海城网站设计哪个网站衬衣做的好
 点击创建新项目
点击创建新项目
在输入框中输入asp.net,并选择图中的
点击下一步
点击创建
然后,右键,添加,新建项
选择web窗体
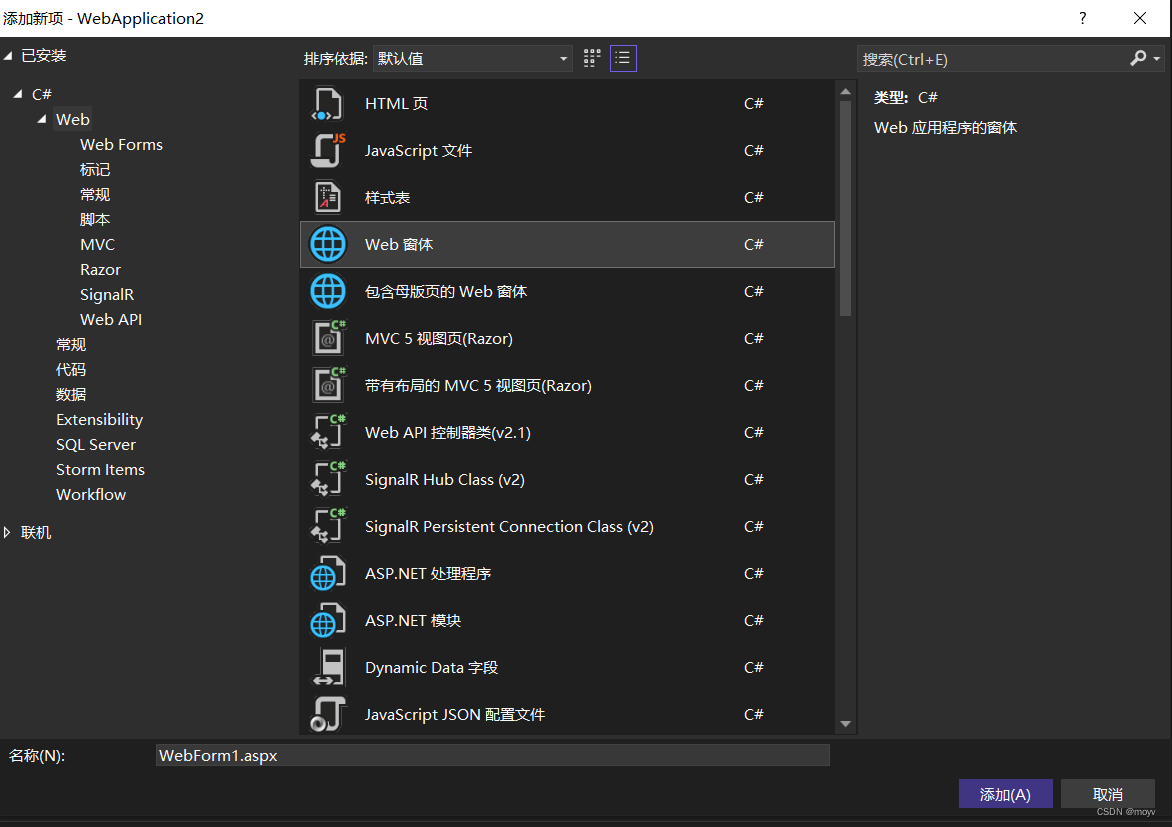
点击添加
点击视图,工具箱
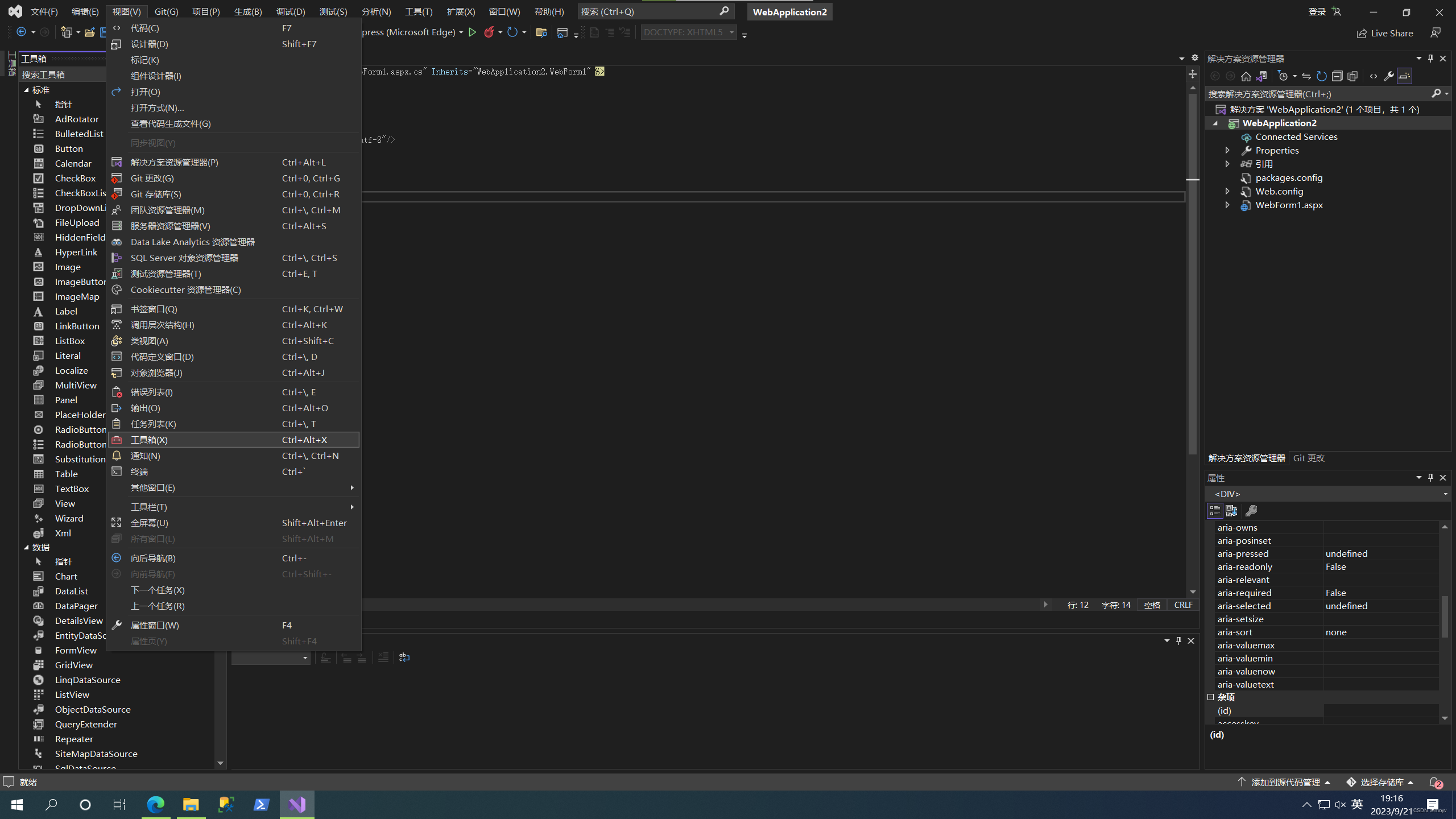
选择一个label,记住这个id
空白处右键,查看代码
添加代码
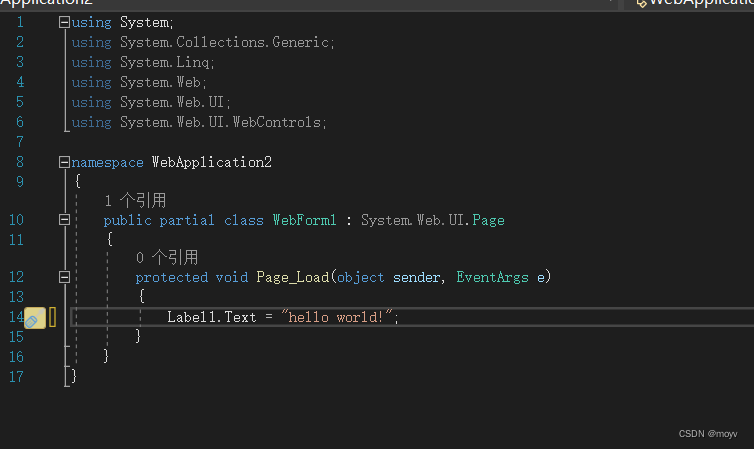
就是id.Text = "your text";
然后右键,项目名,发布
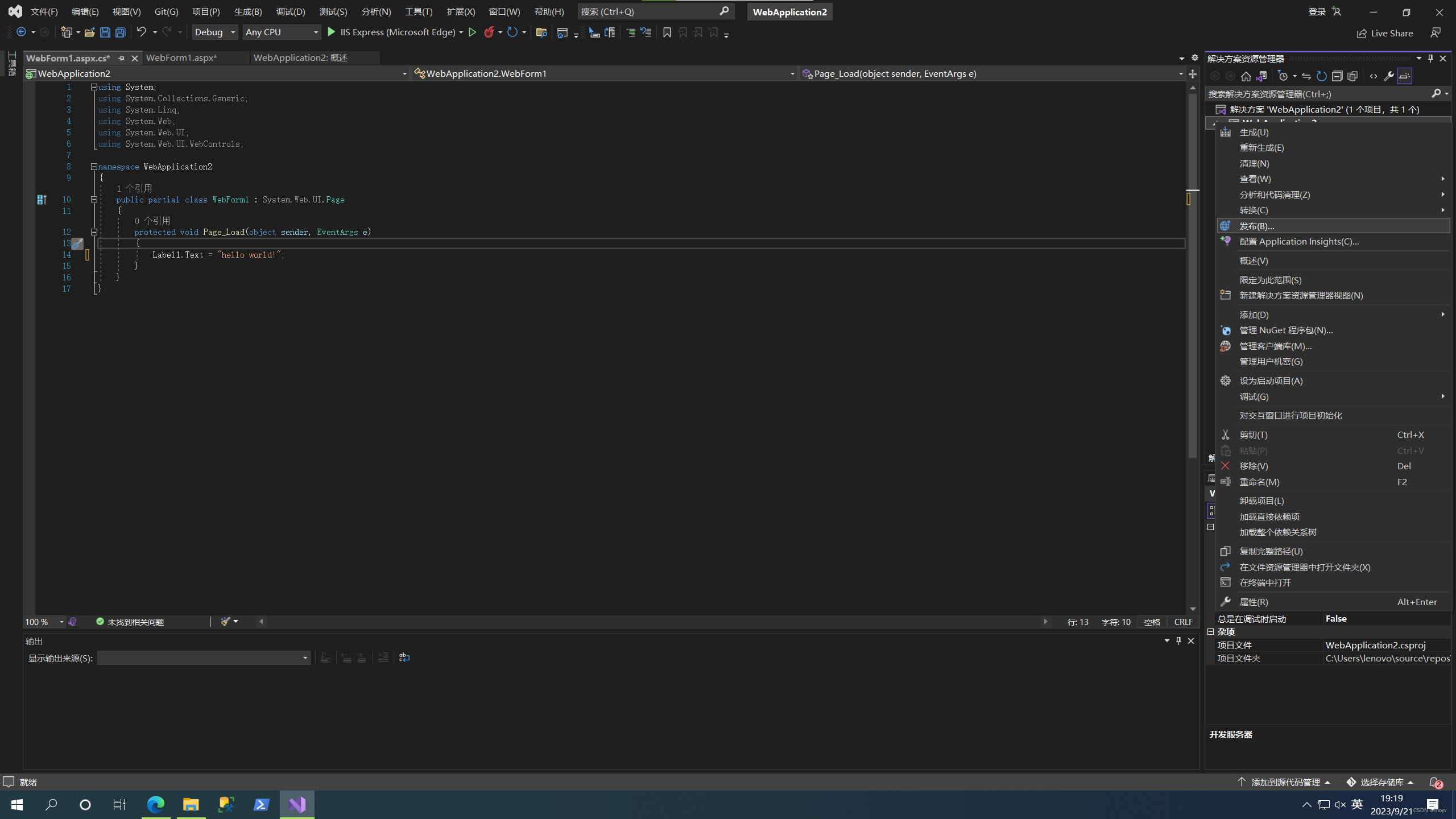
选择iis
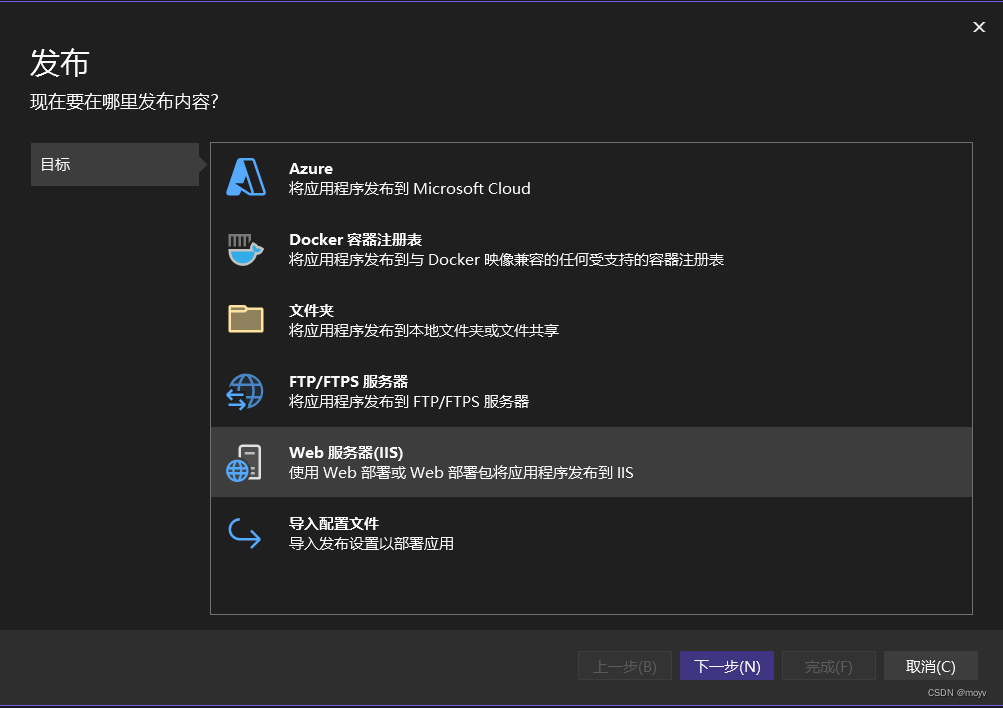
选择web deploy包
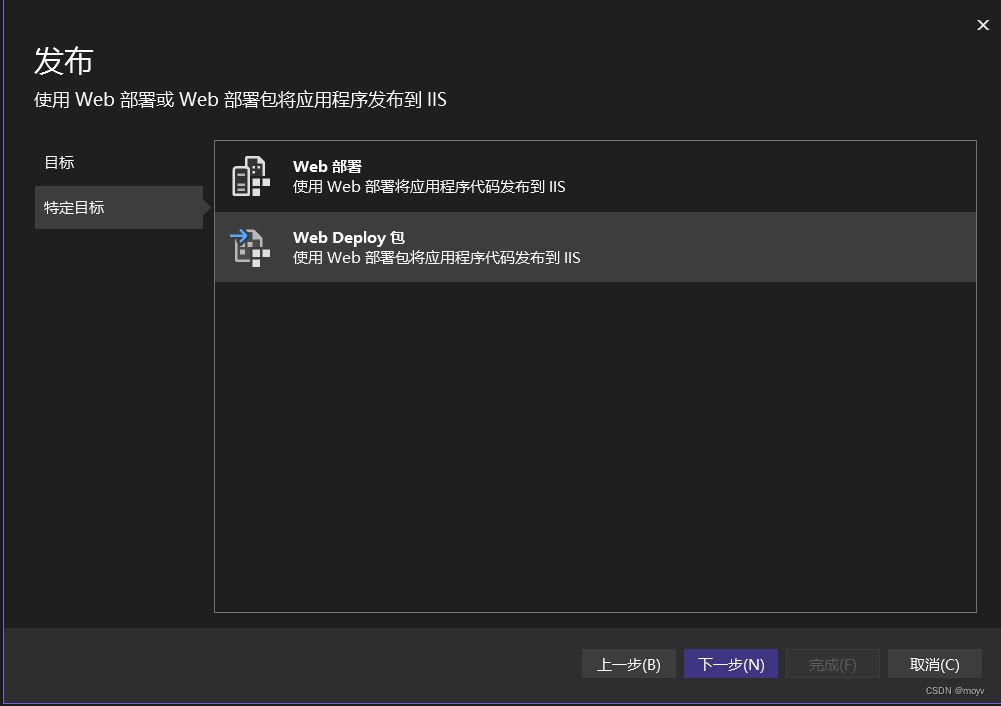
包位置,默认
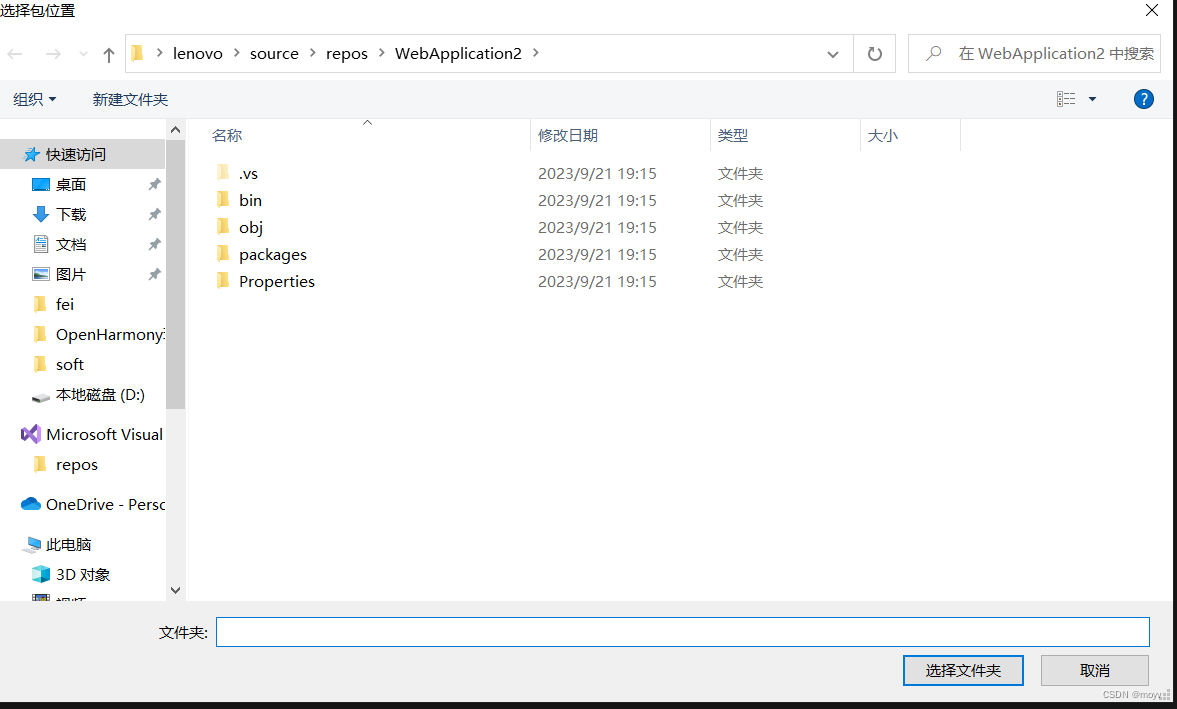
名称随意
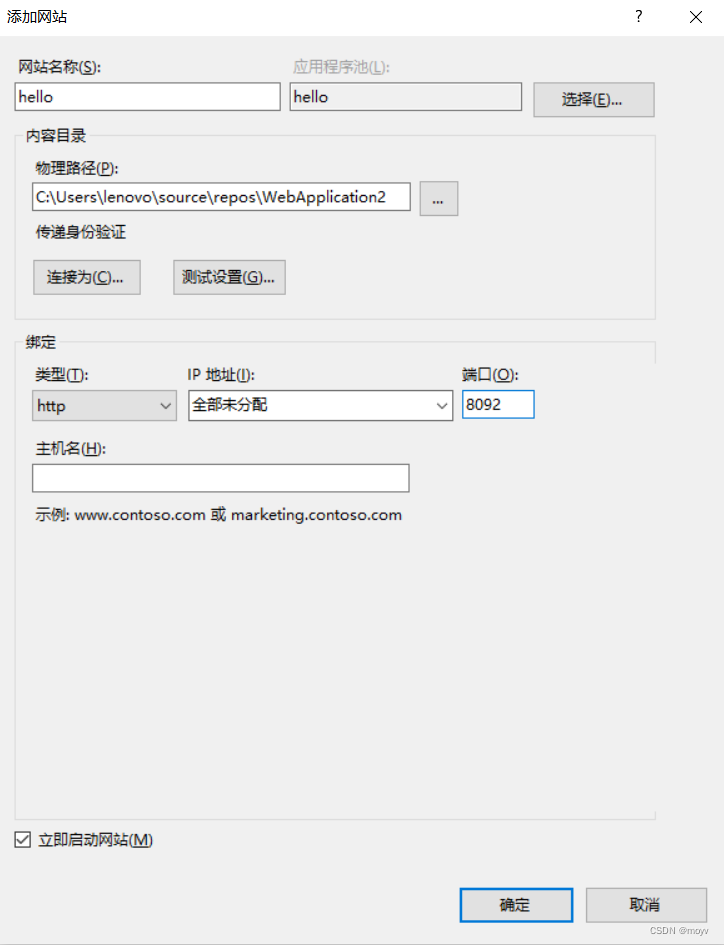
然后在iis里新建网站
展开右侧选项,右键网站,新建网站

物理位置是刚刚设置的,端口选择没占用的
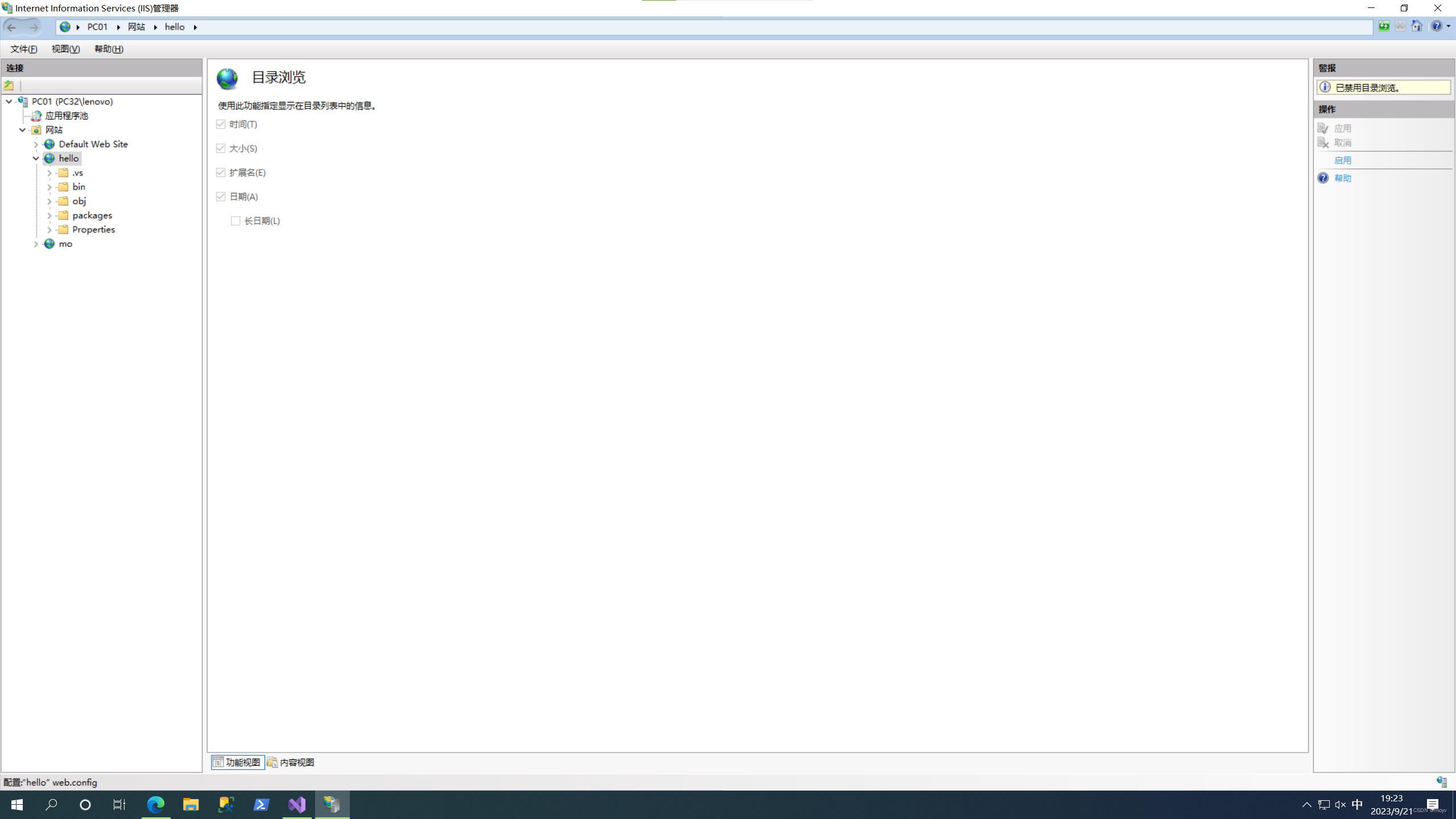
点击目录浏览,点击右侧启用
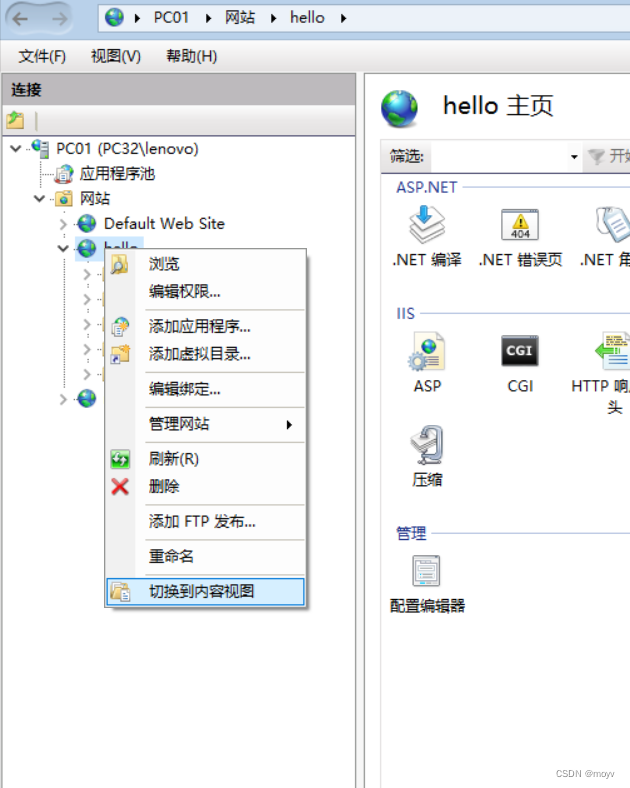
右键,切换到内容视图
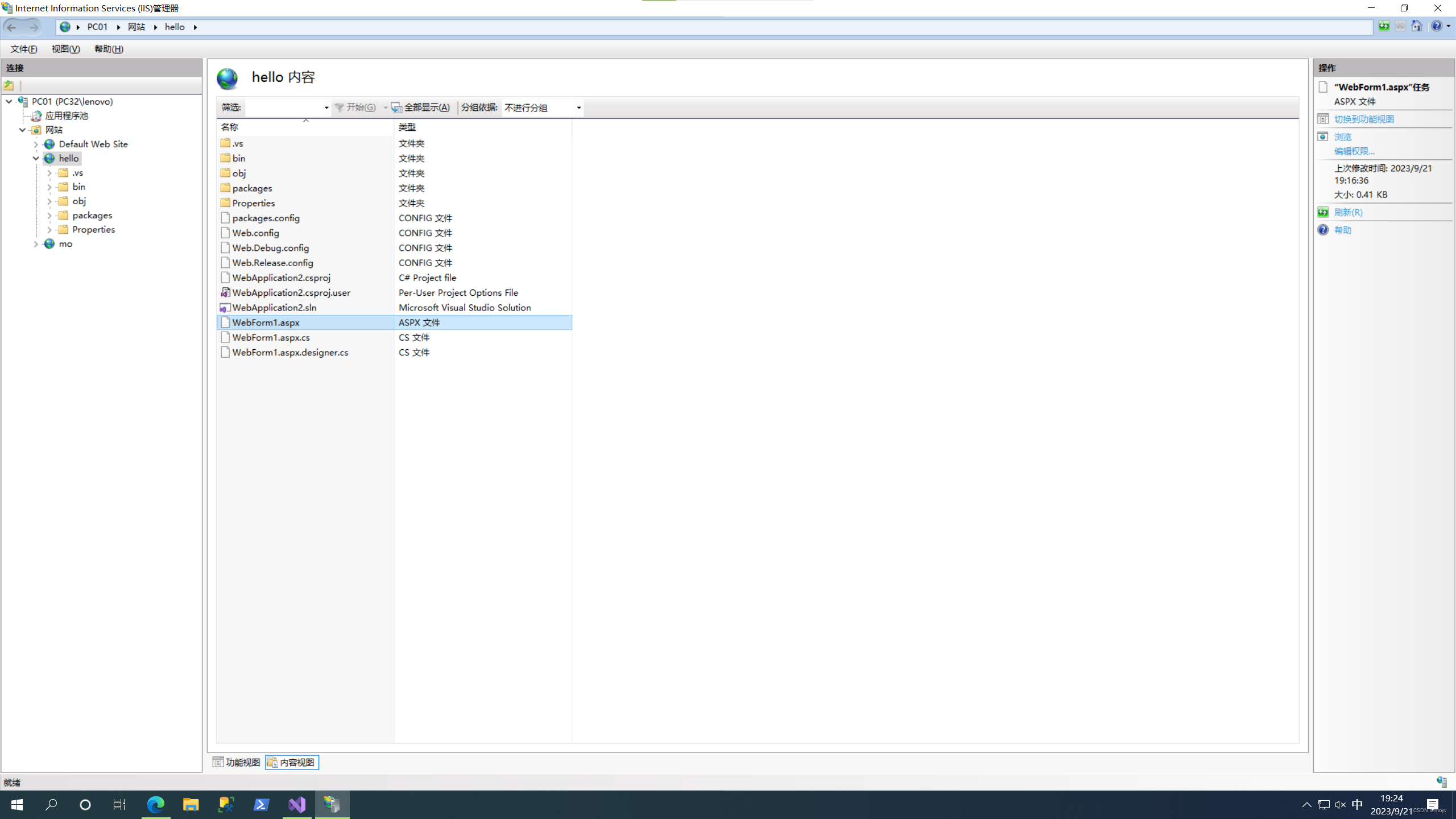
右键,浏览
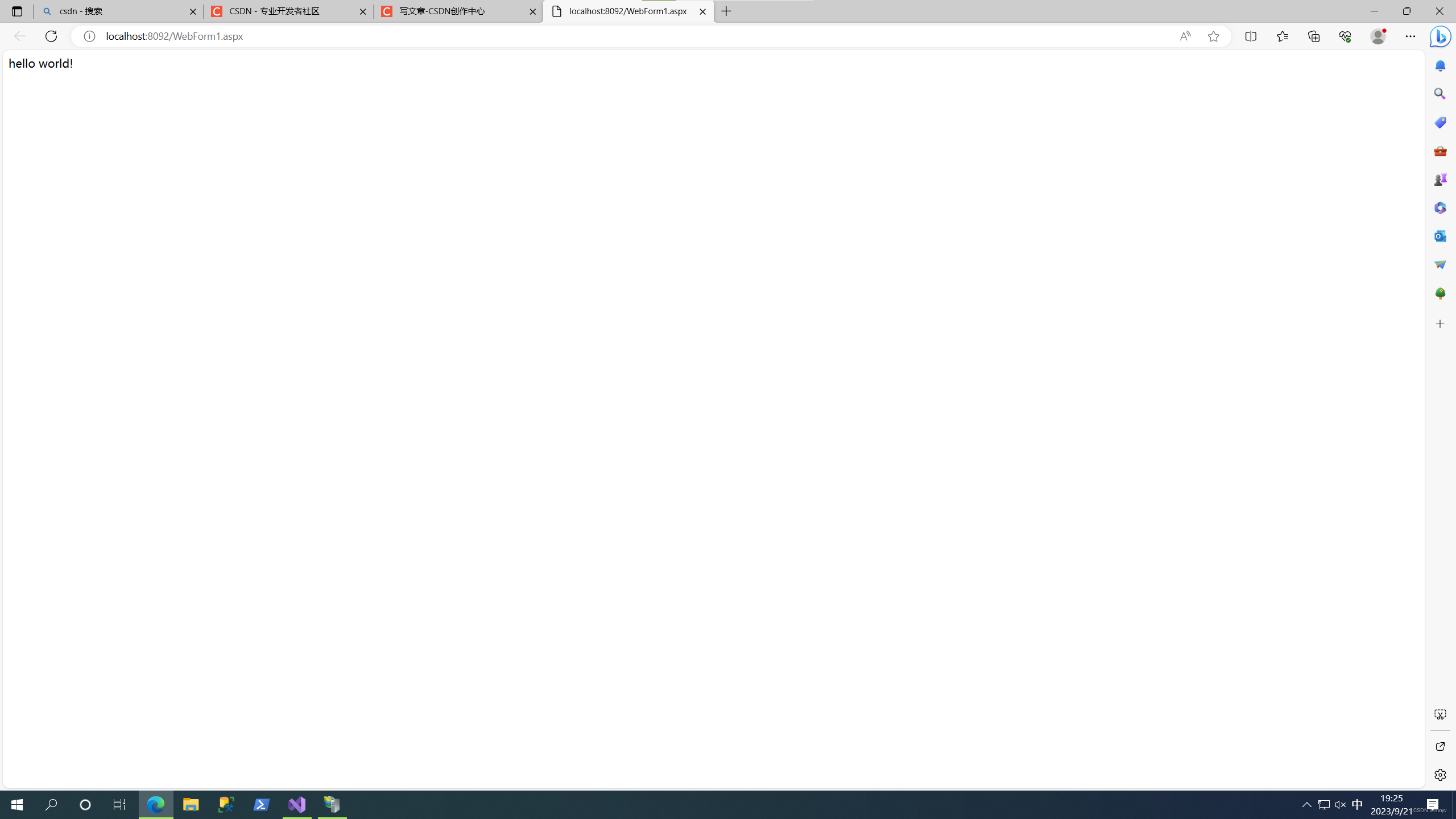
下班