订阅号上链接的网站怎么做的做教育网站宣传策略
文章目录
- 一、类和对象
- 1. 类的定义
- 2. 对象的使用
- 二、对象内存图
- 三、成员变量和局部变量
- 四、封装
- 1. private 关键字
- 2. this 关键字
- 五、构造方法
- 六、标准类制作
一、类和对象
在此之前,我们先了解两个概念,对象和类。
万物皆对象,客观存在的事物皆为对象。
类是对象的数据类型,是对现实生活中一类具有共同属性和行为的事物的抽象。
类是对象的抽象,对象是类的实体!
1. 类的定义
类是 Java 程序的基本组成单位。
是对现实生活中一类具有共同属性和行为的事物的抽象,确定对象将会拥有的属性和行为。
① 属性:在类中通过成员变量来体现(类中方法外的变量);
② 行为:在类中通过成员方法来体现(和前面的方法相比去掉 static 关键字即可)。
public class Phone {//成员变量String brand;int price;//成员方法public void call() {System.out.println("打电话");}public void sendMessage() {System.out.println("发短信");}
}
2. 对象的使用
① 创建对象
Phone p = new Phone();
② 使用对象
//使用成员变量
p.brand;
//使用成员方法
p.call();
public class PhoneDemo {public static void main(String[] args) {//创建对象Phone p = new Phone();//给成员变量赋值p.brand = "华为";p.price = "2999";//使用成员变量System.out.println(p.brand);System.out.println(p.price);//使用成员方法p.call();p.sendMessage();}
}
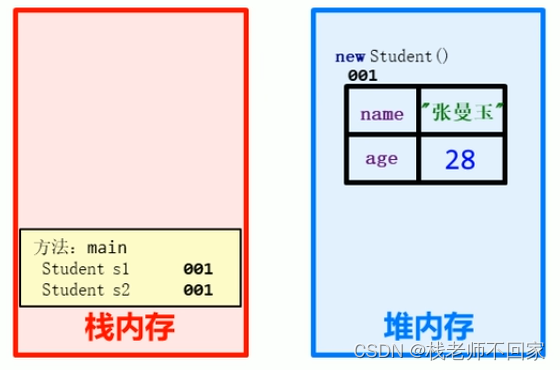
二、对象内存图
public class StudentTest {public static void main(String[] args) {//创建第一个对象并使用Student s1 = new Student();s1.name = "林青霞";s1.age = 30;System.out.println(s1.name + "," + s1.age);//把第一个对象的地址赋值给第二个对象Student s2 = s1;s2.name = "张曼玉";s2.age = 28;System.out.println(s1.name + "," + s1.age);System.out.println(s2.name + "," + s2.age);}
}
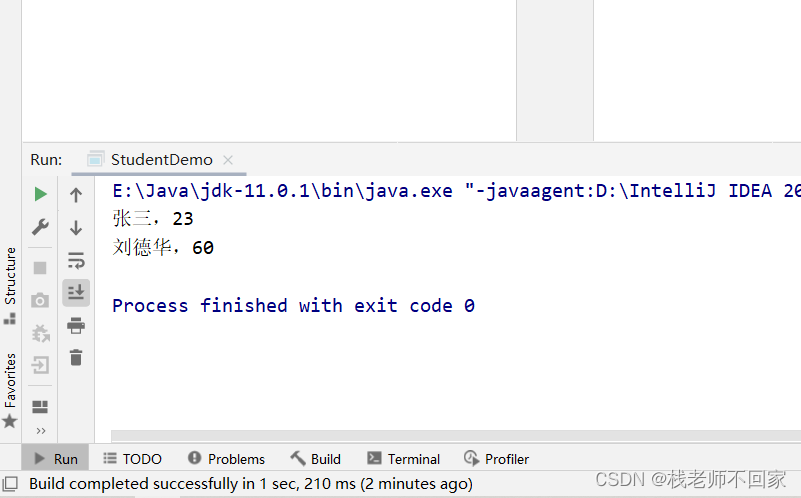
输出:
林青霞,30
张曼玉,28
张曼玉,28
多个对象指向相同的地址!
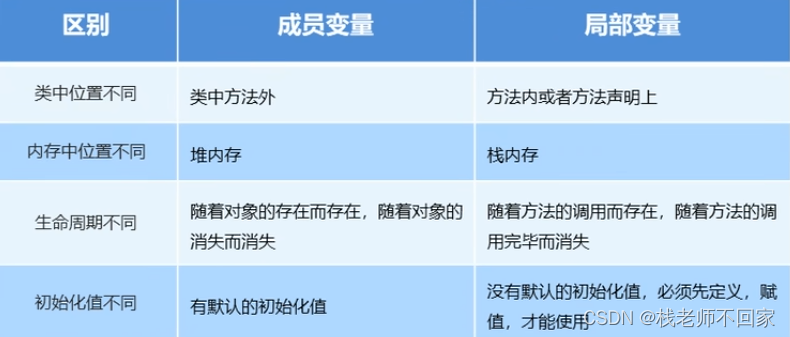
三、成员变量和局部变量
成员变量:类中方法外的变量;
局部变量:方法中的变量。
public class Phone {String brand;int price;public void call() {int i = 0;System.out.println("打电话");}public void sendMessage() {int j = 0;System.out.println("发短信");}int k;
}
如上代码,其中 brand、price 和 k 是成员变量,i 和 j 是局部变量。
成员变量和局部变量的区别:
四、封装
1. private 关键字
① 是一个权限修饰符;
② 可以修饰成员变量和成员方法;
③ 作用是保护成员不被别的类使用,被 private 修饰的成员只在本类中才能被访问。
针对 private 修饰的成员变量,如果需要被其他类使用,应提供相应的操作:
(1)提供 get变量名() 方法,用于获取成员变量的值,方法用 public 修饰;
(2)提供 set变量名(参数) 方法,用于设置成员变量的值,方法用 public 修饰。
//学生类
public class Student {String name;private int age;//提供get、set方法public void setAge(int a) {if (a < 0 || a > 120) {System.out.println("年龄不正确!");} else {age = a;} }public int getAge() {return age;}public void show() {System.out.println(name + "," + age);}
}
//学生测试类
public class StudentTest {public static void main(String[] args) {//创建对象Student s = new Student();//给成变量赋值s1.name = "刘德华";s1.setAge(60);//调用show方法s.show();}
}
一个标准类的编写:
① 把成员变量用 private 修饰;
② 提供对应的 get、set 方法。
set、get 后面单词首字母要大写!
2. this 关键字
private String name;
private int age;
public void setName(String name) {this.name = name;
}
public String getName() {return name;
}
public void setAge(int age) {this.age = age;
}
public int getAge() {return age;
}public void show() {System。out.println(name + "," + age);
}
局部变量与成员变量同名时,this 修饰的变量用于指代成员变量,this.age = age 左成员右局部!
(1)封装原则:
将类的某些信息隐藏在类内部,不允许外部程序直接访问,而是通过该类提供的方法来实现对隐藏信息的操作和访问。
(2)封装好处:
通过方法来控制成员变量的操作,提高了代码的安全性,把代码用方法进行封装,提高了代码的复用性。
五、构造方法
构造方法是一种特殊的方法,用于创建对象。
private String name;
private int age;public Student() {
}public void show() {System.out.println(name + "," + age);
}Student s = new Student();
s1.setName("刘德华");
s1.setAge(60);
s1.show(); //刘德华,60
当一个类中没有给任何的构造方法时,系统将会自动给出一个默认的无参构造方法,这就是为什么我们前面即使没写构造方法,程序也可以正常执行。
但是当需要传递参数时,系统将无法给出我们有参构造,需要自己去写:
private String name;
private int age;public Student(String name, int age) {this.name = name;this.age = age;
}public void show() {System.out.println(name + "," + age);
}
Student s = new Student("刘德华", 60);
s.show(); //刘德华,60
注意事项:
① 如果没有定义构造方法,系统将给出一个默认的无参构造方法;
② 如果定义了构造方法,系统将不再提供默认的构造方法;
③ 如果自定义了带参构造方法,还需要使用无参构造方法时,就必须再写一个无参构造方法;
④ 推荐使用方式,无论是否使用,都手动书写无参构造方法。
六、标准类制作
//学生类package com.zxe;public class Student {private String name;private int age;public Student() {}public Student(String name, int age) {this.name = name;this.age = age;}public void setName(String name) {this.name = name;}public String getName() {return name;}public void setAge(int age) {this.age = age;}public int getAge() {return age;}public void show() {System.out.println(name + "," + age);}}//学生测试类package com.zxe;public class StudentDemo {public static void main(String[] args) {//无参构造方法创建对象Student s1 = new Student();s1.setName("张三");s1.setAge(23);s1.show();//有参构造方法创建对象Student s2 = new Student("刘德华",60);s2.show();}
}