记录加速域名的CNAME地址
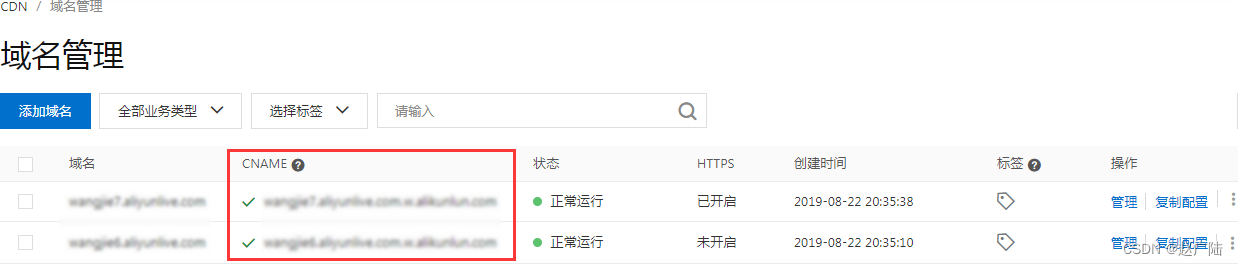
- 添加CNAME记录
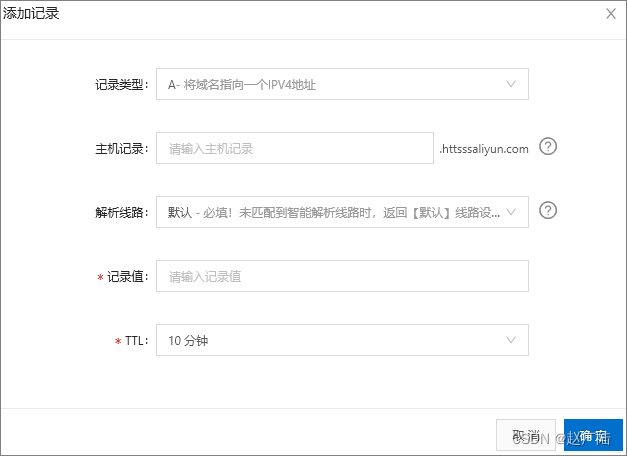
这里的记录值,填写上面的CNAME地址。
- 验证CNAME配置是否生效
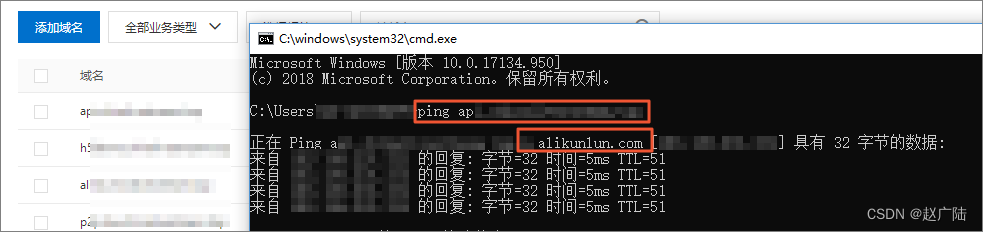
如果返回的解析结果和CDN控制台上该加速域名的CNAME值一致,则表示CDN加速已经生效。
6 CDN最佳实践方案
6.1 ECS源站加速
通过阿里云CDN实现ECS上静态资源加速, ECS上可存储的资源包括静态资源和动态资源。
访问ECS上的资源时,动态资源请求直接返回,静态资源通过CDN实现访问加速,由CDN节点返回。

操作步骤:
-
在CDN控制台上,添加ECS域名。
源站信息, 可以填写IP或源站域名
- 填写服务器外网IP,支持多个服务器外网IP。
- 填写源站域名,支持多个源站域名。
-
在CDN控制台上,获取CNAME值。
-
在DNS控制台上, 配置CNAME值。
-
通过PING命令,验证CNAME配置是否生效。
详细操作
6.2 OSS资源加速
-
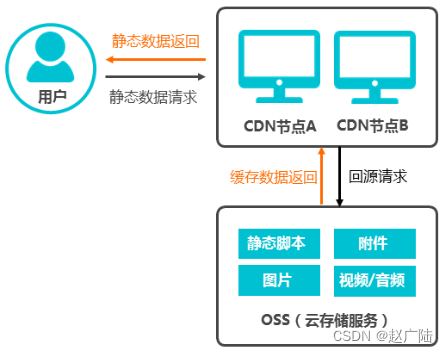
背景
OSS源站上存储的静态资源包括静态脚本、图片、附件等信息,当用户访问静态资源时,CDN对OSS源站上的静态资源进行加速,源站上的资源缓存到CDN的加速节点,系统自动调用离终端用户最近的CDN节点上已缓存的资源。加速OSS架构如下图所示。
-
方案优势:
- 用户访问网站资源,全部通过CDN,降低源站压力。
- 使用CDN流量,单价低于OSS直接访问外网流量。
- 资源从距离客户端最近的CDN节点获取,减少网络传输距离,保证静态资源质量。
-
操作配置:
-
在CDN控制台上,添加OSS域名, 并记录加速域名的CNAME值。
-
在阿里云云解析DNS控制台上,配置加速域名的CNAME值。
-
通过PING命令, 验证CNAME配置是否生效。
-
在OSS控制台上,打开加速域名的CDN缓存自动刷新开关。
执行本操作后,如果Object有更新,OSS会自动将更新后的Object刷新到CDN的缓存节点上,从而实现文件更新后实时刷新缓存的功能。
-
详细操作说明
6.3 CDN缓存命中率优化
-
背景
在实际应用中, 如果CDN缓存命中率低,则会导致源站压力大,静态资源访问效率低。
需要选择对应的优化策略,来提高CDN的缓存命中率。
CDN缓存命中率包括:
- 字节缓存命中率: CDN缓存命中响应的字节数 / CDN所有请求响应的字节数。
- 请求缓存命中率: CDN缓存命中的请求数 / CDN所有的请求数。
字节缓存命中率越低,回源流量越大,回源流量代表了源站服务器接收到的负载压力。
-
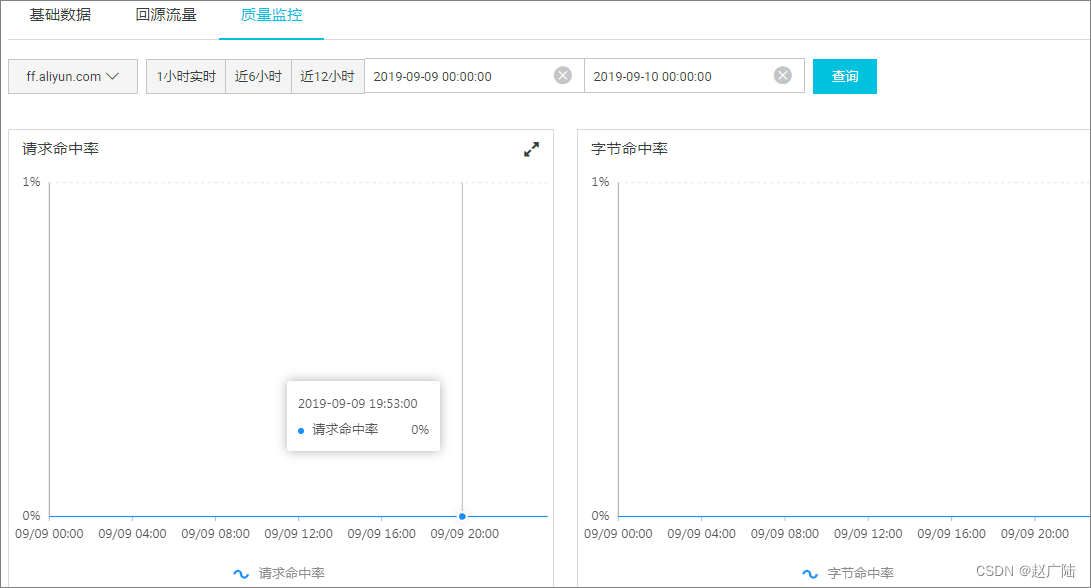
查看CDN缓存命中率
CDN控制台提供的缓存命中率监控是字节缓存命中率:
-
优化方案
-
预热URL
在业务高峰前预热热门资源,再次访问该资源时,直接从CDN节点获取,从而提升CDN的缓存命中率。
详细操作
-
配置资源缓存规则
当静态资源未返回响应头Etag或Last-modified时,缓存失败会导致CDN缓存命中率低,可以针对该资源配置缓存规则,提升缓存命中率。
详细操作
-
过滤URL中可变参数
当URL请求中带有queryString或其他可变参数时,资源重新回源,会导致CDN缓存命中率降低。
可以针对可变参数开启参数过滤功能,提升资源的缓存命中率。
详细操作
-