杭州网站优化服务学院网站建设计划
九月开学迎新季,各大高校的迎新活动开展的如火如荼,随着科技的不断进步,高校为了更好的开展迎新活动,让新生们尽快熟悉新的校园和生活,会利用VR全景技术带领着新生进行校园游览,给予新生们巨大便利的同时,也为学校带来了许多其他的优势。

1、校园展示
新生有没有因为校园大而经常迷路呢?别慌,VR全景带你快速熟悉校园全貌。一般而言,大学校园的面积是高中校园的数倍,在这个偌大的校园里面,新生要准确的去找到报名点、饭卡充值点、财务室缴费处以及各种场景实在是不容易,人手一张地图是少不了的。

为了避免地图带着麻烦,VR全景可以在手机上呈现,校园通过VR全景技术在线上720°实景展示,无死角进行虚拟漫游,学校的图书馆、体育馆、操场、食堂、教学楼、宿舍楼等,1:1真实还原在互联网上。新生在手机上点击进入校园全景,根据路标指示或者是跳转场景逛校园。

2、沙盘展示
在VR全景中,电子沙盘的应用是很多的,尤其是对于占地面积较大的校园、大学城等,电子沙盘的功能就很有必要,不仅可以辅助新生快速了解校园整体布局,还可以通过沙盘,点击对应的点位直达对应的区域场景,帮助新生建立方向感,快速抵达想去的地方;
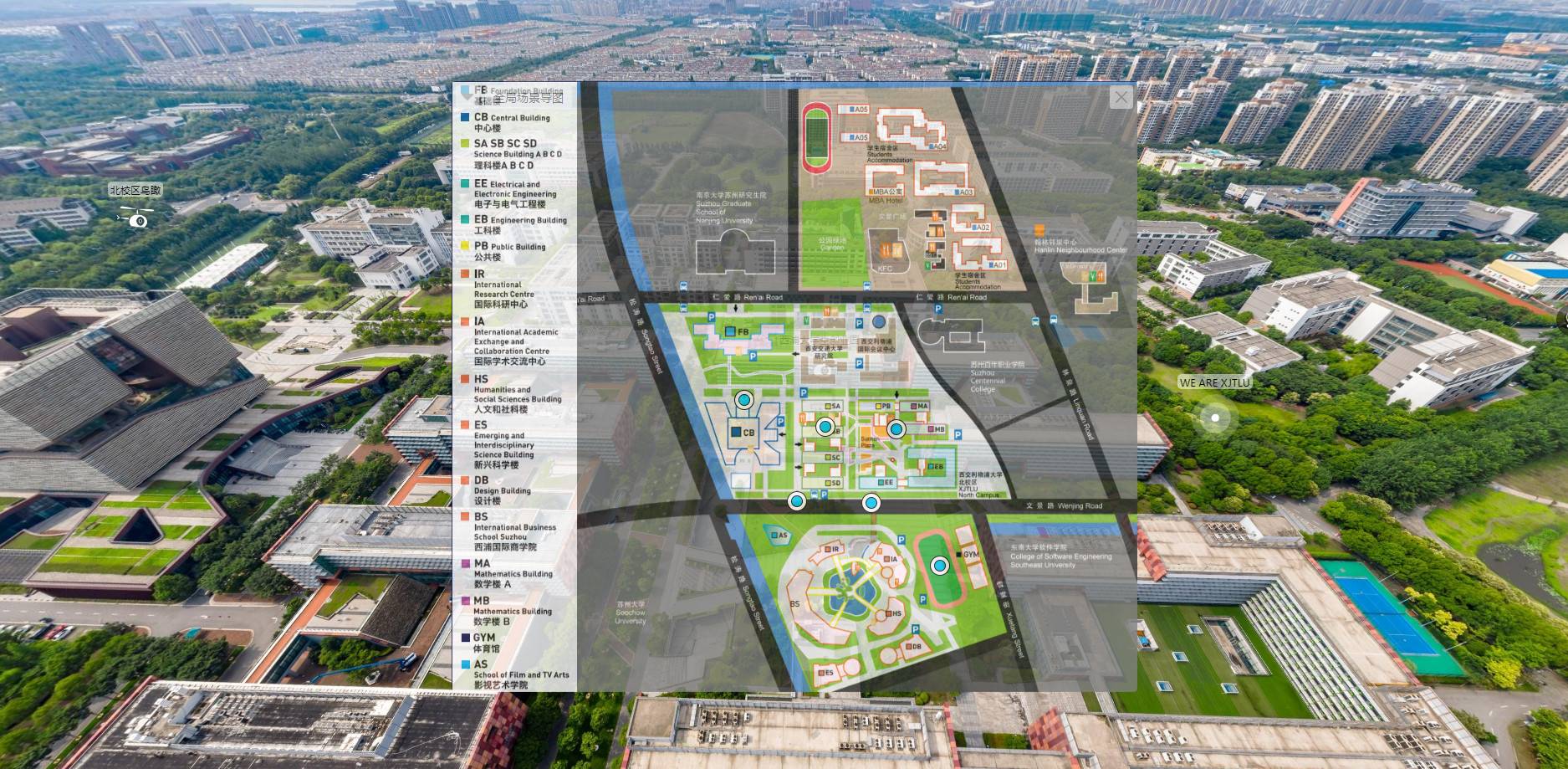
更有大像素全景功能,高清细致的展示学校各个区域的环境细节,进一步升级了新生以及家长的观看体验。新生在体验校园场景的同时,能够清晰的看到细微的物体、纹理和细节,增强了沉浸感和真实感,并准确了解当前所处的位置和环境。

3、中英文切换
为了满足不同语种的新生,VR校园通过使用英文对不同环境进行说明介绍,对接国际更方便。
VR全景中可以嵌入校园介绍的图文信息、语音讲解、视频介绍等,让学生对校园历史文化有更为立体、详尽的了解,而这些也都可以进行中英文切换,培养锻炼学生的英文水平。
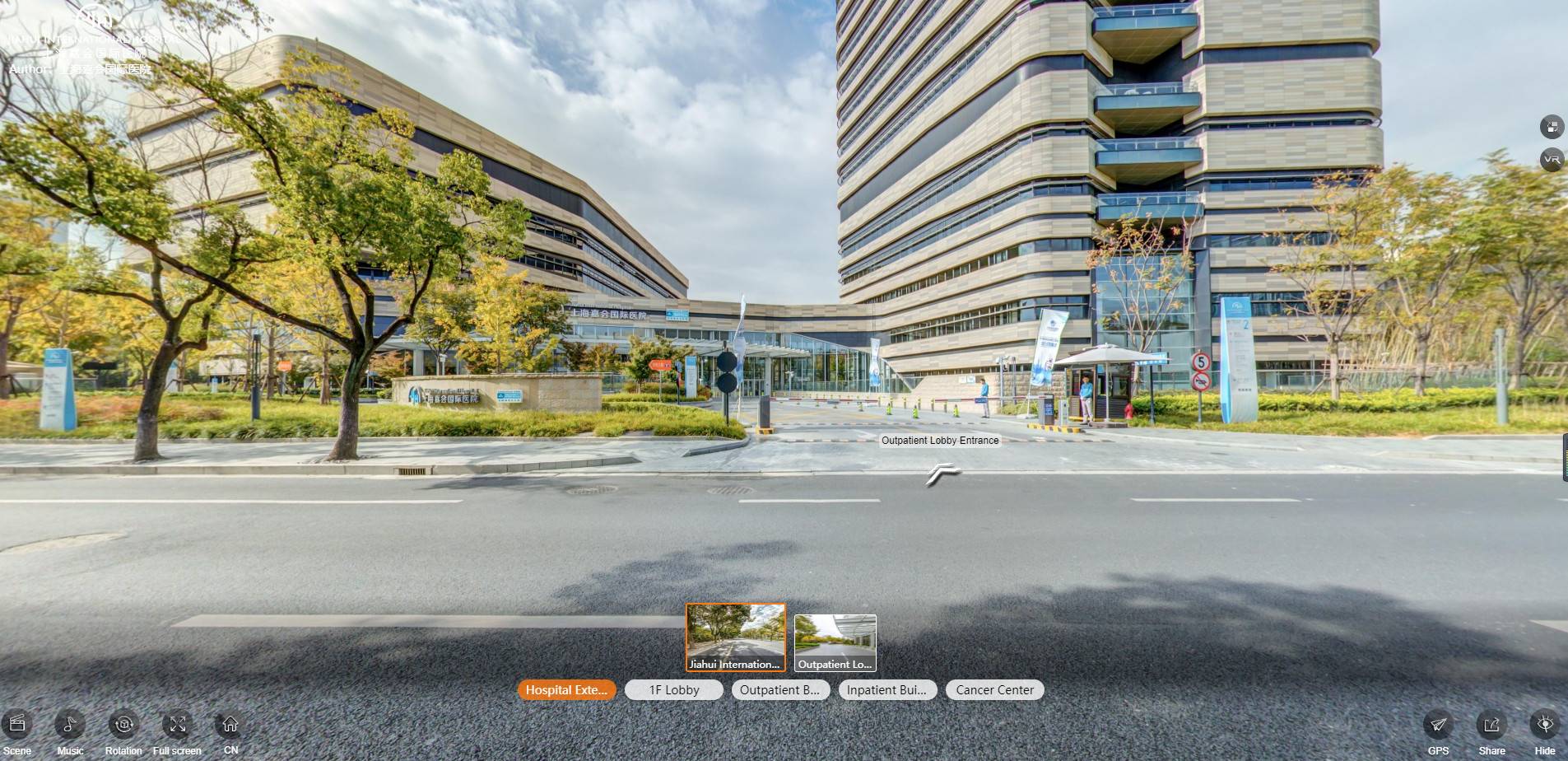
4、互动分享
VR校园中可以添加招生问答、线上预约、互动分享、实时弹幕等功能,浏览者可以随时随地在线上互动留言,通过轻松活泼的互动形式来分享信息,享受沟通的乐趣;而学校工作人员也可以参与其中快速解决学生咨询,以及记录校园存在的不合理地方,大大的提高了工作效率。

VR全景的使用范围较广,不仅仅是应用在高校里面,各个阶段的学校运用都一样得心应手,在招生宣传的环节可以更好的介绍表述学校实力,通过VR全景身临其境地感受校园,让学生和家长更加放心,随着VR全景技术的不断发展,未来VR漫游还会给校园体验带来更多的便利和互动。