做电影网站用什么软件网络维护人员
线性渐变
liner-gradient属性值用来设置线性渐变,第一个参数值是方向,默认是从上往下,往后就是渐变颜色的种类。
background-image:liner-gradient(方向,颜色1,颜色2...) .box {display: flex;width: 400px;height: 400px;background: linear-gradient(orange,red);//backgournd可以设置所有背景属性}
方向设置:
- to+方位。首先我们可以使用to+方位改变位置,比如从下往上渐变,在颜色前面加上to top。我们还可以设置两个方位,这样就变成了对角线。
background: linear-gradient(to top right,orange,red);
- 角度表示。默认是从上往下,所以我们把中间分界线当成0deg,逆时针旋转90deg就是向右,这样子我们就可以用角度代表着方向,比如上面对角线我们可以写成
background: linear-gradient(45deg,orange,red);颜色设置:
颜色设置就是通用的三种方式:
- 英文单词。
- 16进制。
- rgba。如果我们想要加透明度,那么就用rgba设置,最后一个代表的就是透明度。
径向渐变:
radial-gradient用来设置径向渐变,不同线性方向,径向需要设置形状,大小。
background-image:radial-gradient(形状,大小,颜色1,颜色2...)默认从中心均匀地渐变。

形状设置
- 椭圆(默认值)。我们可以用ellipse将形状设置为椭圆。
- 圆形。用circle可以将形状变成圆。将上面的形状设置为圆如下:
background: radial-gradient(circle, orange, pink); 
大小设置
- closest-side:用来设置从中心到最近的边的渐变大小;
- closest-corner:用来设置从中心到最近的角的渐变大小;
- farthest-side:用来设置从中心到最远的边的渐变大小;
- farthest-corner:用来设置从中心到最远的角的渐变大小; 具体数值用百分比设置就可以。
background: radial-gradient(closest-side at 10% 10%, orange, pink);
重复渐变:
如果我们在线性渐变/径向渐变前面加上repeating就是重复渐变,重复渐变需要我们给颜色设置大小,具体可以用百分比或px来表示
background: repeating-linear-gradient(45deg,orange, red 100px);
锥形渐变:
渐变的方式可以指定百分比等或是角度deg,默认从中心往上的线开始,顺时针开始旋转渐变
(1)指定渐变开始点
background:conic-gradient(white 45deg, black 90deg,red 180deg);
45deg以前的区间为白色
90deg的地方不渐变,其他区间会和前后的元素产生渐变
180deg的地方不渐变,之前的区间会和前面的元素产生渐变,之后不渐变(2)只需要间断颜色,不需要渐变(设置起始点都为一个颜色,下一个颜色的起点为上一个的终点)
background:conic-gradient(
#500 0, #500 45deg,
#f00 45deg, #f00 90deg,
#f50 90deg, #f50 135deg,
#ff0 135deg,#ff0 180deg,
#0c0 180deg, #0c0 225deg,
#09d 225deg, #09d 270deg,
#00b 270deg, #00b 315deg,
#909 315deg, #909 360deg
);(3)重复锥形渐变
background:repeating-conic-gradient(颜色 渐变开始点,颜色2 渐变开始点2 ,...);
会根据0到最后一个渐变开始点的位置为一个整体,进行顺时针的重复填充

background:conic-gradient(#f00, #f50, #ff0, #0c0, #09d, #03a, #909, #f00);background:conic-gradient(#500 0, #500 45deg,#f00 45deg, #f00 90deg,#f50 90deg, #f50 135deg,#ff0 135deg,#ff0 180deg,#0c0 180deg, #0c0 225deg,#09d 225deg, #09d 270deg,#00b 270deg, #00b 315deg,#909 315deg, #909 360deg
);
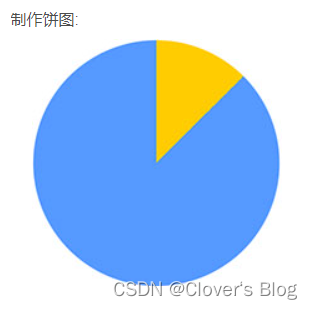
div{width:200px;height:200px;border-radius:50%;background:conic-gradient(#fc0 0, #fc0 45deg,#59f 45deg);
}

background:repeating-conic-gradient(#f00 0, #f00 15deg,#fa0 15deg,#fa0 30deg);