网站工程师是做什么的专业简历制作
随着科技的不断进步,USB Type-C接口在电子产品中越来越普及。而在这个接口中,Type-c受电端协议芯片起着至关重要的作用。那么,什么是Type-c受电端协议芯片?它又是如何工作的呢?本文将为您揭开Type-c受电端协议芯片的神秘面纱。

一、什么是Type-c受电端协议芯片?
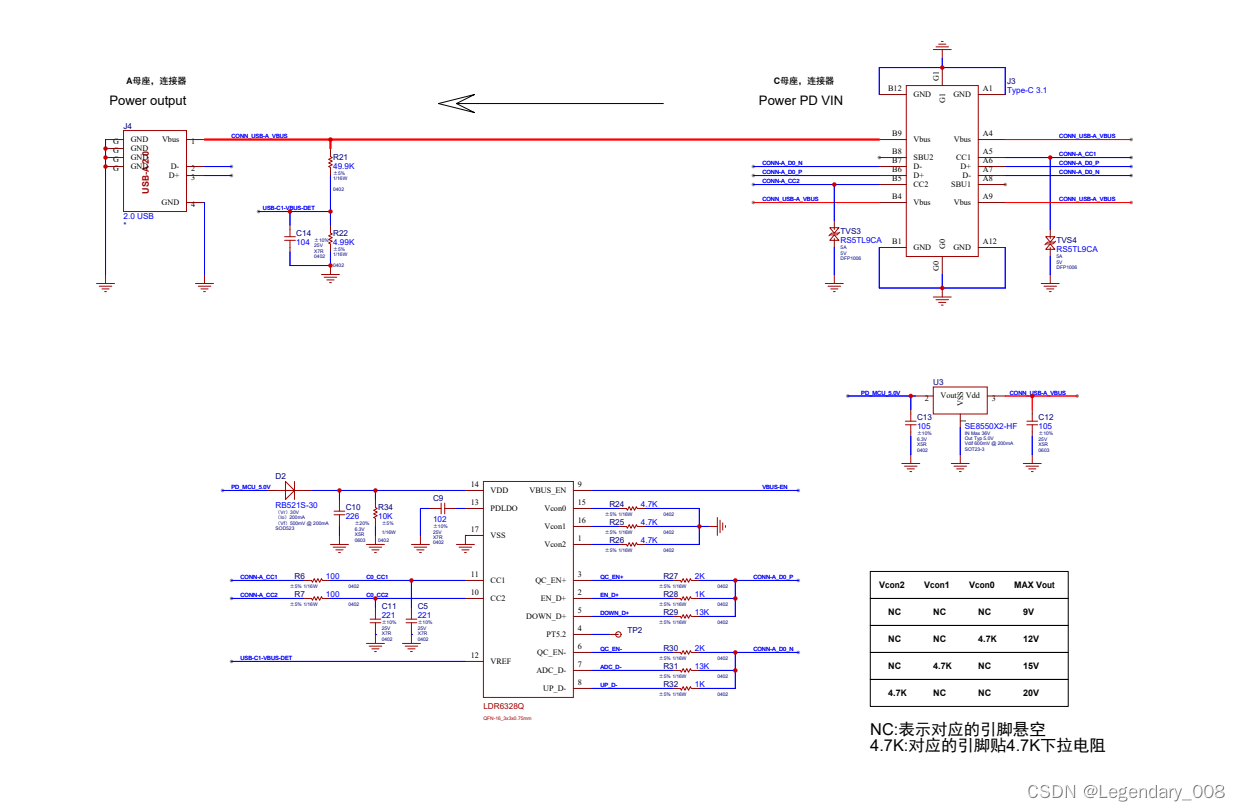
Type-c受电端协议芯片LDR6328Q,它负责管理USB Type-C接口的电源和数据传输。这种芯片遵循USB Type-C规范,支持多种电力传输模式,如USBPD,QC,AFC, SFP等。通过Type-c受电端协议芯片,设备可以更加灵活地实现快速充电功能。
二、Type-c受电端协议芯片的工作原理

Type-c受电端协议芯片的主要功能是管理电源和数据传输。在充电过程中,它可以根据设备的需要自动调整供电电压和电流的大小,以保证充电的安全和稳定。
此外,Type-c受电端协议芯片还具备检测设备和识别电缆的能力。它可以通过检测信号的反馈来判断设备的插入状态,以及电缆的连接是否正常。如果设备或电缆出现异常情况,它会及时采取保护措施,防止设备受到损坏。
三、Type-c受电端协议芯片的应用场景
由于Type-c受电端协议芯片具有诸多优点,它在许多领域都得到了广泛应用。例如,在智能手机、平板电脑等便携式设备中,Type-c受电端协议芯片可以实现快速充电和数据传输;在显示器、笔记本电脑等设备中,它能够提供更高的数据传输速率和更灵活的连接方式;在充电桩、车载充电器等充电设备中,Type-c受电端协议芯片可以实现快速充电和更高的充电功率。
四、Type-C受电端协议芯片介绍
LDR6328Q 是乐得瑞科技有限公司针对 USB PD 协议、Quick Charge(简称 QC)协议和 AFC 协议开发的一款兼容 USB PD、QC 和 AFC 的通信芯片。输入端主要接 PD、QC 和 AFC 的适配器,输出端配置输出固定的电压。LDR6321 从支持 USB PD、QC 和 AFC 协议的适配器取电,然后供电给设备。比如可以配置适配器输出需要的功率,给后端供电设备供电。
特点
◇ QFN-16_3x3 小封装
◇ 兼容 USB PD 3.0 规范,支持 USB PD 2.0
◇ 兼容 QC 3.0 规范,支持 QC 2.0
◇ 支持三星 AFC,华为SCP 协议
◇ 可配置输出 5V、9V、12V、15V、20V 等电压
◇ 可自动选择输出 9V、12V、15V、20V 电压以内的最高电压
3、应用
◇ 所有需要适配器(支持 USB PD、QC 和 AFC 协议)供电的设备
◇蓝牙音箱,落地扇,小家电产品等需要快充输入设备
五、Type-c受电端协议芯片的优势与挑战
Type-c受电端协议芯片的优势在于其灵活性和多功能性。它支持多种电力传输模式,可以满足不同设备的充电需求。同时,Type-c接口具有正反插的特性,使用起来非常方便。此外,Type-c接口的数据传输速率也远高于传统的USB接口。
然而,Type-c受电端协议芯片也面临一些挑战。首先,由于其高度的智能化和多功能性,对芯片的设计和制造工艺要求较高。其次,随着技术的不断发展,如何保持与新标准的兼容性和同步性也是一个难题。此外,如何保证充电的安全性和稳定性也是Type-c受电端协议芯片面临的重要问题。
六、未来展望
随着USB Type-C接口的不断普及和技术的不断进步,我们相信Type-c受电端协议芯片的功能将越来越强大,应用场景也将越来越广泛。未来,我们期待看到更加高效、安全和智能的Type-c受电端协议芯片的出现,以满足不断增长的数据传输和充电需求。同时,我们也期待相关技术的不断发展,为Type-c受电端协议芯片的应用提供更多的可能性。