西安自助建站系统在域名上建设网站
近年来,国内视频监控应用迅猛发展,系统接入规模不断扩大,导致了大量平台提供商的涌现。然而,不同平台的接入协议千差万别,使得终端制造商不得不为每款设备维护多个不同平台的软件版本,造成了资源的严重浪费。随着各地视频监控系统大规模建设,省级、国家级对重大事件的视频调阅和指挥需求逐渐增加,但不同平台间的互通协议却相对缺乏统一标准。
在这样的背景下,GB/T28181标准应运而生,以满足终端标准化和平台互联互通的需求。GB/T28181-2011《安全防范视频监控联网系统信息传输、交换、控制技术要求》由公安部科技信息化局提出,由全国安全防范报警系统标准化技术委员会(SAC/TC100)领导,多家单位共同起草,成为国家标准。
该标准类似于ONVIF协议,旨在简化视频监控设备的互联。两者都基于IP网络,但接入时需要相应的协议转换模块。它们并非互斥,可以在接入上相辅相成。例如,网络摄像机通过ONVIF协议接入NVR,再通过GB/T28181标准接入平台,或者网络摄像机直接通过ONVIF协议接入平台,再通过GB/T28181实现平台间级联。
GB/T28181还支持模块化设计和分布式部署,包括设备管理、信令、流媒体和存储模块,允许多个中心信令服务器和流媒体负载均衡部署,支持RTSP、RTMP等多种流媒体访问协议,以及对摄像机的云台控制,适用于新建和部分建设的数字监控网络。
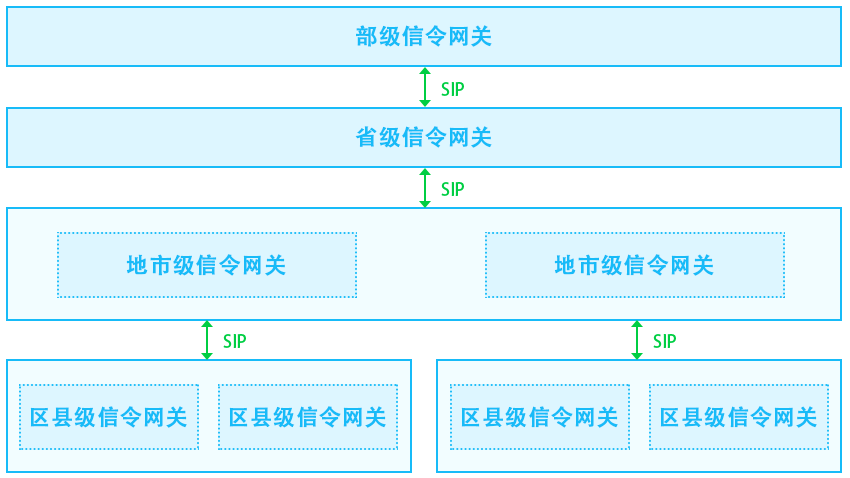
此外,GB/T28181支持区域平台级联,构建了三级平台级联模式,有效解决了资源共享问题,使得高级别安防平台能够查看下级单位的视频资源。在国标推广下,支持GB/T28181成为前端设备的必然选择,为安防监控系统的互联网级直播和管理提供了广泛可能性。
总体而言,GB/T28181为解决视频监控系统互联提供了新的机会和可能性,为互联网视频直播带来了更多的发展空间。