广东企业网站seo哪里好90设计网站怎么样
Audacity 使用教程:轻松录制、编辑音频
1. 简介
Audacity 是一款免费、开源且功能强大的音频录制和编辑软件。它适用于 Windows、Mac 和 Linux 等多种操作系统,适合音乐制作、广播后期制作以及普通用户进行音频处理。本教程将带领大家熟悉 Audacity 的基本操作,学会录制和编辑音频。
2. 安装与界面
首先,访问 Audacity 官网 下载并安装适合你操作系统的 Audacity。安装完成后,打开 Audacity,你将看到如下界面:
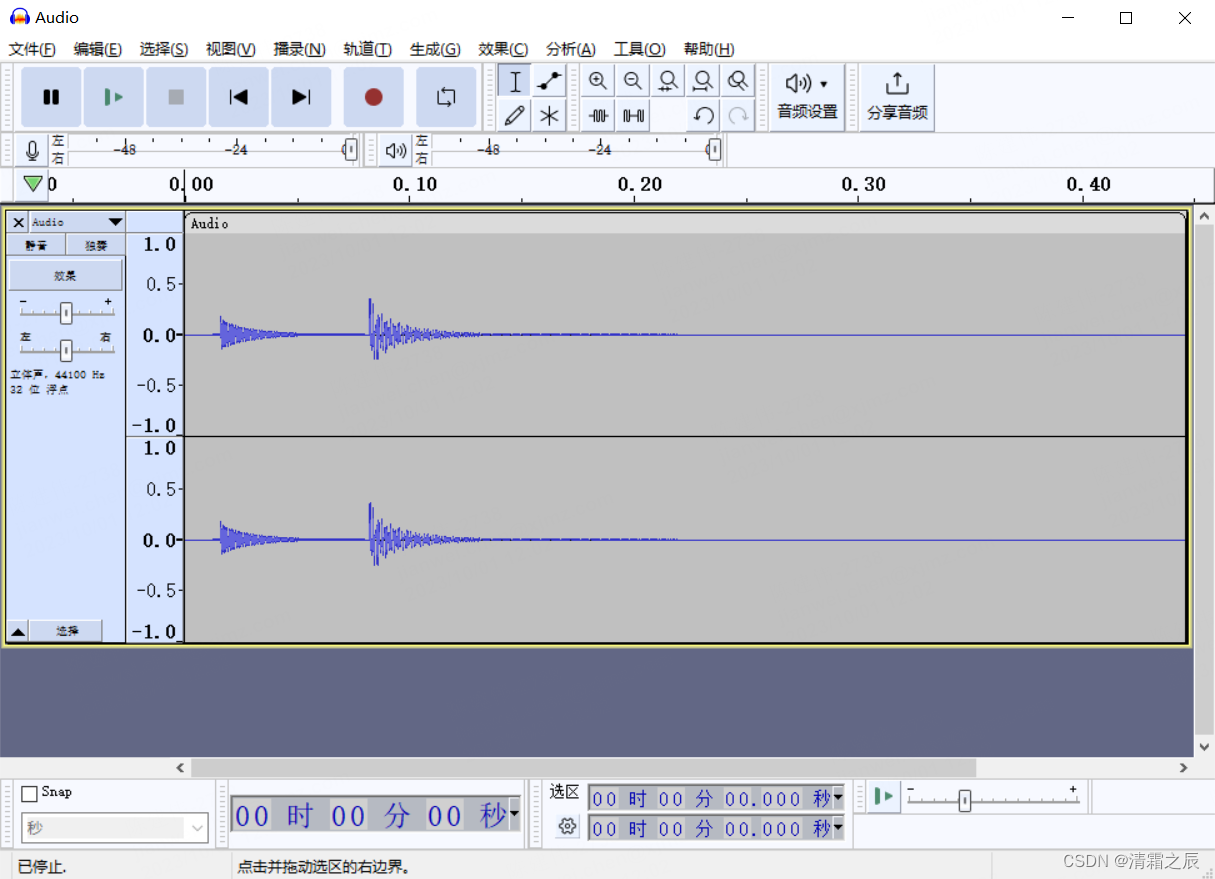
3. 录制音频
要录制音频,请按照以下步骤操作:
- 点击顶部菜单栏的“文件”(File),然后选择“新建”(New)。
- 在弹出的对话框中,选择录音设备(Recording Device),并设置录音格式和文件类型。
- 点击“确定”(OK),此时 Audacity 将开始录音。
- 开始说话或播放音乐,录制你想要的音频。
- 当录音完毕,点击顶部菜单栏的“停止”(Stop)按钮。
- 点击“文件”(File)>“导出”(Export),为录制的音频命名并选择保存位置。
4. 编辑音频
Audacity 提供了丰富的音频编辑功能,以下是一些常用操作:
4.1 裁剪音频
- 选择需要裁剪的音频片段,点击顶部菜单栏的“选择”(Selection Tool)。
- 使用鼠标拖动选择起始和结束时间点。
- 点击顶部菜单栏的“编辑”(Edit)>“裁剪”(Clip)。
4.2 删除音频片段
- 选择需要删除的音频片段,点击顶部菜单栏的“选择”(Selection Tool)。
- 点击顶部菜单栏的“编辑”(Edit)>“删除”(Delete)。
4.3 调整音量
- 点击顶部菜单栏的“生成”(Generate)>“音量调整”(Change Gain)。
- 在弹出的对话框中,选择“音量增强”(Increase Gain)或“音量减弱”(Decrease Gain),并设置幅度。
- 点击“确定”(OK),即可调整音频音量。
4.4 混音与渲染
- 在 Audacity 中打开多个音频文件。
- 点击顶部菜单栏的“生成”(Generate)>“混音”(Mix)。
- 在弹出的对话框中,选择输出文件格式和保存位置,点击“确定”(OK)。
- 混音完成后,点击顶部菜单栏的“文件”(File)>“导出”(Export),选择输出文件格式和保存位置。
5. 总结
本教程向大家介绍了如何使用 Audacity 进行音频录制和编辑。通过简单的操作,你可以轻松地录制和处理音频文件。无论你是音乐爱好者还是专业人士,Audacity 都能满足你的需求。快来尝试一下吧!
感谢 智普清言 的贡献