湘潭做网站电话磐石网络青海教育厅门户网站
引言
Java作为一门广泛应用于企业级开发的编程语言,对初学者来说可能会感到有些复杂。然而,通过适当的学习方法和资源,即使是小白也可以轻松掌握Java的基础知识。本文将提供一些有用的建议和资源,帮助小白自学Java基础。
学习步骤
1、理解基本概念
在开始学习Java之前,了解一些基本概念是非常重要的。理解面向对象编程(OOP)的概念、变量、数据类型、流程控制语句以及函数等基础知识,将有助于你更好地理解Java编程语言。
2. 学习Java语法
掌握Java的语法是学习Java编程的关键。学习Java核心概念,如类、对象、继承、多态等。同时,学习掌握Java中的常用语法元素,如变量声明、运算符、条件语句、循环语句以及异常处理。
3. 编写简单程序
为了加深对Java语法的理解,从简单的程序开始编写。例如,编写一个打印"Hello, World!"的程序或者计算两个数字之和的程序。通过实践来巩固所学的知识。
4. 阅读相关教程和文档
借助丰富的在线资源,如CSDN上的Java教程、博客和文档,加深对Java的理解。这些教程通常会提供示例代码和详细解释,帮助你更好地学习和掌握Java的各个方面。
5. 参与编程社区
加入一些活跃的Java编程社区,例如CSDN论坛或Stack Overflow,可以向经验丰富的开发者寻求帮助和建议。在这些社区上与其他学习者互动,分享问题和解决方案,相互学习和进步。
6. 实践项目
参与一些简单的实践项目,将所学的知识应用到实际中。尝试解决一些问题,编写小型应用程序,并逐渐增加难度。通过实践来提高自己的编程能力和理解深度。
自学知识点
如下图:
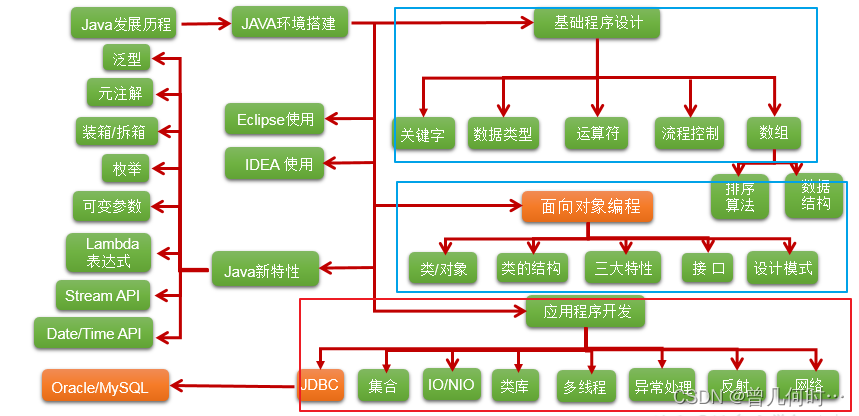

1.Java语言概述
Java语言版本迭代概述:
1991年 Green项目,开发语言最初命名为Oak (橡树)
1994年,开发组意识到Oak 非常适合于互联网
1996年,发布JDK 1.0,约8.3万个网页应用Java技术来制作
1997年,发布JDK 1.1,JavaOne会议召开,创当时全球同类会议规模之最
1998年,发布JDK 1.2,同年发布企业平台J2EE
1999年,Java分成J2SE、J2EE和J2ME,JSP/Servlet技术诞生
2004年,发布里程碑式版本:JDK 1.5,为突出此版本的重要性,更名为JDK 5.0
2005年,J2SE -> JavaSE,J2EE -> JavaEE,J2ME -> JavaME
2009年,Oracle公司收购SUN,交易价格74亿美元
2011年,发布JDK 7.0
2014年,发布JDK 8.0,是继JDK 5.0以来变化最大的版本
2017年,发布JDK 9.0,最大限度实现模块化
2018年3月,发布JDK 10.0,版本号也称为18.3
2018年9月,发布JDK 11.0,版本号也称为18.9
Java语言应用的领域:
>Java Web开发:后台开发
>大数据开发:
>Android应用程序开发:客户端开发
Java语言的特点
> 面向对象性:
两个要素:类、对象
三个特征:封装、继承、多态
> 健壮性:① 去除了C语言中的指针 ②自动的垃圾回收机制 -->仍然会出现内存溢出、内存泄漏
> 跨平台型:write once,run anywhere:一次编译,到处运行
功劳归功于:JVM
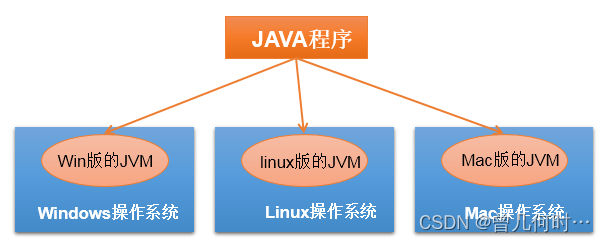
2.开发环境搭建 (重点)
JDK、JRE、JVM的关系
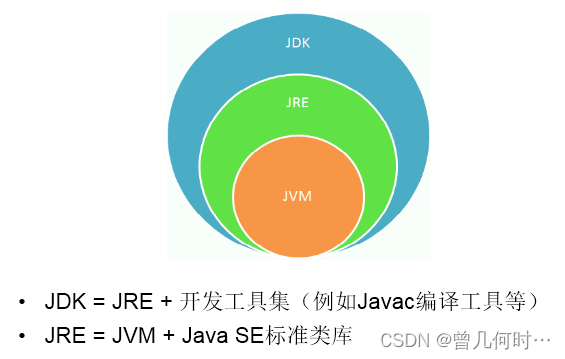
JDK的下载、安装
下载:Oracle | Cloud Applications and Cloud Platform
安装:傻瓜式安装:JDK 、JRE
注意问题:安装软件的路径中不能包含中文、空格。
path环境变量的配置
path环境变量:windows操作系统执行命令时所要搜寻的路径
为什么要配置path:希望java的开发工具(javac.exe,java.exe)在任何的文件路径下都可以执行成功。
如何配置?

3.Java程序——HelloWorld
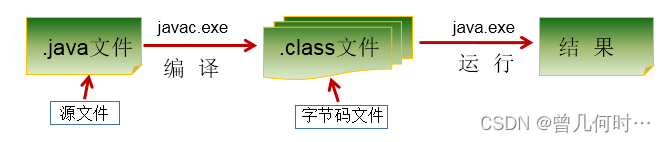
需要先创建一个txt文件,命名为HelloWorld

进入txt文件写入代码:
class HelloWorld{public static void main(String[] args){System.out.println("Hello,World!");}
}输入完成后进行修改后缀:

最后按Win+R输入cmd回车进入命令窗口输入DOS命令进入Java文件目录
常用的DOS命令:

进入根目录首先编译:
javac HelloWorld.java
编译完成后进行运行:
java HelloWorld
常见问题

 总结
总结
1.java程序编写-编译-运行的过程
编写:我们将编写的java代码保存在以".java"结尾的源文件中
编译:使用javac.exe命令编译我们的java源文件。格式:javac 源文件名.java
运行:使用java.exe命令解释运行我们的字节码文件。 格式:java 类名
2.在一个java源文件中可以声明多个class。但是,只能最多有一个类声明为public的。
而且要求声明为public的类的类名必须与源文件名相同。
3. 程序的入口是main()方法。格式是固定的。
4. 输出语句:
System.out.println():先输出数据,然后换行
System.out.print():只输出数据
5.每一行执行语句都以";"结束。
6.编译的过程:编译以后,会生成一个或多个字节码文件。字节码文件的文件名与java源文件中的类名相同。
4.注释与API文档等
1.注释:Comment
分类:
单行注释://
多行注释:/* */
文档注释:/** */
作用:
① 对所写的程序进行解释说明,增强可读性。方便自己,方便别人
② 调试所写的代码
特点:
①单行注释和多行注释,注释了的内容不参与编译。
换句话说,编译以后生成的.class结尾的字节码文件中不包含注释掉的信息
② 注释内容可以被JDK提供的工具 javadoc 所解析,生成一套以网页文件形式体现的该程序的说明文档。
③ 多行注释不可以嵌套使用
2.Java API 文档:
API:application programming interface。习惯上:将语言提供的类库,都称为api.
API文档:针对于提供的类库如何使用,给的一个说明书。类似于《新华字典》
3.良好的编程风格

5.关键字与标识符
1.java关键字的使用
定义:被Java语言赋予了特殊含义,用做专门用途的字符串(单词)
特点:关键字中所字母都为小写
具体哪些关键字如下图:
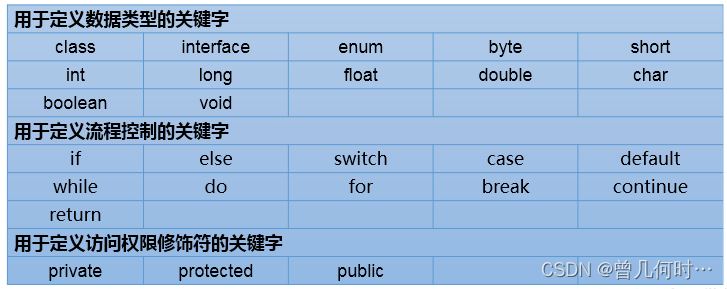

2.保留字:现Java版本尚未使用,但以后版本可能会作为关键字使用。
具体哪些保留字:goto 、const
注意:自己命名标识符时要避免使用这些保留字
3.标识符的使用
定义:凡是自己可以起名字的地方都叫标识符。
涉及到的结构:
包名、类名、接口名、变量名、方法名、常量名
规则:(必须要遵守。否则,编译不通过)

规范:(可以不遵守,不影响编译和运行。但是要求大家遵守)

注意点:
在起名字时,为了提高阅读性,要尽量意义,“见名知意”。
6.变量的使用(重点)
1.变量的分类
1.1 按数据类型分类
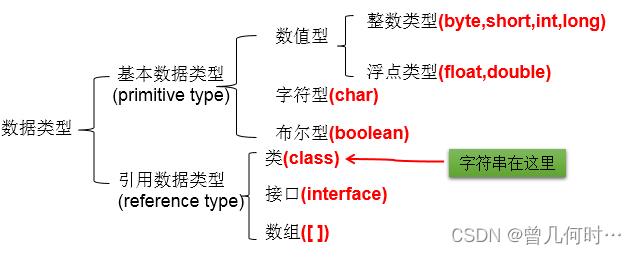
详细说明:
1. 整型:byte(1字节=8bit) \ short(2字节) \ int(4字节) \ long(8字节)
① byte范围:-128 ~ 127
② 声明long型变量,必须以"l"或"L"结尾
③ 通常,定义整型变量时,使用int型。
④整型的常量,默认类型是:int型
2. 浮点型:float(4字节) \ double(8字节)
① 浮点型,表示带小数点的数值
② float表示数值的范围比long还大
③ 定义float类型变量时,变量要以"f"或"F"结尾
④ 通常,定义浮点型变量时,使用double型。
⑤ 浮点型的常量,默认类型为:double
3. 字符型:char (1字符=2字节)
① 定义char型变量,通常使用一对'',内部只能写一个字符
② 表示方式:1.声明一个字符 2.转义字符 3.直接使用 Unicode 值来表示字符型常量
4.布尔型:boolean
① 只能取两个值之一:true 、 false
② 常常在条件判断、循环结构中使用
1.2 按声明的位置分类(了解)

2.定义变量的格式:
数据类型 变量名 = 变量值;
或
数据类型 变量名;
变量名 = 变量值;
3.变量使用的注意点:
① 变量必须先声明,后使用
② 变量都定义在其作用域内。在作用域内,它是有效的。换句话说,出了作用域,就失效了
③ 同一个作用域内,不可以声明两个同名的变量
4.基本数据类型变量间运算规则
4.1 涉及到的基本数据类型:除了boolean之外的其他7种
4.2 自动类型转换(只涉及7种基本数据类型)
结论:当容量小的数据类型的变量与容量大的数据类型的变量做运算时,结果自动提升为容量大的数据类型。
byte 、char 、short --> int --> long --> float --> double
特别的:当byte、char、short三种类型的变量做运算时,结果为int型
说明:此时的容量大小指的是,表示数的范围的大和小。比如:float容量要大于long的容量
4.3 强制类型转换(只涉及7种基本数据类型):自动类型提升运算的逆运算。
1.需要使用强转符:()
2.注意点:强制类型转换,可能导致精度损失。
4.4 String与8种基本数据类型间的运算
1. String属于引用数据类型,翻译为:字符串
2. 声明String类型变量时,使用一对""
3. String可以和8种基本数据类型变量做运算,且运算只能是连接运算:+
4. 运算的结果仍然是String类型
避免:
String s = 123;//编译错误
String s1 = "123";
int i = (int)s1;//编译错误
7.运算符
1.算术运算符: + - + - * / % (前)++ (后)++ (前)-- (后)-- +
【典型代码】
//除号:/int num1 = 12;int num2 = 5;int result1 = num1 / num2;System.out.println(result1);//2 // %:取余运算//结果的符号与被模数的符号相同//开发中,经常使用%来判断能否被除尽的情况。int m1 = 12;int n1 = 5;System.out.println("m1 % n1 = " + m1 % n1);int m2 = -12;int n2 = 5;System.out.println("m2 % n2 = " + m2 % n2);int m3 = 12;int n3 = -5;System.out.println("m3 % n3 = " + m3 % n3);int m4 = -12;int n4 = -5;System.out.println("m4 % n4 = " + m4 % n4);//(前)++ :先自增1,后运算//(后)++ :先运算,后自增1int a1 = 10;int b1 = ++a1;System.out.println("a1 = " + a1 + ",b1 = " + b1);int a2 = 10;int b2 = a2++;System.out.println("a2 = " + a2 + ",b2 = " + b2);int a3 = 10;++a3;//a3++;int b3 = a3;//(前)-- :先自减1,后运算//(后)-- :先运算,后自减1int a4 = 10;int b4 = a4--;//int b4 = --a4;System.out.println("a4 = " + a4 + ",b4 = " + b4);【特别说明的】
1.//(前)++ :先自增1,后运算
//(后)++ :先运算,后自增1
2.//(前)-- :先自减1,后运算
//(后)-- :先运算,后自减1
3.连接符:+:只能使用在String与其他数据类型变量之间使用。
2.赋值运算符:= += -= *= /= %=
【典型代码】
int i2,j2;//连续赋值i2 = j2 = 10;//***************int i3 = 10,j3 = 20;int num1 = 10;num1 += 2;//num1 = num1 + 2;System.out.println(num1);//12int num2 = 12;num2 %= 5;//num2 = num2 % 5;System.out.println(num2);short s1 = 10;//s1 = s1 + 2;//编译失败s1 += 2;//结论:不会改变变量本身的数据类型System.out.println(s1);【特别说明的】
1.运算的结果不会改变变量本身的数据类型
2.
开发中,如果希望变量实现+2的操作,有几种方法?(前提:int num = 10;)
方式一:num = num + 2;
方式二:num += 2; (推荐)
开发中,如果希望变量实现+1的操作,有几种方法?(前提:int num = 10;)
方式一:num = num + 1;
方式二:num += 1;
方式三:num++; (推荐)
3.比较运算符(关系运算符): == != > < >= <= instanceof
【典型代码】
int i = 10;int j = 20;System.out.println(i == j);//falseSystem.out.println(i = j);//20boolean b1 = true;boolean b2 = false;System.out.println(b2 == b1);//falseSystem.out.println(b2 = b1);//true【特别说明的】
1.比较运算符的结果是boolean类型
2.> < >= <= :只能使用在数值类型的数据之间。
3. == 和 !=: 不仅可以使用在数值类型数据之间,还可以使用在其他引用类型变量之间。
Account acct1 = new Account(1000);
Account acct2 = new Account(1000);
boolean b1 = (acct1 == acct2);//比较两个Account是否是同一个账户。
boolean b2 = (acct1 != acct2);//
4.逻辑运算符:& && | || ! ^
【典型代码】
//区分& 与 &&//相同点1:& 与 && 的运算结果相同//相同点2:当符号左边是true时,二者都会执行符号右边的运算//不同点:当符号左边是false时,&继续执行符号右边的运算。&&不再执行符号右边的运算。//开发中,推荐使用&&boolean b1 = true;b1 = false;int num1 = 10;if(b1 & (num1++ > 0)){System.out.println("我现在在北京");}else{System.out.println("我现在在南京");}System.out.println("num1 = " + num1);boolean b2 = true;b2 = false;int num2 = 10;if(b2 && (num2++ > 0)){System.out.println("我现在在北京");}else{System.out.println("我现在在南京");}System.out.println("num2 = " + num2);
// 区分:| 与 || //相同点1:| 与 || 的运算结果相同//相同点2:当符号左边是false时,二者都会执行符号右边的运算//不同点3:当符号左边是true时,|继续执行符号右边的运算,而||不再执行符号右边的运算//开发中,推荐使用||boolean b3 = false;b3 = true;int num3 = 10;if(b3 | (num3++ > 0)){System.out.println("我现在在北京");}else{System.out.println("我现在在南京");}System.out.println("num3 = " + num3);boolean b4 = false;b4 = true;int num4 = 10;if(b4 || (num4++ > 0)){System.out.println("我现在在北京");}else{System.out.println("我现在在南京");}System.out.println("num4 = " + num4);【特别说明的】
1.逻辑运算符操作的都是boolean类型的变量。而且结果也是boolean类型
5.位运算符:<< >> >>> & | ^ ~
【典型代码】
int i = 21;i = -21;System.out.println("i << 2 :" + (i << 2));System.out.println("i << 3 :" + (i << 3));System.out.println("i << 27 :" + (i << 27));int m = 12;int n = 5;System.out.println("m & n :" + (m & n));System.out.println("m | n :" + (m | n));System.out.println("m ^ n :" + (m ^ n));
【面试题】 你能否写出最高效的2 * 8的实现方式?
答案:2 << 3 或 8 << 1
【特别说明的】
1. 位运算符操作的都是整型的数据
2. << :在一定范围内,每向左移1位,相当于 * 2
>> :在一定范围内,每向右移1位,相当于 / 2
典型题目:
1.交换两个变量的值。
2.实现60的二进制到十六进制的转换
6.三元运算符:(条件表达式)? 表达式1 : 表达式2
【典型代码】
1.获取两个整数的较大值
int num1 = 10;
int num2 = 20;int max = (num1 > num2) ? num1 : num2;
System.out.println("较大值是:" + max);
说明:在上面的代码中,我们首先声明了两个整数变量num1和num2,然后使用三元表达式来比较这两个变量的大小。如果num1大于num2,则将num1赋值给max变量;否则,将num2赋值给max变量。最后,我们通过打印语句输出较大值。
你可以根据实际情况更改num1和num2的值,并进行测试。
2.获取三个数的最大值
int max = (a > b) ? ((a > c) ? a : c) : ((b > c) ? b : c);
说明:上述代码假设有三个整数变量a,b和c,并将最大值存储在变量max中。它通过比较a和b的大小,然后再比较结果与c的大小,从而确定最大值。
这是一个简单的示例,如果要使用更多的数字进行比较,则需要根据需要扩展表达式。
【特别说明的】
1. 说明
① 条件表达式的结果为boolean类型
② 根据条件表达式真或假,决定执行表达式1,还是表达式2.
如果表达式为true,则执行表达式1。
如果表达式为false,则执行表达式2。
③ 表达式1 和表达式2要求是一致的。
④ 三元运算符可以嵌套使用
2.
凡是可以使用三元运算符的地方,都可以改写为if-else
反之,不成立。
3. 如果程序既可以使用三元运算符,又可以使用if-else结构,那么优先选择三元运算符。原因:简洁、执行效率高。