最新钓鱼网站源码十大传媒公司
Linux_22_系统初始化流程
- 系统初始化
- 启动流程
- Boot Loader
- 初始化文件系统
- 第一个程序
- 内核模块
- Grub2
- 配置Grub2
- 启动管理
- 修改root密码
系统初始化
启动流程
1)读取BIOS,根据BIOS加载硬件信息和硬件系统自检;
2)根据BIOS读取第一个可启动设备中MBR的启动引导程序(Boot Loader);
3)根据启动引导程序,将指定内核(Kernel)文件加载至内存中解压和执行;
4)待内核检测硬件和加载驱动程序完毕,系统即可运行。
//内核文件一般为压缩文件,使用前需解压缩,才能加载到内存中
在驱动程序加载完成后,Kernel会主动调用Systemd程序进行default.target流程:
1)Systemd执行sysinit.target初始化系统;
2)Systemd执行basic.target设计运行环境;
3)Systemd启动multi-user.target下的本机/服务器的服务;
4)Systemd执行multi-user.target的/etc/rc.d/rc.local、getty.target和登录服务
//若是图形界面,Systemd还需执行graphical.target所需的服务
BIOS(基础输入输出系统):提供系统最底层和最直接的硬件设置和控制
1)不论BIOS还是UEFI BIOS都统称为BIOS(固化在主板上)
MBR(主引导记录):磁盘中的Boot Loader区块
1)系统的MBR一般指的是第一个启动设备中的MBR
2)只要BIOS可检测到磁盘(不论任何格式),都可通过硬件的INT 13中断功读取磁盘内的第一个扇区内的MBR
Boot Loader
Boot Loader(启动引导程序):识别内核文件格式并加载至内核中执行
1)Boot Loader程序安装在MBR中(磁盘的第一个扇区)
//不同的操作系统的Boot Loader不同,且内核需对应的Boot Loader才可加载,所以每个文件系统都会保留一块启动扇区(Boot Loader)用于安装Boot Loader
如:系统中有多个文件系统时的boot loader
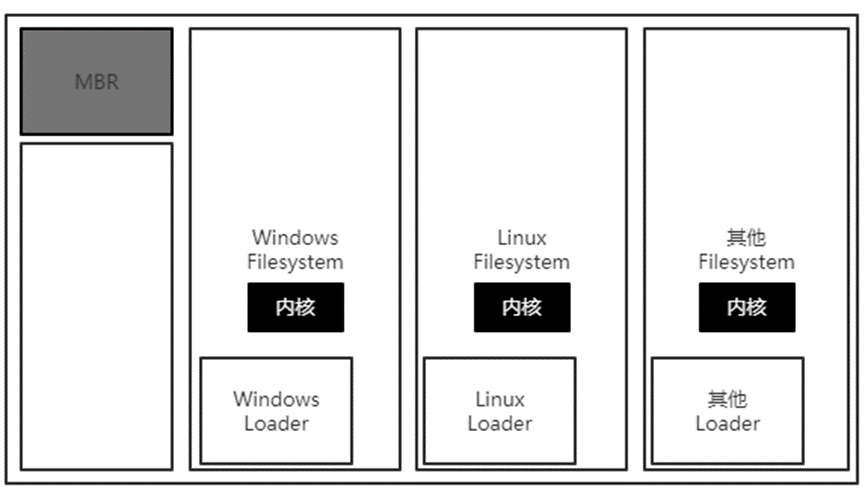
//Windows安装时,默认将在MBR和boot sector上都装上boot loader
//Linux可选择是否安装选择在MBR,若不选择在MBR上安装boot loader,则boot loader仅在boot sector上安装(反之亦然)
boot loader功能:
1)提供多重引导启动功能(加载指定的内核文件);
//实现一台电脑安装多个操作系统
2)直接加载内核文件;
//默认会加载至boot sector内的启动引导程序(如:grub2)
3)将启动管理功能转交至其他boot loader
//Windows的boot loader默认不具有控制权转交功能,所以不能实现在启动Windows后的boot loader后再加载Linux的boot loader(这也是系统安装多重引导时,需先装Windows再装Linux)
如:Windows、Linux和直接加载内核
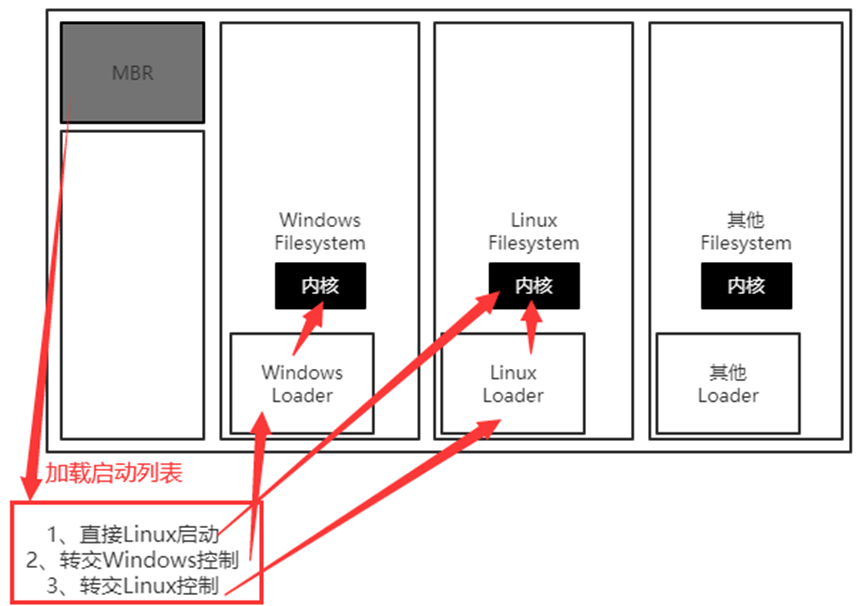
1)MBR(grub2)Linux Kernelbooting
2)MBR(grub2)boot sectore(Windows Loader)Windows Kernelbooting
3)MBR(grub2)boot sectore(grub2)Linux Kernelbooting
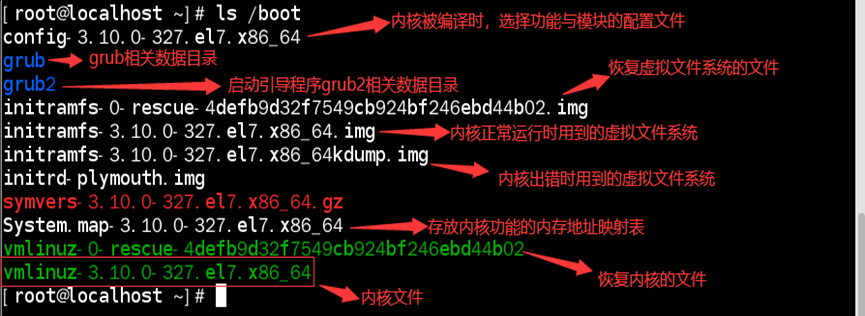
内核文件存储在:/boot/vmlinuz-版本号
//不同版本系统的内核版本和版本号不同,所以没有具体路径
如:查看/boot目录下的文件
Linux内核是通过动态加载内核模块实现多个功能加载
1)Linux发行版都将非必要且可编译的内核功能编译成模块
//如:USB、SATA和SCSI等磁盘设备的驱动程序都是以模块方式加载内核模块都存储在:/lib/modules
//因为动态加载,所以“/”和“/lib”必须放在同一个硬盘分区
如:查看/lib/module目录下存放的内核模块
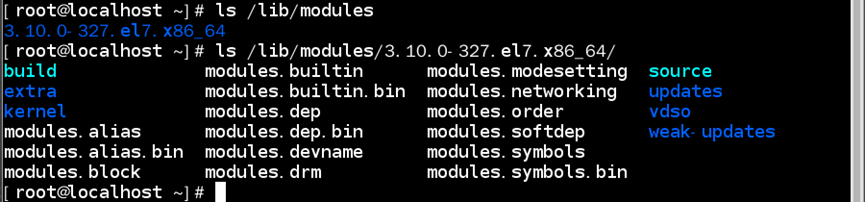
//若含有多个内核,则以内核版本号命名的目录存储其内核模块
//虽然设备的驱动程序在/lib/modules目录下,但内核并不能挂载该目录(也读取不到该目录下的驱动程序),且内核不能识别具体设备,只能通过加载具体设备的驱动程序将其挂载至根目录
初始化文件系统
初始化文件系统(Initial Ram Filesystem):内存中模拟文件系统以提供执行程序
1)虚拟文件系统通过boot loader加载至内存中,并被解压缩(压缩文件)在内存中模拟成一个根目录使用;
2)通过虚拟文件系统提供的程序加载启动程序中需要的内核模块,模块通常为文件系统设备的驱动程序;
3)加载完成后,再帮助内核重新调用Systemd完成后续的启动流程;
//初始化文件系统也可称为虚拟文件系统
如:BIOS、boot loade和内核加载流程
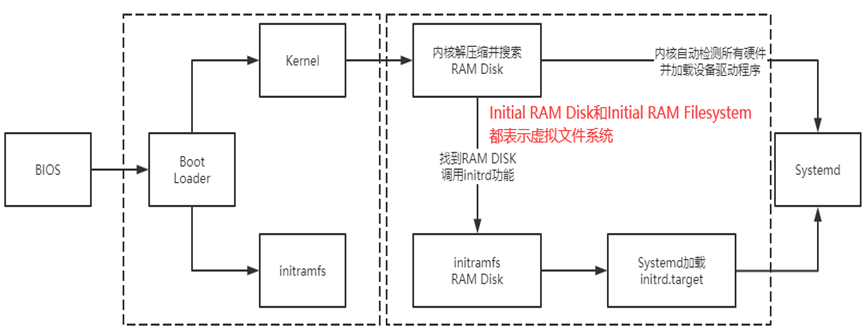
//boot loader加载Kernel和initramfs(Initial RAM Filesystem),在内存中将initramfs解压缩成根目录,由此加载所需的驱动程序,加载完成后释放initramfs并挂载实际的根目录文件系统
如:查看系统的虚拟文件系统(initramfs)
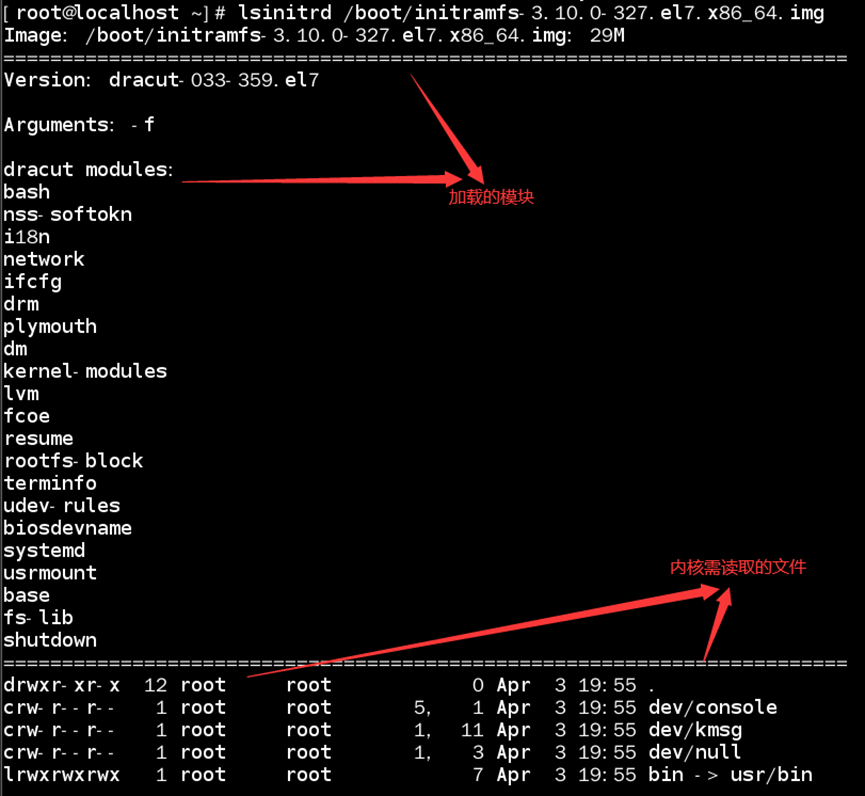
//initramfs就是一个小型的根目录,且由Systemd管理initramfs通过initrd.target启动
initramfs存在原因:内核模块都存储在/lib/modules/$(uname-r)/kernel目录下,则内核想读取这些模块就需先将其在根目录挂载,而内核本身不具备磁盘的驱动程序,所以不能挂载到根目录,进而不能读取到模块
initramfs具体操作:
1)将/lib/modules目录下内核启动过程所需的模块打包成一个文件(initramfs);
2)在启动过程中就通过INT 13硬件中断的功能将文件解压缩;
3)initramfs在内存中模拟成根目录,且包含磁盘驱动程序和文件系统的模块;
4)内核通过initramfs就可识别实际的磁盘,进而将实际的根目录挂载;
dracut命令:建立/重置initramfs文件
指令格式1:dracut 选项 initramfs文件名
| 选项 | 含义 |
|---|---|
| -f | 强制编译initramfs 若initramfs文件已存在,则覆盖 |
| -v | 显示dracut运行过程 |
//各个发行版的内核都默认提供initramfs文件
指令格式2:dracut 选项 initramfs文件名
| 选项 | 含义 |
|---|---|
| –add-drivers | 添加指定内核模块到initramfs文件中 指定的内核需在/lib/modules/$(uname -r)/kernel存在 |
| –filesystems | 添加指定额外的文件系统到initramfs文件中 |
| –gzip --bzip2 --xz | 指定initramfs文件压缩方式 默认为gzip |
第一个程序
待内核加载完成、硬件检测和驱动程序加载都完成后,内核会自动调用第一个程序“Systemd”(所以Systemd的PID是1)
1)Systemd功能:通过default.target设计软件运行的环境
2)Systemd的默认启动服务集合:/etc/systemd/system/default.target
//如:系统的主机名、网络设置、文件系统格式和其他服务的启动等
如:查看/etc/systemd/system/default.target
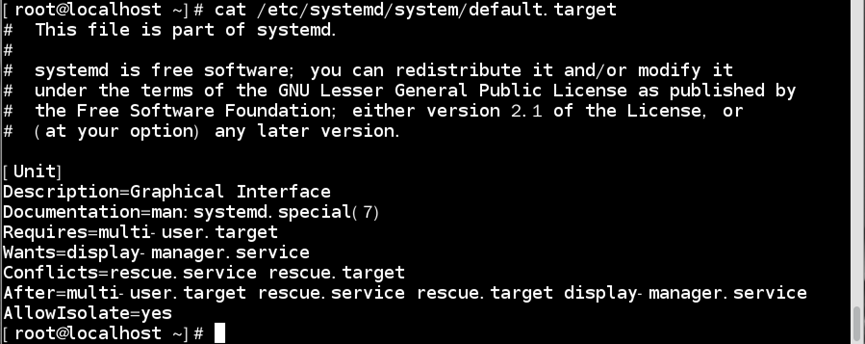
当内核完成/etc/systemd/systemd/default.target的默认启动服务集合后,就会链接到/usr/lib/systemd/system目录下加载multi-user.target或graphical.target
//加载graphical.target相当于也加载了multi-user.target(graphical.target在multi-user.target加载完成后通过加载其他服务而完成)
如:继续加载multi-user.target(graphical.target同理)流程
1)查看multi-user.target配置文件
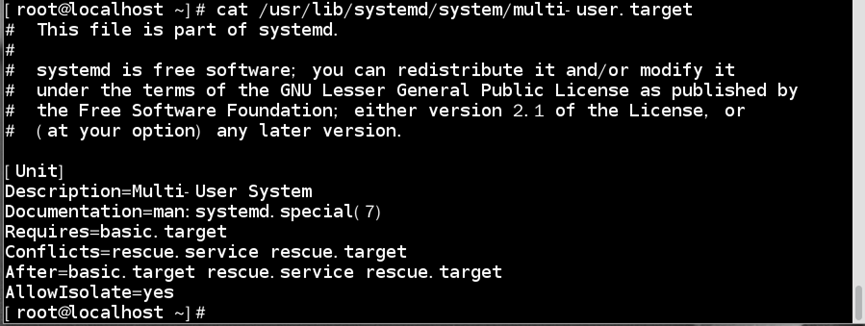
//multi-user.target需在basic.target加载完毕后再加载很多服务
2)查看multi-user.target加载的其他服务
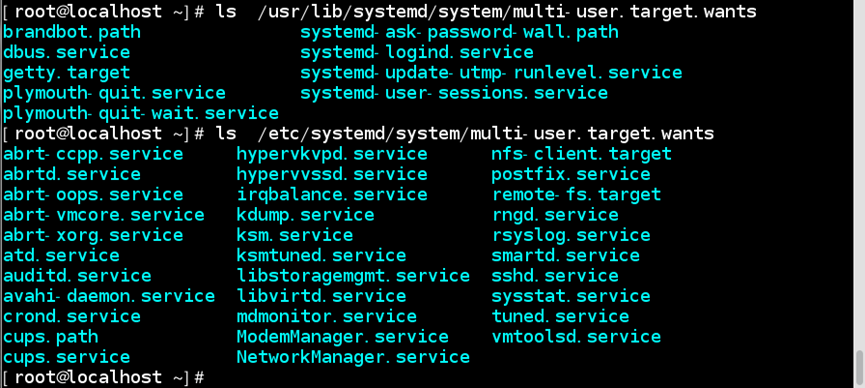
//其中/usr/lib/systemd/multi-user.target.wants代表系统设置加载的服务,/etc/systemd/system/multi-user.target.wants代表用户设置加载的服务
Systemd启动流程:
1)local-fs.target:挂载系统/etc/fstab规范的文件系统;
2)swap.target:配置内存交换分区;
3)sysinit.target:检测硬件和加载内核所需模块等;
4)basic.target:加载主要设备的驱动程序和防火墙等;
5)multi-user.target:加载普通系统服务和网络服务
//若系统为图形界面,还需执行graphical.target完成界面化服务
sysinit.target:提供系统基本的内核功能、文件系统和设备驱动等(初始化系统)
sysinit.target主要实现功能如下:
| sysinit.target主要实现功能 |
|---|
| 特殊文件系统设备的挂载 如:dev-hugepages.mount和dev-mqueue.mount等挂载服务; |
| 特殊文件系统的启用 如:磁盘阵列(RAID)、网络驱动器(iscsi)和文件系统对照服务等; |
| 系统启动过程中信息传递和画面展示 如:plymouthd服务和plymouth命令来传递动画和信息; |
| 日志文件服务的启动 如:systemd-journald服务的启用; |
| 加载额外的内核模块 如:通过/etc/modules-load.d/模块名.conf文件实现加载内核额外功能; |
| 加载额外的内核参数设置 如:读取/etc/sysctl.conf和/etc/sysctl.d/模块名.conf |
| 启动系统的随机数生成器 如:帮助系统进行密码加密演算功能; |
| 设置终端字体 如:配置终端显示的字体形式 |
| 启动动态设备管理器 如:通过udevd程序,动态对应实际设备读写和设备文件名 |
//不论任何运行级别,sysinit.target都是必须工作的
basic.target:完善初始化后系统的其他服务(操作系统)
| basic.target主要实现功 |
|---|
| 加载alsa音效驱动程序 如:alsa是音效相关的驱动程序,使系统有音效效果 |
| 加载firewalld防火墙 CentOS7后用firewalld替代iptables(依然是iptables框架),设置有差异 |
| 加载root指定的模块 如:模块存储在/etc/sysconfig/modules/模块名.modules和/etc/rc.modules |
| 启动/配置SELinux安全上下文 如:root可强制重新设置SELinux的安全上下文 |
| 加载CPU微指令功能 |
| 加载Systemd支持的timer功能 |
| 将启动过程所产生的数据写入到/var/log/dmesg |
/etc/systemd/system/multi-user.target.wants:通过链接文件控制服务开机自启
//系统在启动时,会自动启动该目录下的所有文件,若让一个服务开机自启,只需将在该目录下做个链接文件
如:取消cups服务的开机自启,再设置其为开机自启
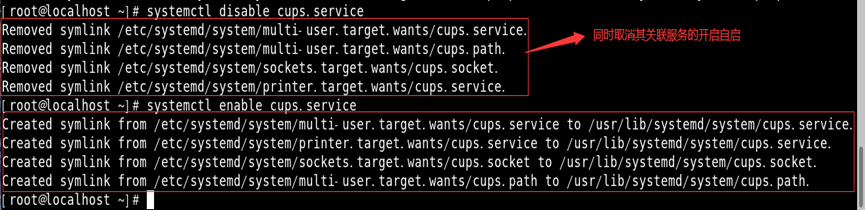
//通过systemctl建立/删除链接文件实现是否开机自启
/etc/systemd/system目录:存储系统启动需执行的程序/脚本文件
//实现效果同/etc/rc.d/rc.local文件一致,两者不同处在于:前者属于Systemd,后者属于System V
rc-local.service:为兼容System V的rc.local
//该服务是否启动成功,与/etc/rc.d/rc.local是否具有可执行权限有关;若rc.local具有可执行权限,systemctl重读配置文件后则可启动该服务;若rc.local不具有可执行权限,则rc-local.service无法启动
如:启动rc-local.service服务
1)查看/etc/rc.d/rc.local权限,并启动rc-local.service服务;
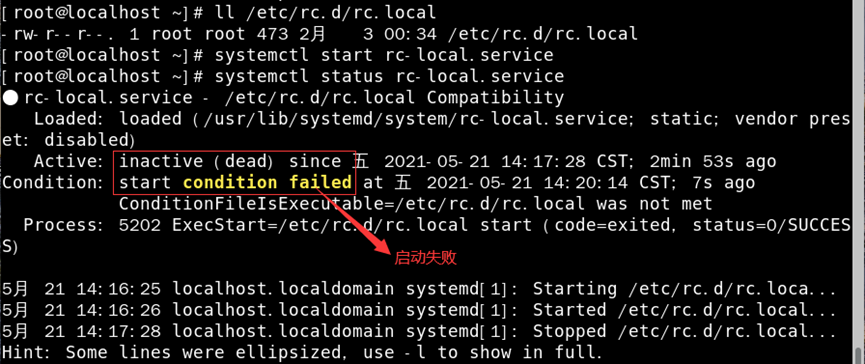
2)使/etc/rc.d/rc.local具有可执行权限,并启动rc-local.service服务
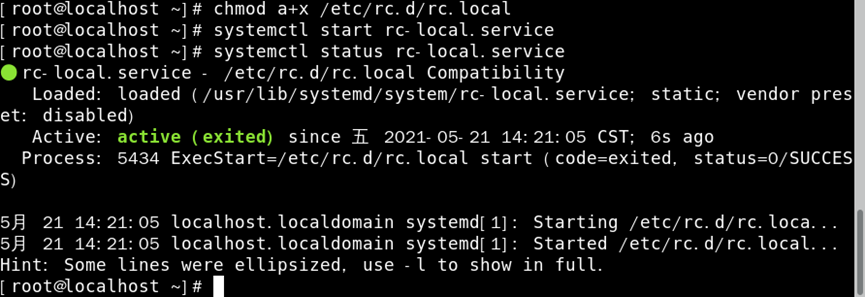
/etc/modules-load.d/模块名.conf:存储内核需加载的模块
1)内容格式:一行即代表一个需加载的内核模块
2)sysinit.target加载模块时默认调用该目录下的文件
/etc/modprobe.d/模块名.conf:存储内核模块的配置参数
1)内核模块的参数配置文件一般与该内核模块同名
/etc/sysconfig目录:存储系统服务的脚本文件
//虽然Systemd已拥有其他的配置文件处理方式,但为了兼容System V,系统启动时还是会读取/etc/sysconfig目录下的文件
如:/etc/sysconfig目录下常用的脚本文件
1)authconfig:规范用户的身份认证功能、/etc/passwd、/etc/shadow使用权限和/etc/shadwon的密码加密算法(Centos7默认使用SHA-512加密算法);
2)cpupower:规范Linux内核操作CPU的原则和启动cpupower.service;
//cpupower.service可让系统以CPU最大性能的方式来运行
3)firewalld:与防火墙相关的配置;
//与防火墙相关的还有:iptables-config、ip6tables-config和ebtables-config
4)network-scripts:网卡配置参数相关
内核模块
| 内核相关配置文件 |
|---|
| /boot/vmlinuz-内核版本号:存储内核文件 |
| /boot/initramfs-内核版本号:存储内核运行时所需的RAM Disk |
| /usr/src/kernels:存储内核源代码(默认不安装) |
| /proc/version:存储内核加载至内存后,内核版本相关信息 |
| /proc/sys/kernel:存储内核加载至内存后,内核功能相关文件 |
| /lib/modules/内核版本号/kernel:存储内核模块 |
如:查看/lib/modules/$(uname-r)/kernel目录
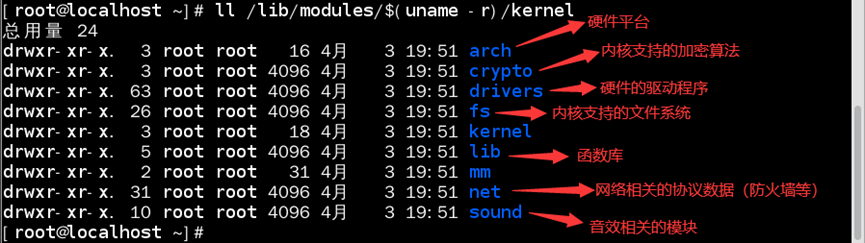
7)/lib/modules/内核版本号/modules.dep:记录内核模块依赖性
//内核模块的启动/运行类似服务一样具有依赖性
depmod命令:分析当前内核模块依赖性并写入默认文件中
//默认文件:/lib/modules/内核版本号/modules.dep
指令格式:depmod 选项
//不加选项时,默认分析当前内核模块依赖性,并重新写入默认文件中
| 选项 | 含义 |
|---|---|
| -a | 检查所有模块依赖性,并写入默认文件中 |
| -A | 检查是否有模块比默认文件中的模块新 若存在,则更新默认文件(反之,不更新) |
| -e | 显示当前已加载却不可执行的模块 |
| -n | 将分析结果输出到终端(不写入默认文件) |
lsmod命令:查看当前内核加载模块数量
指令格式:lsmod
如:查看当前内核加载了多少模块
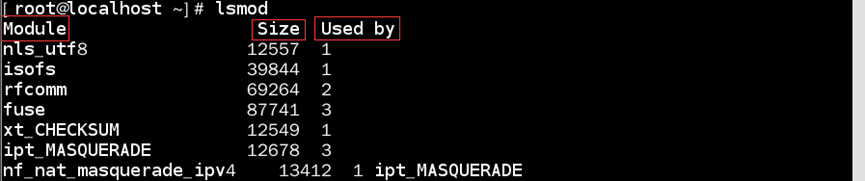
内容格式:模块名称(Module) 模块大小(Size) 模块是否被引用(Used by)
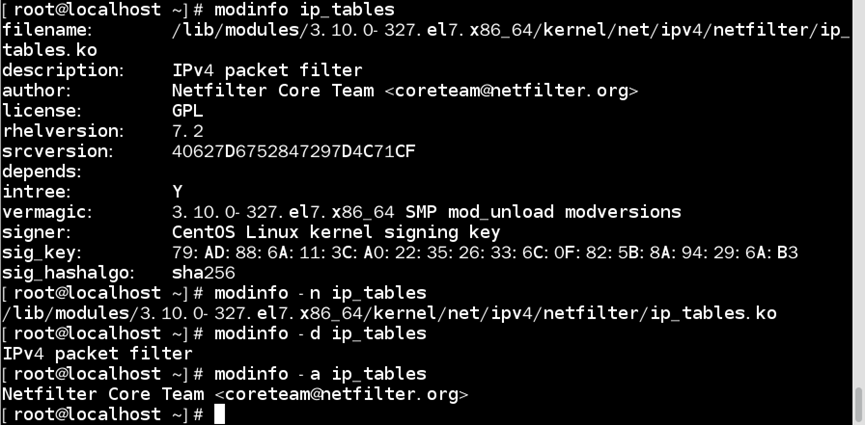
modinfo命令:显示指定内核模块的信息
//modinfo不仅可查看内核模块,还可查看具体模块文件
指令格式:modinfo 选项 模块名
| 选项 | 含义 |
|---|---|
| -n | 仅显示指定模块的绝对路径 |
| -d | 仅显示指定模块的说明 |
| -p | 仅显示指定模块的参数说明 |
| -a | 仅显示指定模块的开发人员 |
如:查看ip_tables模块的信息
rmmod命令:从内核中删除指定模块
指令格式:rmmod 选项 模块名
| 选项 | 含义 |
|---|---|
| -f | 强制删除 |
| -w | 等待模块能被删除时再删除该模块 |
insmod命令:添加指定模块到内核中
//insomd可添加模块到内核中,但不能解决模块依赖性问题
指令格式:insmod 选项 内核模块的绝对路径
| 选项 | 含义 |
|---|---|
| -v | 显示执行过程 |
| -p | 测试模块是否能添加Kernel中 |
| -f | 强制添加 不检查当前Kernel版本和模块编译时的Kernel版本是否一致 |
modprobe命令:根据modules.dep文件添加/删除内核中的模块
//modprobe可添加一个/一组相依的模块,modprobe根据modules.dep文件中的依赖关系,决定添加哪些模块,且不需指定模块的绝对路径,因为modules.dep已记录该模块的绝对路径,若添加过程中发生错误,modprobe会删除整组模块
指令格式:modprobe 选项 模块名
| 选项 | 含义 |
|---|---|
| -c | 列出当前系统中所有的模块 |
| -f | 强制添加模块 |
| -r | 删除指定模块 |
Grub2
Grub2:Centos7使用的一种boot loader
grub2的优点如下:
1)识别和支持较多的文件系统,且grub2可直接在文件系统中查找内核文件;
2)系统启动时,可自行编译和修改启动设置选项(类似bash命令行模式);
3)动态查找配置文件
//只需修改/boot/grub2/grub.cfg的设置参数后,下次重启自动生效
grub2-install命令:将grub2安装到指定设备下
指令格式:grub2-install 选项 安装设备
| 选项 | 含义 |
|---|---|
| –force | 强制安装 |
| –recheck | 若安装设备上已存在,则删除后再安装 |
| –skip-fs-probe | 忽略该设备上的文件系统影响 |
| –boot-directory=目录路径 | 安装到指定设备的目录上 |
//grub2-install默认将grub2所有的文件都安装到/boot/grub2目录下
//grub2-install仅能安装grub2主程序和相关配置文件到/boot/gurb2目录下
//若将grub2安装到磁盘分区下时,需添加许多选项才能安装,且不能用grub2-install将主程序写入到启动扇区(导致无法启动)
配置Grub2
Linux将grub2分为两个阶段(stage)进行保存和运行:
//由于MBR是硬盘的第一个扇区的一个区块,容量仅446B,故不能存储下类似grub2这种复杂功能的grub2(GPT也不能)
1)Stage1:运行grub2主程序,主程序被安装在启动区(MBR或boot sector),并不安装其相关的配置文件;
2)Stage2:主程序加载配置文件,通过grub2加载所有配置文件和相关的环境参数文件(文件系统定义和主要配置文件grub.cfg)
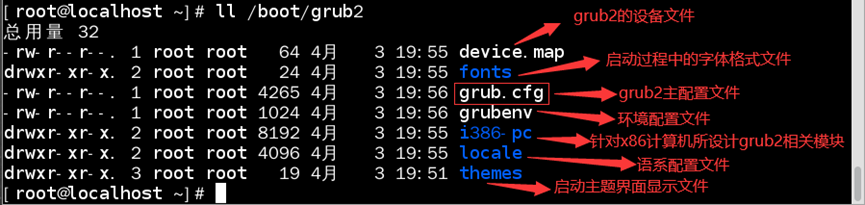
/boot/grub2目录:存储grub2相关配置文件
如:查看/boot/grub2
grub2的磁盘命名格式:
// grub2通过对磁盘命名,识别不同磁盘和磁盘分区
1)磁盘名以小括号括起来;
2)磁盘以“hdN”表示,N代表该磁盘的被查找到的顺序;
//第一个查找的磁盘为0,第二个为1,以此类推;
//由于BIOS可动态调整磁盘的启动顺序,则磁盘被查找的顺序不固定,所以N是可能会变动的
3)每个磁盘的第一个分区为1,以此类推
如:系统中含有三块磁盘,其在grub2的中命名如下
| 磁盘被查找到的顺序 | 在grub2中的命名 |
|---|---|
| 第一块(MBR) | (hd0)、(hd0,msdos1)、(hd0,msdos2)…… |
| 第二块(GPT) | (hd1)、(hd1,gpt1)、(hd1,gpt2)…… |
| 第三块 | (hd2)、(hd2,1)、(hd2,2)…… |
//第一块磁盘的第一个逻辑分区的启动扇区命名应为:(hd0,msdos5)
//在命名格式中,msdos和gpt可省略
/boot/grub2/grub.cfg文件:grub2的主要配置文件
//由于该文件内容太过复杂,数据量过多,所以不建议修改该文件,而是通过grub2-mkconfig命令产生新的grub.cfg文件
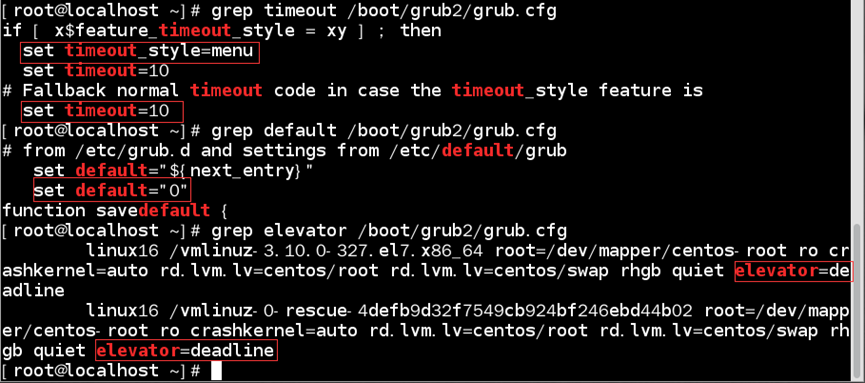
如:查看/boot/grub2/grub.cfg内容
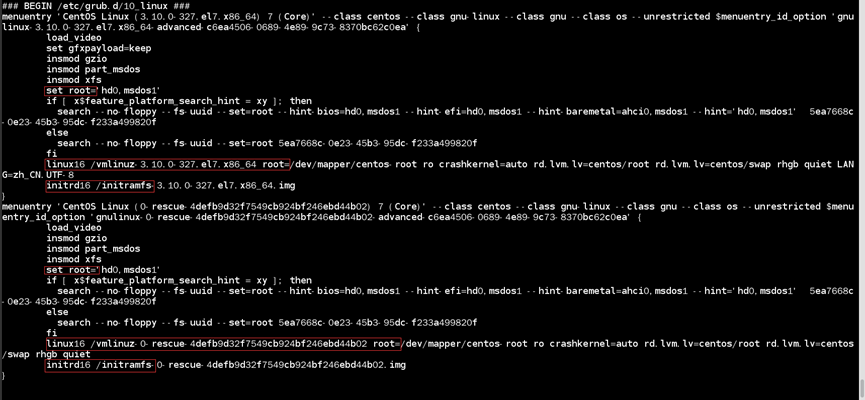
//grub.cfg内容可分为两部分,第一部分为:其他脚本文件的执行和基础运行环境的设计;第二部分(menuentry)为:设计针对具体Linux内核文件运行的环境
//配置文件中有几个menuentry配置,启动时就有几个选项
/boot/grub2/grub.cfg中特殊设置:
1)set root:指定在Linux文件系统中,根目录在那个磁盘上
2)linux16 /vmlinuz-内核版本号:指定Linux内核文件和内核执行时的参数设置
//由于系统在启动过程中,内核文件需挂载根目录并从根目录中读取配置文件,所以需搭配“set root”在配置中内核文件后一定要指定根目录所在的磁盘
3)initrd16 /initramfs-内核版本号:指定虚拟文件系统
//与linux 16同理,需搭配“set root”在配置中指定具体设备,才能读取到正确的虚拟文件系统
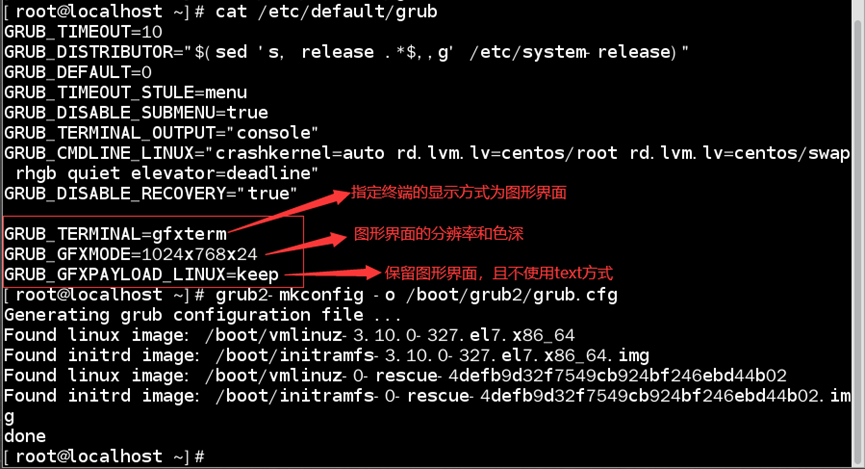
/etc/default/grub文件:提供用户修改grub2默认环境配置文件
如:查看/etc/default/grub内容
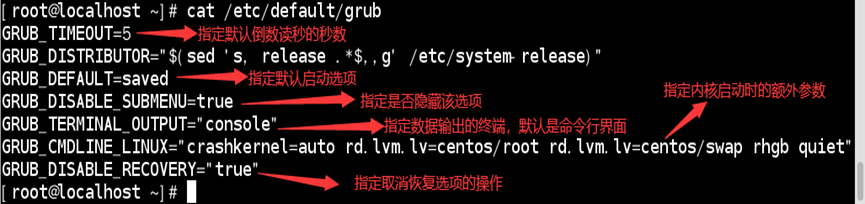
| 设置项 | 含义 |
|---|---|
| GRUB_TIMEOUT | 指定默认倒数读秒的秒数 若取消等待,则设置为0(直接为默认项) 若强制用户选择,则设置为-1 |
| GRUB_TIMEOUT_STYLE | 指定默认是否显示启动选项 menu:显示(默认项) countdown:取消显示,但显示等待秒数 hidden:取消所有显示(包括秒数) |
| GRUB_TERMINAL_OUTPUT | 指定默认信息输出终端 可设置为:console(默认项)、serial、gfxterm和vag_text |
| GRUB_DEFAULT | 指定默认启动选项 指定哪一个menuentry作为默认启动项 默认第一个启动选项为默认启动项 |
| GRUB_CMDLINE_LINUX | 指定内核运行的额外参数 实现类似linux16后的内核参数设置 |
//可通过menuentry的saved、数字、title名和ID名指定默认启动项
如:当系统含有3个menuentry时,指定默认启动项
1)查看3menuentry的title名和ID名;

2)指定编号是1的menuentry为默认启动项;

3)指定ID名是“3rd-win-system”为默认启动项;

4)指定saved为默认启动项;

仅修改/etc/default/grub并不能更改grub2的配置,配置/etc/default/grub文件后还需通过grub2-mkconfig命令使/boot/grub2/grub.cfg文件建立/更新
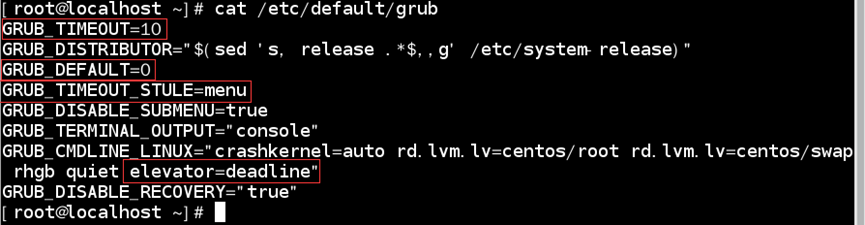
如:使启动选项时等待10秒;默认选用第一个选项;且选项是显示的;内核外带“elevator=deadline”参数
1)配置/etc/default/grub文件;
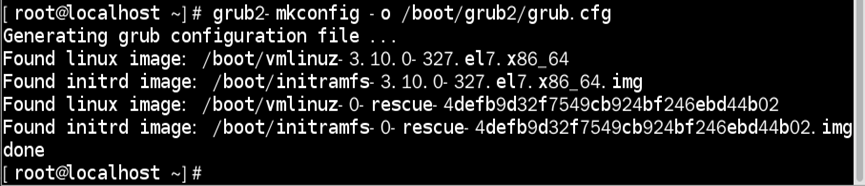
2)更新grub.cfg文件;
3)检验是否配置成功
grub2-mkconfig命令:通过多个脚本文件辅助建立/更新grub.cfg文件
指令格式:grub2-mkconfig -o /boot/grub2/grub.cfg
//grub2-mkconfig本质是分析/etc/grub.d目录下的文件和/etc/default/grub文件,再通过执行这些文件来建立/更新grub.cfg文件
/etc/grub.d目录:存储辅助建立/更新grub.cfg的脚本文件
如:查看/etc/grub.d

| 文件名 | 作用 |
|---|---|
| 00_header | 初始化grub2配置 (分析需加载的模块和屏幕终端的格式等) 通过调用/etc/default/grub来建立/更新grub.cfg文件 |
| 01_users | 管理gurb2在线编辑 |
| 10_linux | 分析/boot目录的所有文件,找到正确的Linux内核、读取该内核需要的文件系统模块和参数等; 并将以上这些设置到grub.cfg文件中 |
| 30_os-prober | 分析并找到其他分区含有的操作系统, 并将这些操作系统写入到grub.cfg中 以作为启动选项处理 |
| 40_custom | Shell文件 root通过配置该文件实现其他选项/需求 |
//若有其他需配置的选项,都应该通过配置40_custom文件实现,通过配置/etc/grub.d/40_custom可实现功能如下:
//在配置/etc/grub.d/40_custom后都需通过grub2-mkconfig命令使其生效
1)自定义内核:若直接启动普通内核,可通过grub2-mkconfig获取10_linux脚本文件而制作;但要带自定义的内核,就需使用grub2-mkconfig获取40_custom脚本文件而制作
制作步骤:
(1)从grub.cfg当中复制指定内核选项(menuentry)到40_custom;
(2)在40_custom中配置带有自定义的内核
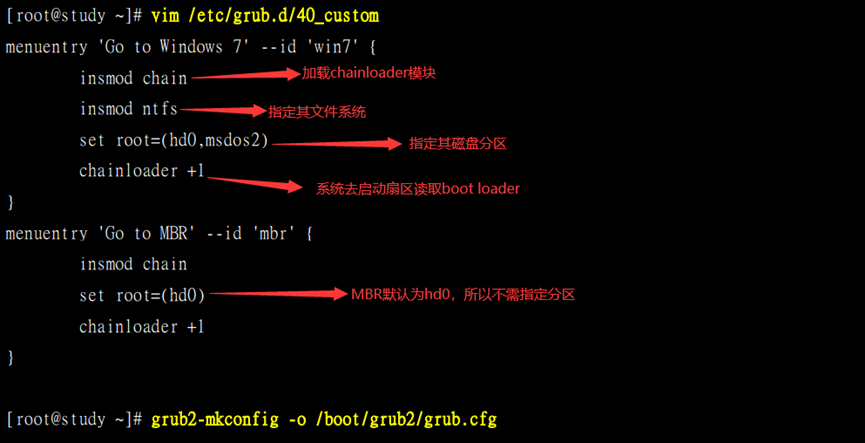
2)转交控制权:通过chainloader实现boot loader控制权的转交
chainloader(启动引导程序的链接):将控制权转交给其他boot loader
//所以grub2就不需要识别每个内核的文件名,只将控制权转交给下一个boot loader或MBR中的boot loader即可
(也不需要识别下一个boot loader的文件系统)
制作步骤:
(1)加载chainloader模块;
(2)指定转交至的文件系统;
(3)指定转交至的硬盘分区;
(4)设置系统去启动扇区读取boot loader软件
如:设置两个启动选项,取得Windows 7启动选项和回到MBR默认环境的选项
1)查看当前MBR设备分区信息

2)配置/etc/grub.d/40_custom文件
启动管理
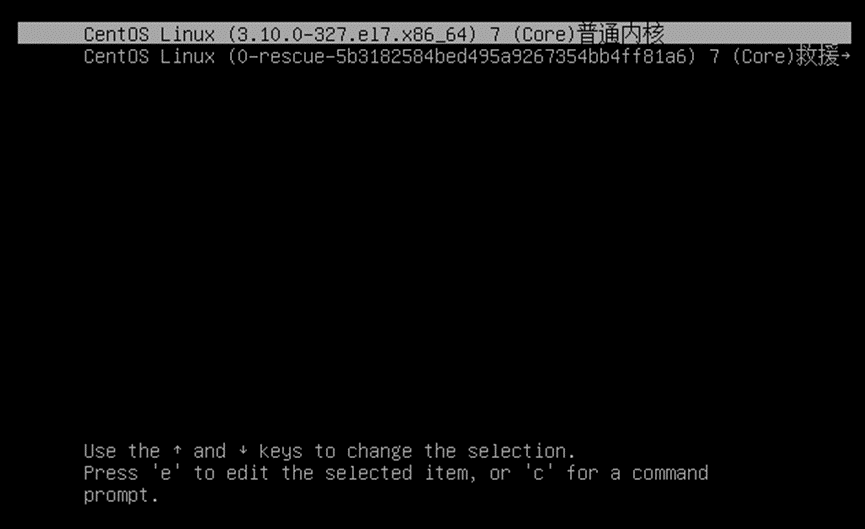
配置grub2完成各个配置文件后,其启动效果如下:
1)系统启动时,当进行到该界面时就是已经由grub2管理
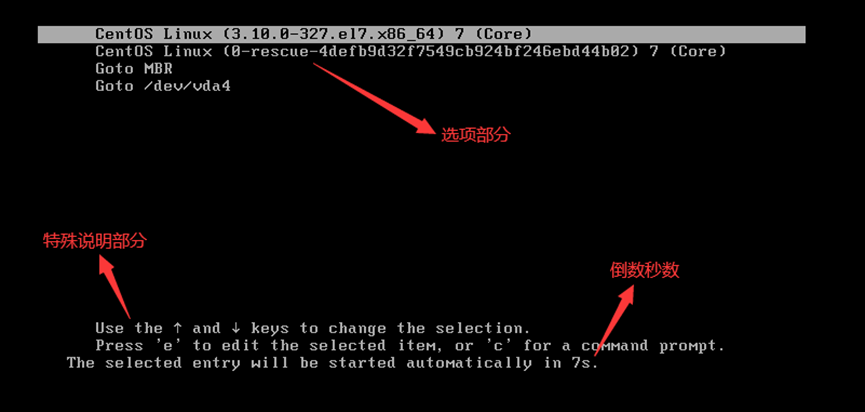
//设置默认显示选项,所以可在5个选项中选择其中一个内核运行
//在该界面按“e”进入对应选项内核的grub2在线编辑,按“c”进入grub提供的shell模式
2)按“e”进入grub2在线编辑后,显示该界面;上方;grub.cfg文件的内容,可通过方向键查看/编辑;下方;编辑说明/帮助
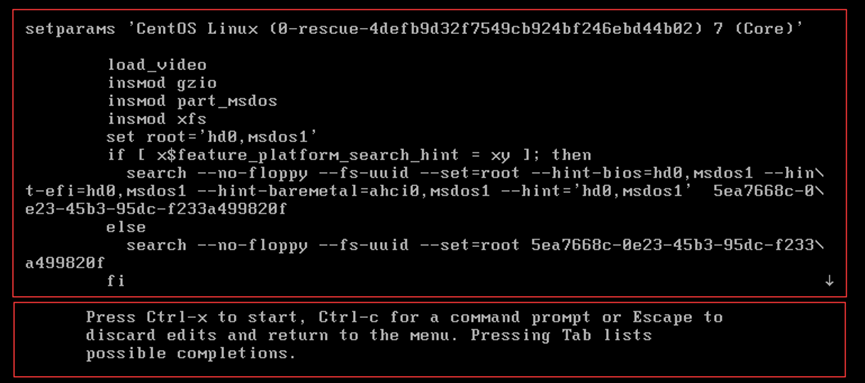
//取消当前操作并回到前一个画面:ESC或Ctrl和C,直接启动:Ctrl和X
如:在启动过程以图形过程显示,且显示中文
1)编辑/etc/default/grub文件,并grub2-mkconfig
2)再在grub2配置文件的中文,启动时可显示如图
grub2用户:grub2有同Linux的用户管理架构,其用户身份分为两种
//grub2默认允许任何人修改和选择的,且没有设置任何用户身份
//通过grub2用户管理可实现内核使用和修改的权限配置
1)superusers(管理员用户):在grub2下具有修改和选择所有内核的权限
//设置superusers后,所有的命令修改都会成受限制的
2)users(普通用户):在grub2下仅能选择指定选项,不能修改任何内核
通过配置/etc/grub.d/40_custom文件实现grub2用户的管理
//配置/etc/grub2/grub.cfg也可实现grub2用户的管理(不建议)
如:当前系统配置三个操作系统,分别安装在(hd0,1)、(hd0,2)和(hd0,3),其中
(hd0,1)是所有人都可使用的系统;
(hd0,2)是仅系统管理员可使用的系统;
(hd0,3)是仅系统管理员和指定用户可使用的系统
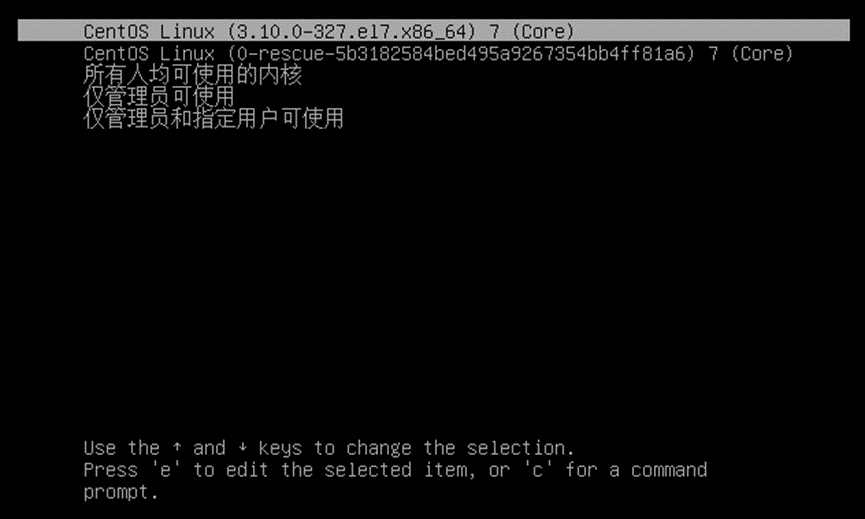
1)配置/etc/grub.d/40_custom文件,并grub2-mkconfig更新grub.cfg文件;
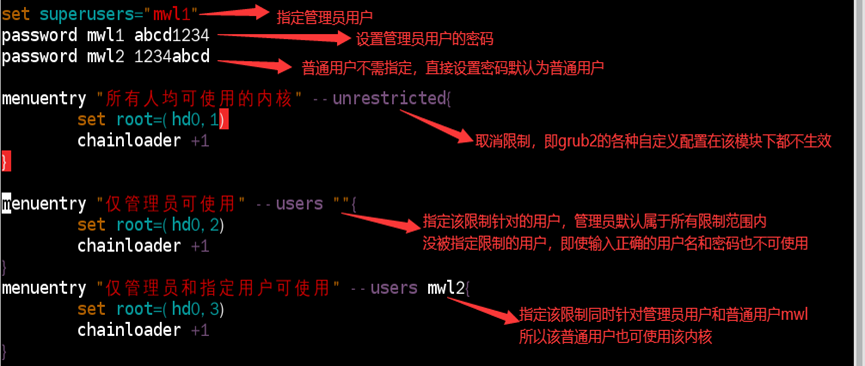
//password也可替换为password_pbkdf2(密文密码)
//若内核配置中加入“–unrestricted”参数代表该内核启动时不需要grub2的用户验证,但进入内核在线编辑时,需grub2的用户验证
2)启动时,多出三个选项
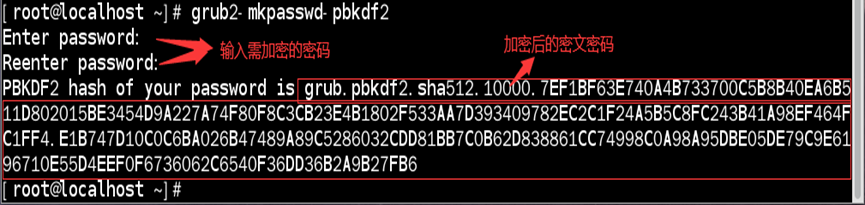
grub2-mkpasswd-pbkdf2命令:根据输入的密码,生成密文密码
指令格式:grub2-mkpasswd-pbkdf2
如:将密码“123456789”加密成密文密码
grub2在线编辑能够实现修改root密码和修改系统等对系统影响巨大的功能,所以需要通过设置grub2进入在线编辑验证登陆,提高系统安全性
//优先级:grub2管理员用户验证 > grub2验证登录,若/etc/grub.d/40_custom和/etc/grub.d/01_users同时存在验证登录,则以/etc/grub.d/40_custom的管理员用户验证登录为准
通过配置/etc/grub.d/01_users文件实现grub2在线编译的验证登录
//也可配置/etc/grub.d/00_header实现,但该文件较为重要(不建议配置)
//由于/etc/grub.d目录下的文件都是被其他脚本所执行的文件,所以不能直接写入用户名和密码,而是通过cat和echo等命令将用户名和密码写入到文件中
如:配置grub2在线编辑验证登录用户名为“mwl3”,密码为“123456789”
1)配置/etc/grub.d/01_users文件;
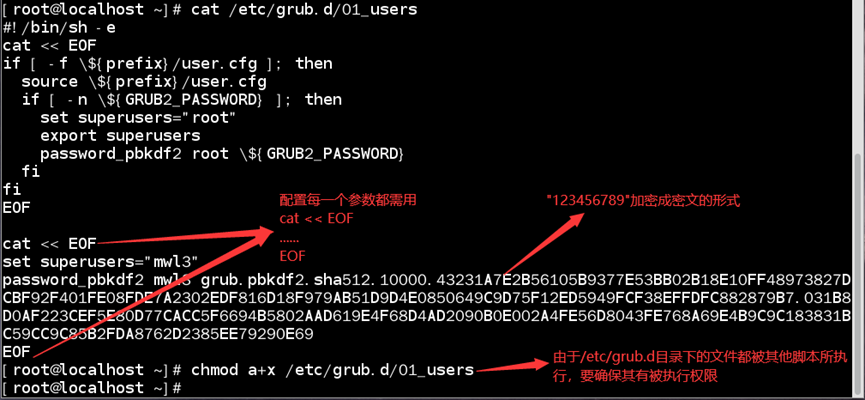
2)重启再次进入grub2在线编辑模式时

修改root密码
通过grub2在线编辑功能实现root密码的修改,步骤:
1)在grub2选项界面时,按“e”进入在线编辑;
//若grub2设置密码,输入密码进入
2)在内核参数设置中添加“rd.break”内核参数;
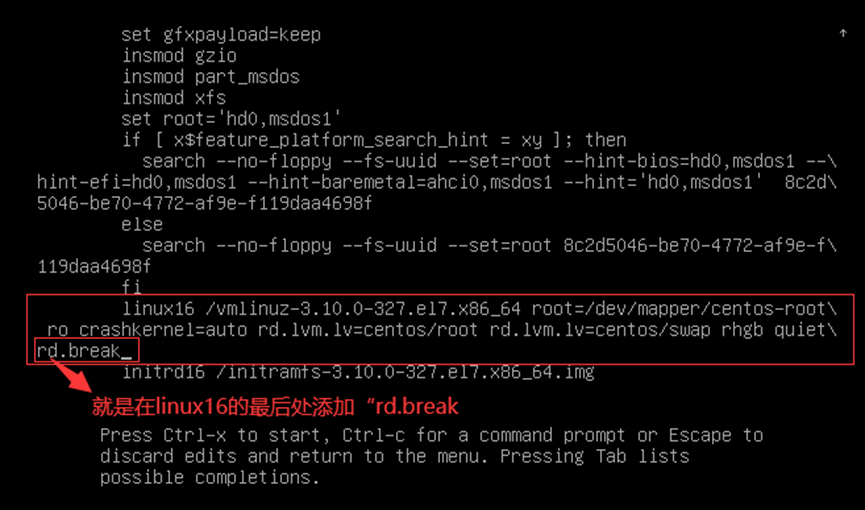
3)按下“Ctrl和X”,等待系统进入rd.break系统状态(紧急救援模式);
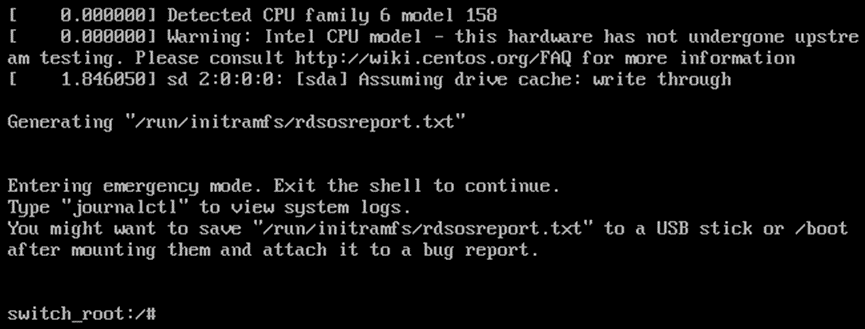
4)输入以下指令:
挂载/sysroot目录:mount -o remount,rw /sysroot
切换到实际系统的根目录:chroot /sysroot
修改root密码:echo “root密码” | passwd --stdin root
恢复SELinux上下文:touch /.autorelabel
退出系统实际目录:exit
重启:reboot
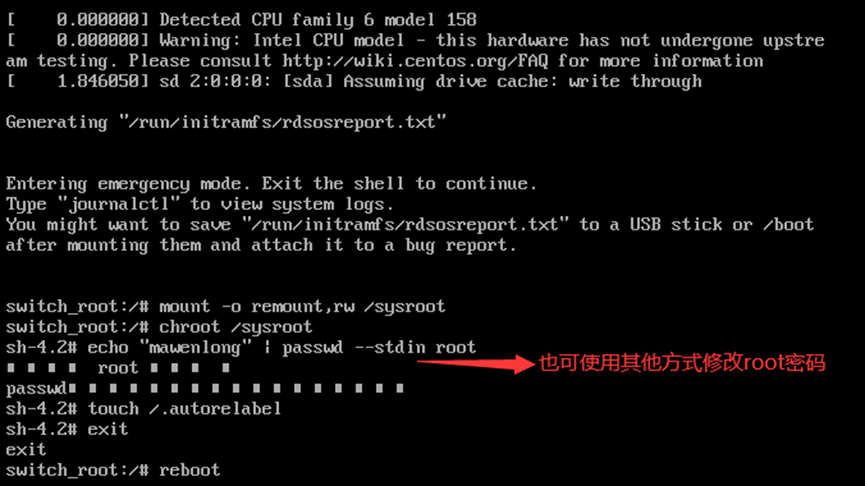
//由于autorelabel使系统重新写入每个文件的SELinux类型,所以启动时间较长
chroot命令:切换系统根目录为指定目录
指令格式:chroot 挂载目录
修改root密码的步骤原理:
1)rd.break内核参数可使系统进入RAM Disk操作系统状态(拥有root权限);此时,所有的目录都属于RAM Disk(原系统根目录挂载在/sysroot目录下);
2)需要将/sysroot目录挂载,并具有可读写权限;用chroot命令切换到/sysroot目录下,并修改root密码;
//切换到原系统根目录下,就可处理原系统的文件系统和用户管理等
3)由于在rd.break系统状态下,系统不具有SELinux功能,而修改root密码导致/etc/shadow文件的SELinux安全上下文被取消,就需通过/.autorelabe使系统在启动时使用默认的SELinux类型重新配置每个文件的SELinux安全上下文
//若不恢复该文件的SELinux安全上下文会导致启动无法正常启动
另一种恢复SELinux安全上下文步骤:
1)在rd.break系统状态下,修改root密码后,修改SELinux的运行模式为“permissive;
2)重启,以root身份登录系统并输入“restorecon -Rv /etc”恢复/etc目录下所有文件的SELinux安全上下文
3)再将SELinux的运行模式改为Enforcing
另一种修改root密码的步骤:
1)在grub2选项界面时,按“e”进入在线编辑;
2)在内核参数设置中添加“init=/bin/bash”内核参数;
//系统提供一个bash,同时不需输入root密码也具有root权限
由于是默认bash环境,其PATH仅有/bin(也没有Syetemd或init),所以在执行各种命令时,需输入绝对路径
3)输入以下指令:
挂载/目录:mount -o remount,rw /
修改root密码:echo “root密码” | passwd --stdin root
恢复SELinux上下文:touch /.autorelabel
重启:硬件强制重启(断电)
//Linux不能随意关机,容易导致文件系统错乱或某些服务无法启动