洛阳市住房与城乡建设部网站秀洲区住房和城乡建设局网站
一、自动化测试基本介绍
1 自动化测试概述:
什么是自动化测试?一般说来所有能替代人工测试的方式都属于自动化测试,即通过工具和脚本来模拟人执行用例的过程。
2 自动化测试的作用
减少软件测试时间与成本改进软件质量
通过扩大测试覆盖率加强测试工作
进行手动测试难以完成的、需要更高的成本、更长的计划、更高的质量的任务
迭代更新较少,但仍需测试人员维护的,通过自动化解放人力
3 自动化测试的主要应用:
冒烟测试(主业务流程)
回归测试
性能测试
兼容性测试 (一套测试脚本,多个平台执行)
完成手动测试无法完成的工作下班后无人值守测试
4 web自动化实现的目标:
(一)原则:
编写自动化测试用例库,根据用例库里面的用例编写测试用例。
提高测试效率,降低测试成本
重复性较强的用例用自动化实现
快速的回归测试,提高版本发布的速度和质量
功能覆盖率达到要求
测试具有移植性和可重复性
(二)实施策略(持续集成):
框架的选择
环境搭建
case编写:提取公共模块、提取公共参数、功能逻辑熟悉
log输出
报告输出
Jenkins持续集成:定时集成、发送邮件
二、Web自动化工具
1 web自动化工具的选择:
市场上自动化工具分为开源和和商用付费两种,下面提供两种类型主流的selenium和QTP对比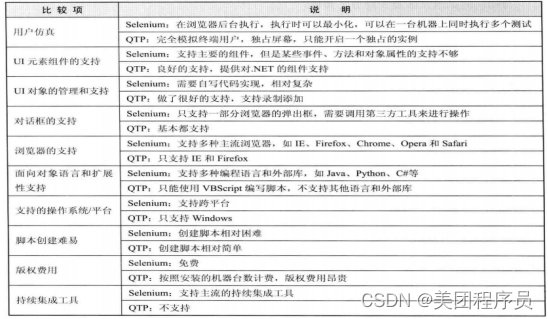
最终选择:selenium+IDEA(java+maven+testng)+jenkins
三、Selenium介绍
(一)selenium 测试原理:
在自动化测试过程中,存在三部分组件:客户端脚本+浏览器驱动+浏览器终端。
驱动文件,以geckodriver.exe为例,这个可执行的驱动文件启动后,相当于一个暴露了一系列接口的服务器,监听某一端口。
客户端的操作(访问页面,定位元素,输入数据,点击按钮等)都是封装成了接口请求(eg:/session/xx/yy),然后提交到驱动服务器。
驱动服务器接收到客户端的请求后,再跟终端浏览器交互。
终端浏览器做出相应操作(操作元素、甚至浏览器本身:截屏、窗口、安装插件证书)。
(二)selenium 工具套件简单介绍
Selenium WebDriver:面向对象API。
Selenium IDE(集成开发环境):FireFox插件,用于提供图形化界面来录制和回放脚本,插件只是用来模拟原型的工具,并不希望测试工程师使用此工具用来运行大批量的测试脚本。此插件需要使用第三方的javaScript代码库才能支持循坏和条件判断
Selenium-Grid可以在多个测试环境以并发的方式执行测试脚本,实现脚本的并发执行,缩短大量测试脚本的执行时间。
四、Selenium WebDriver常用API
(一)selenium WebDriver常用基础API
(一) 浏览器操作
加载浏览器驱动,打开页面:
driver = new FirefoxDriver();
String baseUrl = "http://oa2.midairen.com/index.html";
driver.get(baseUrl);
关闭浏览器:
driver.close();//关闭浏览器
最大化窗口:
driver.manage().window().maximize();
后退到前一页:
driver.navigate().back();
前进到后一页:
driver.navigate().forward();
刷新页面:
driver.navigate().refresh();
获得title并打印
String title =driver.getTitle();
杀掉Windows的浏览器进程
当前浏览器窗口截屏(比较截屏)
操作浏览器的cookie
(二) 页面操作
获取页面的源代码
获取页面的URL地址
在输入框中清除原有的文字
在输入框中输入指定内容
单击按钮
双击某个元素
操作单选下拉列表
操作单选框
操作复选框
检查元素文本内容是否出现
执行JS脚本
操作iframe中的页面元素
操作富文本
(三) 元素定位的方法:
五、TestNG
(一)TestNG基本介绍:
TestNG是Java中的一个测试框架,是一个目前很流行实用的单元测试框架,有完善的用例管理模块,配合Maven能够很方便管理依赖第三方插件。使用TestNG可以做功能、接口、单元、集成的自动化测试,最常见的是结合selenium做功能自动化测试,它使用Java注释去写测试方法。
测试人员一般用TestNG来写自动化测试,开发人员一般用Junit写单元测试,TestNG适合测试人员使用的主要原因:TestNG更适合复杂的集成测试。
(二) testNG的特点:
注解
TestNG使用Java和面向对象的功能
支持综合类测试(例如,默认情况下,没有必要创建一个新的测试来作为每个测试方法的类的实例)
独立的编译时间测试代码运行时配置/数据信息
灵活的运行时配置
支持依赖测试方法,并行测试,负载测试,局部故障
灵活的插件API
支持多线程测试
(三) 注解:
TestNG常用的测试用例组织结构由test Suite-test-测试class-测试方法。Test suite有一个或者多个test组成,test由一个或者多个测试class组成,一个测试class有一个或者多个测试方法组成。运用不同层级的测试用例时,课通过不同注解实现测试前的初始化工作,测试用例执行工作和测试后的清理工作。
常用注解如下:

(四) 依赖测试
某些复杂的测试场景需要按照某个特定的顺序执行测试用例,一以此保证某个特定顺序执行测试用例,此测试场景运行需求称为依赖测试。通过依赖测试,不同的测试方法间共享数据和程序状态。使用dependsOnMethods参数 实现。
@Test(dependsOnMethods = {"testcase1"})
(五) 断言
在执行自动化测试用例的时候,我们需要自动判断用例执行完成后获得的输出值是否与预期值一致,这个时候就需要用到断言功能。TestNG中提供了一个Assert类:org.testng.AsserTestNG中提供了一个Assert类,org.testng.Assert类是作为放置一系列断言的静态方法的容器。
Assert.assertTrue(select1.isDisplayed());//断言判断select1元素是否在页面存在
常用的断言:
assertTrue:判断是否为true。
AssertFALSE:判断是否为FALSE。
AssertNull:判断是否为空
AssertNoNull:判断是否不为空
AssetEquals:判断是否相等
AssertNoEquals:判断是否不相等