网站首页设计html代码wordpress微信分享图片不显示图片
邀请函
这是一个友好的邀请。无论你是数据领域的专家、学生还是爱好者,我们都欢迎你加入这个平台。这不仅仅是一场比赛,更是一个交流、学习和展示自己的机会。
丰厚奖金:我们为参赛者准备了总计15W+的奖金池,期待你的才华在这里得到认可与回报。
荣誉证书:获奖者将获得一份具有重量的荣誉证书。该证书将附有6家江西省直厅级单位的公章认证,这是一份全国罕见、含金量极高的证书。
发展机会:此外,参赛者还有机会与业界领先公司接轨,更有可能进入江西省大数据人才库,开启职业生涯的新篇章。
为何参与:在这里,你可以学到新知识,结识志同道合的朋友,并挑战自己。往届参赛者都觉得这是一次宝贵的经历。
分享给他人:如果这次大赛与你的专业不完全匹配,也许你身边的朋友或家人会感兴趣。请考虑分享给他们。
⌛ 立即行动:点击链接:
https://data.jiangxi.gov.cn/jxoda/
了解更多信息和报名方式。
感谢关注:期待你的参与,一起学习,一起成长!
自2020年起,江西省已经连续举办三届江西开放数据创新应用大赛,引导和鼓励社会各界开放数据、分析数据、挖掘数据价值。三届比赛共吸引全国2000多支队伍报名参赛,参赛人数达5200余人,其中来自高校的占38%,企业占15%,个人占47%。这些来自各领域的参赛队伍精心创作、同台竞技,为大赛呈现了1000多件优秀作品。今年,全新的江西开放数据创新应用大赛如期而至,与往届相比,本届比赛有“五大升级”。
一、赛事环节更加全面
为了发掘更多新颖的数据创新作品,推动大赛成为数据开发利用人才成长的训练场,本届大赛在初赛、决赛基础上增设了复赛环节,并优化高校宣讲、赛事培训和作品推广等环节,通过增加赛制,延长比赛时间,让参赛队伍有更多展示的机会,促进参赛选手在比赛中学习煅烧,在实战中提升技能,实现与大赛共成长。
二、赛道设计更具挑战
本届大赛设立了创新创意和场景应用两个赛道:
创新创意赛道侧重挖掘各领域数据赋能的解决方案。该赛道不提供参赛数据,设置四个比赛方向,分别是:聚焦促进绿色经济和生态文明建设的“数字生态”方向;聚焦提升文化体育旅游业服务效率和个性化的“数字文旅”方向;聚焦赋能农业现代化和乡村振兴的“数字乡村”方向,以及聚焦融合各领域社会数据提出数字化社会解决方案的“数字社会”方向。
场景应用赛道侧重解决各行业真实场景需求。参赛选手需要按照赛题要求和给定数据,寻找最佳解决方案。赛道设置四个赛题,分别是:聚焦政府电子卖场运营策略优化的“电商优化”赛题;基于电视节目“金牌调解”数据进行深度分析的“视频挖掘”赛题;构建智能化、精准化医院管理策略的“智慧医管”赛题;以及融合创新思维和实践应用的“数据实践”赛题。
上述赛题设计,均与省内大型医院、知名电视台以及交通、电力、民生等行业企业的深度沟通,确保具有实现意义、应用价值和江西特色。

三、赛事培训更为专业
本届大赛将分阶段开展一系列赛事沙龙活动,包括:举办高校线下宣传讲座;开展线上赛题解读培训会;建立赛事交流社群;汇总解答赛事相关问题;邀请行业数据专家进行知识分享等。通过多维度赛事培训活动,让本届大赛更加精彩。
四、官网功能更加实用
通过对比赛官网进行升级,提供更为实用的功能。一是增加赛题热度功能,实时展示各赛题报名队伍数量,避免参赛队伍扎堆。二是增加参赛记录查询和证明系统,方便参赛选手快速查询验证往届参赛记录和成绩。三是增加赛事培训模块,提供各类培训资源供选手学习。四是优化往届赛事模块,网站将呈现往届优秀作品和获奖队伍的经验分享,记录每届大赛精彩内容。
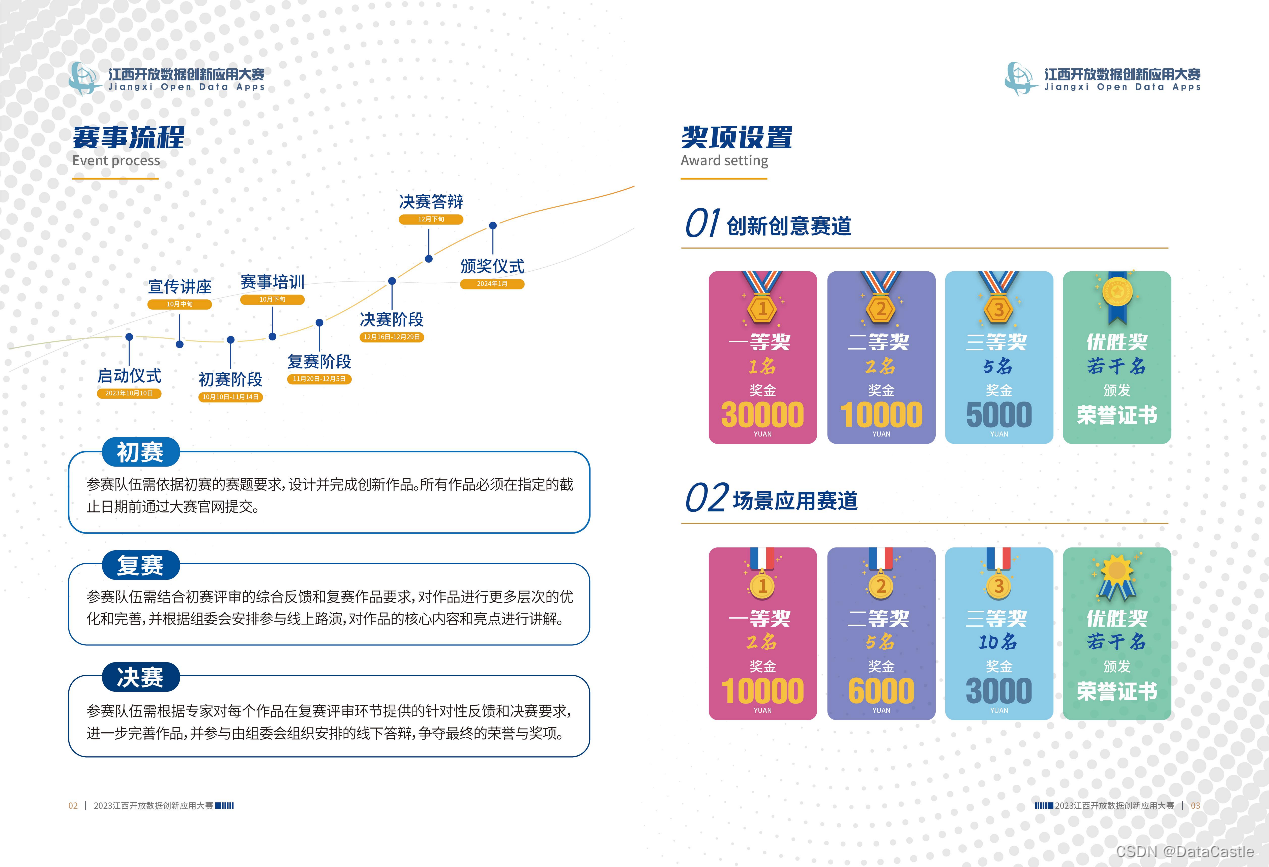
五、奖励体系更为丰富
创新应用赛道设有一等奖1名,奖金3万元;二等奖2名,奖金各1万元;三等奖5名,奖金各5千元。为促进作品推广转化,预留40%奖金,待作品落地孵化后发放。场景应用赛道设有一等奖2名,奖金各1万元;二等奖5名,奖金各6千元;三等奖10名,奖金各3千元。通过增加本赛道获奖名额,吸引更多选手参赛。此外,大赛还设有指导奖、组织奖,颁发给获奖队伍所属单位。为加强作品宣传推广,本届比赛将对优秀作品整理并集结成册,以促进优秀作品转化商用。
大赛报名
报名方式与往届一致:大赛面向全国高校师生、科研机构、互联网企业和创客团队开放。参赛者年满16周岁,以实名方式登陆官网报名。可单人或与他人组织至多5人的队伍参赛。关于赛事的更多信息,欢迎大家进入大赛官网了解。
官网链接:https://data.jiangxi.gov.cn/jxoda/
关于大赛
2023(第四届)开放数据创新应用大赛由江西省发展和改革委员会、中共江西省委网络安全和信息化委员会办公室、江西省教育厅、江西省工业和信息化厅、江西省政务服务管理办公室、赣江新区管理委员会共同指导;由江西省大数据中心与赣江新区创新发展局共同主办;同时江西省信息协会、云上(江西)大数据发展有限公司、思创数码科技股份有限公司等机构共同承办,确保了赛事的专业性与广泛性。。
本届大赛以“融合创新应用 智绘数字赣鄱”为主题,聚焦数字化热点场景和需求,联合省市多部门打造江西数据赛事品牌和数据创新应用高地。大赛旨在吸引社会各界参与数据活动、分析数据规律、挖掘数据价值、创作数据产品、共享数据便利,共同推动数据开放流通和开发利用,为壮大数据创新主体和数字经济发展作出贡献。
