企业网站管理系统设计报告哪款地图可以看到实时街景
一、场景:
产品要求做一个时间步骤条,使用目前后端已返回的数据进行操作实现。时间步骤条要求日期和时间分开显示且相同日期只显示第一个日期。
图左边为实现效果,右边为后台返回的接口。接口中current字段表示当前到达第几步,从0开始,对应显示数组的前几个展示。后台返回的是一个整的日期时间字段dateTime。
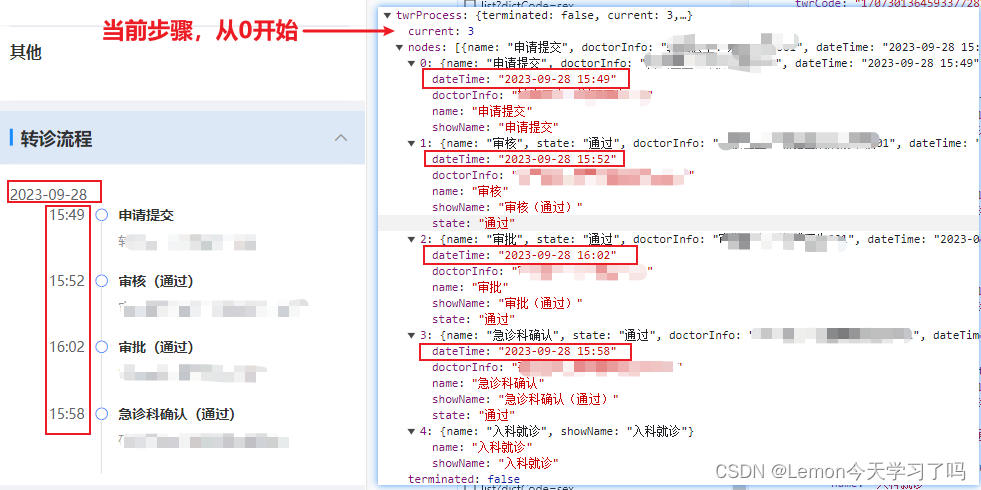

二、处理思路:
- 拿出nodes数组对象中与current字段对应的步骤数据放入新数组slicedNodes;
- 再循环处理slicedNodes数组对象里的dateTime字段,将其拆分成date, time两个字段;
- 比较date字段是否有重复的,没有则赋值该字段到一个新数组prevDate;
- 将新数组添加到result数组即可组装完成。
三、代码实现:
computed: {// 过程数组processedNodes() {// 将数组截取的副本返回到新的数组对象:array.slice[start, end)const slicedNodes = this.twrProcess?.nodes.slice( 0, parseInt(this.twrProcess?.current,10) + 1);const result = [];let prevDate = null;slicedNodes?.forEach((node) => {// 将dateTime日期时间字段拆分成date, time两个字段const [date, time] = node.dateTime.split(" ");const newObj = { ...node };// 将不一致的date放入newObj.dateif (date !== prevDate) {newObj.date = date;prevDate = date;}newObj.time = time;result.push(newObj);});return result;},},