各大网站vip接口建设南昌网站设计单位公司
动态内存管理面试题
文章目录
- 动态内存管理面试题
- 一、第一题
- 此代码存在的问题
- 运行结果
- 分析原因
- 修改
- 二、第二题
- 此代码存在的问题
- 运行结果
- 分析原因
- 修改
一、第一题
代码如下(示例):
#include<stdio.h>
#include<string.h>
#include<stdlib.h>void GetMemory(char* p)
{p = (char*)malloc(100);//申请100个字节的临时空间,将起始地址放入p
}
void Test(void)
{char* str = NULL;GetMemory(str);strcpy(str, "hello world");printf(str);
}int main()
{Test();return 0;
}
此代码存在的问题
运行结果
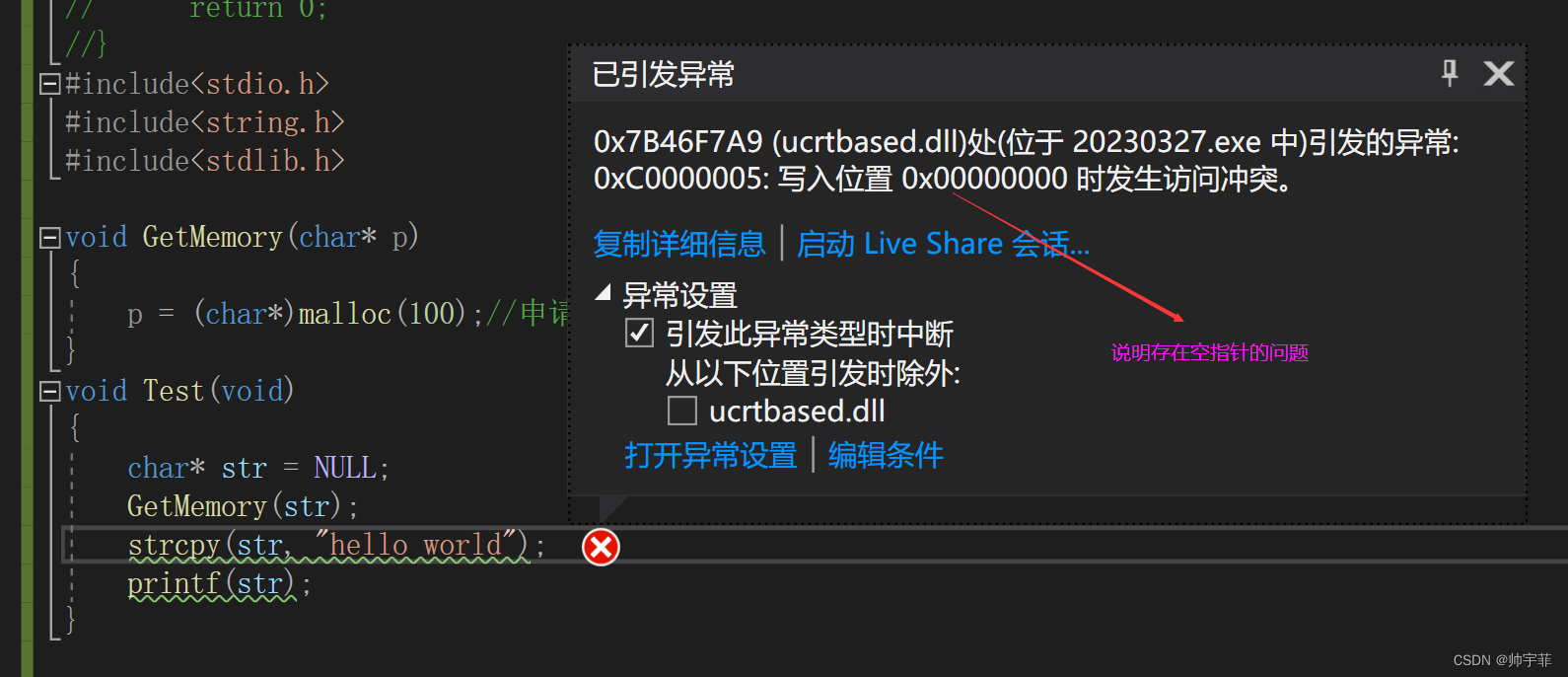
分析原因

修改
#include<stdio.h>
#include<string.h>
#include<stdlib.h>void GetMemory(char** p)
{*p = (char*)malloc(100);//申请100个字节的临时空间,将起始地址放入p
}
void Test(void)
{char* str = NULL;GetMemory(&str);strcpy(str, "hello world");printf(str);//释放free(str);str = NULL;
}int main()
{Test();return 0;
}
主要修改的地方就是将str的地址传入函数当中去修改str本身
二、第二题
代码如下(示例):
#include<stdio.h>
#include<string.h>
#include<stdlib.h>char* GetMemory(void)
{char p[] = "hello world";return p;
}
void Test(void)
{char* str = NULL;str = GetMemory();printf(str);
}int main()
{Test();return 0;
}
此代码存在的问题
运行结果
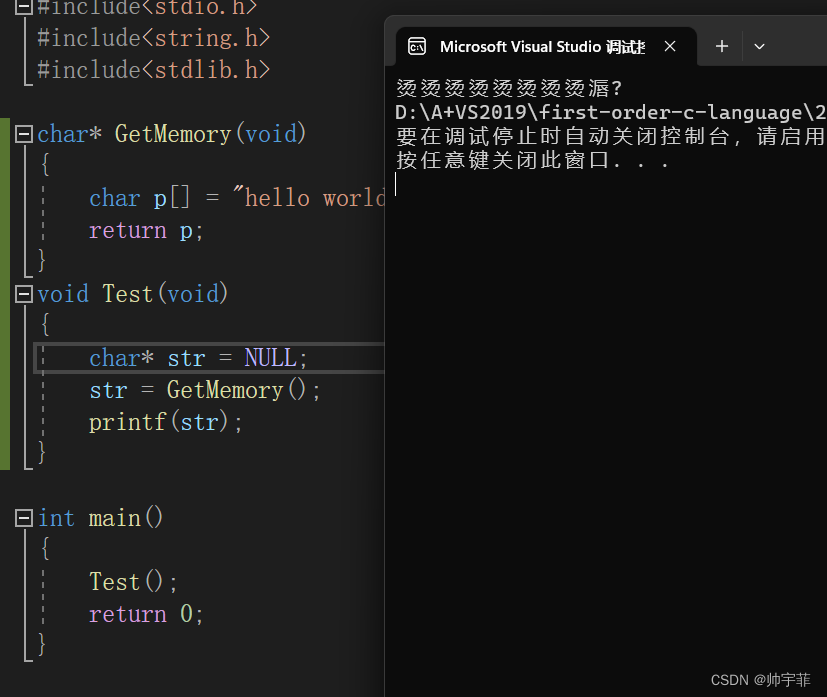
分析原因
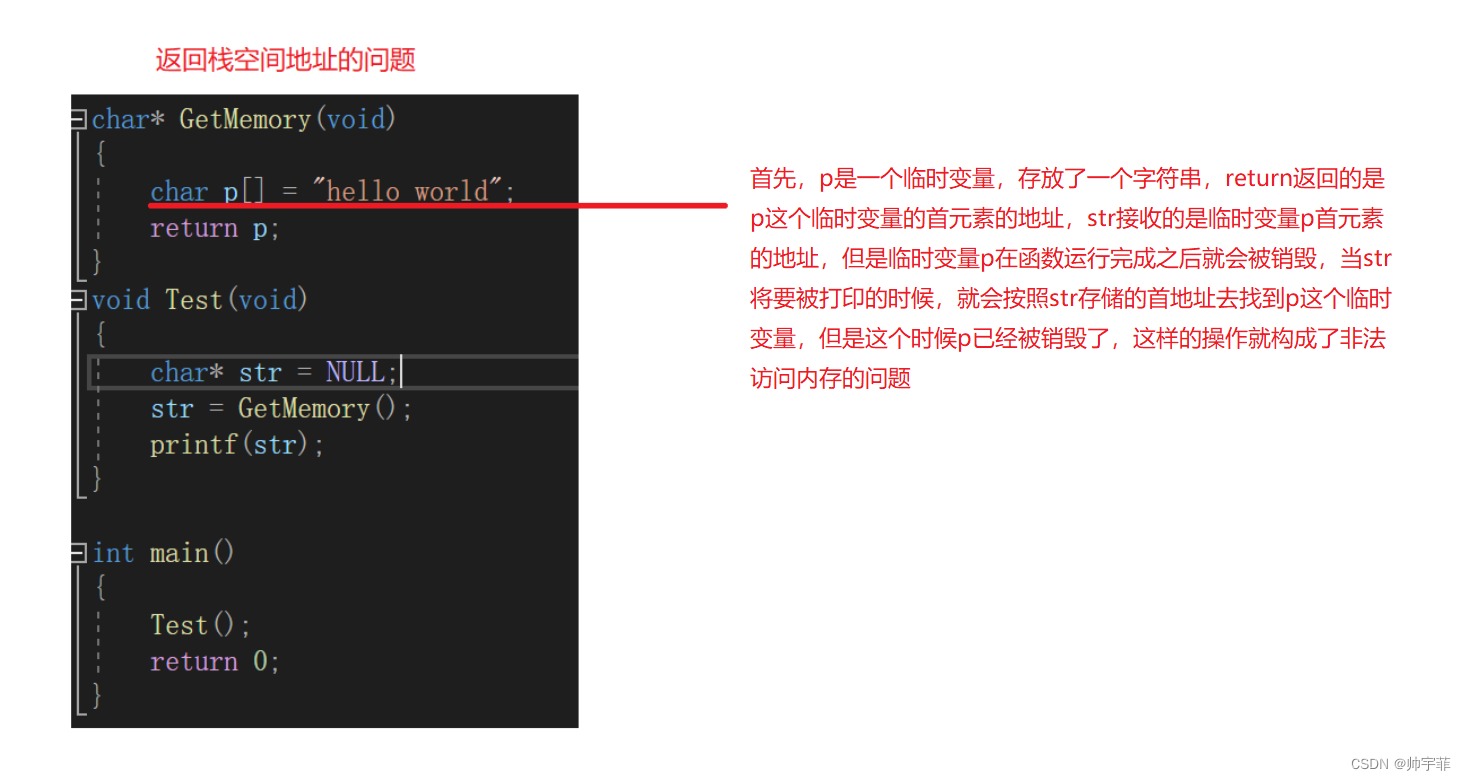
修改
#include<stdio.h>
#include<string.h>
#include<stdlib.h>char* GetMemory(void)
{char* p = "hello world";return p;
}
void Test(void)
{char* str = NULL;str = GetMemory();printf(str);
}int main()
{Test();return 0;
}
char* p = “hello world”; 将常量字符串的地址传给str,即使p被销毁了,那么常量字符串还在,p只是一个首地址的存储,不会影响最终的打印