网站建设与网页设计制作书籍wordpress正则
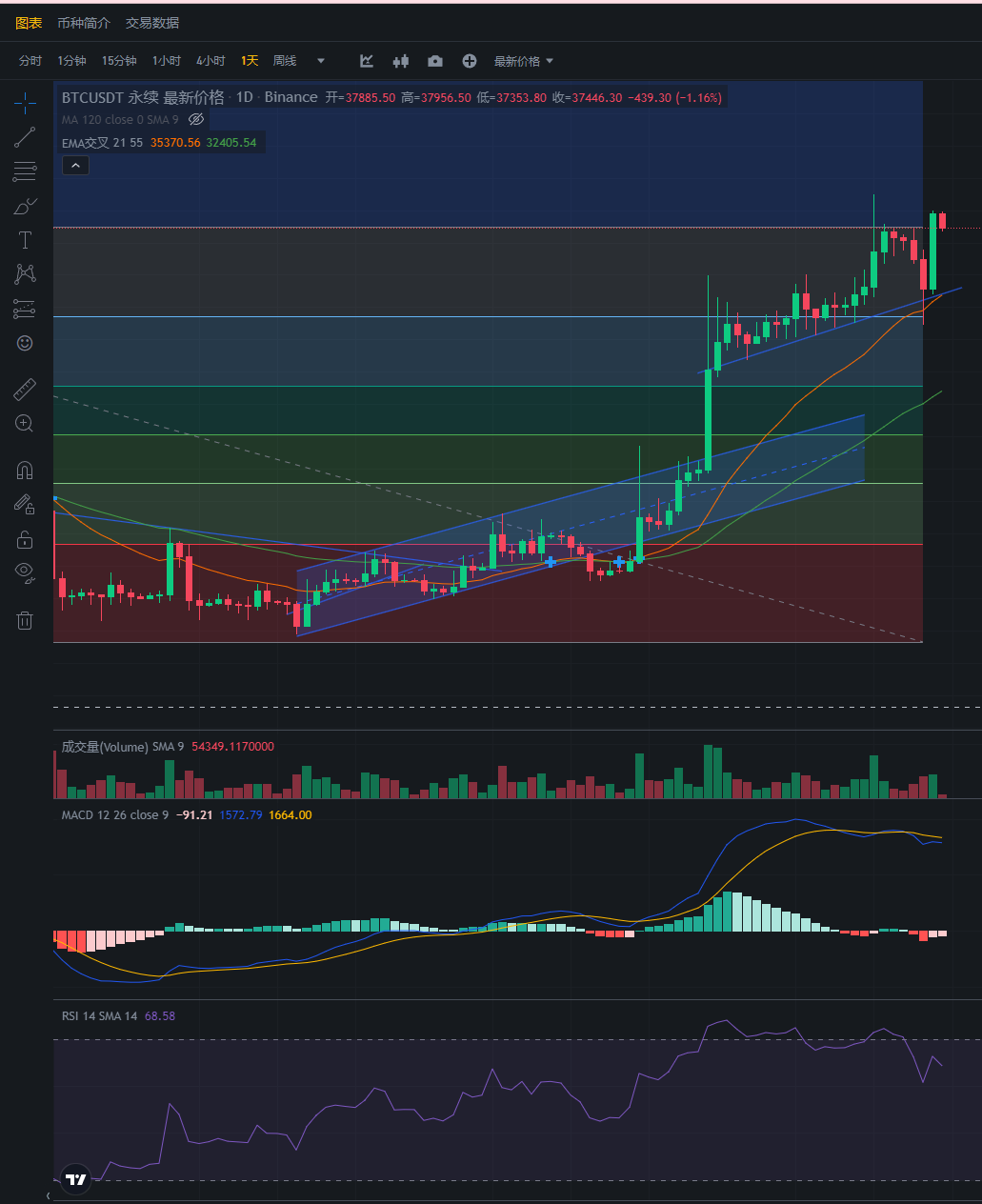
大饼昨日突然回调诱多上涨到38000附近,现在又重新跌回到37500,现在仓位小的可以加仓入场,而已经有仓位的不要动即可。
空单策略:入场37500附近 止盈34000-32000 止损39000
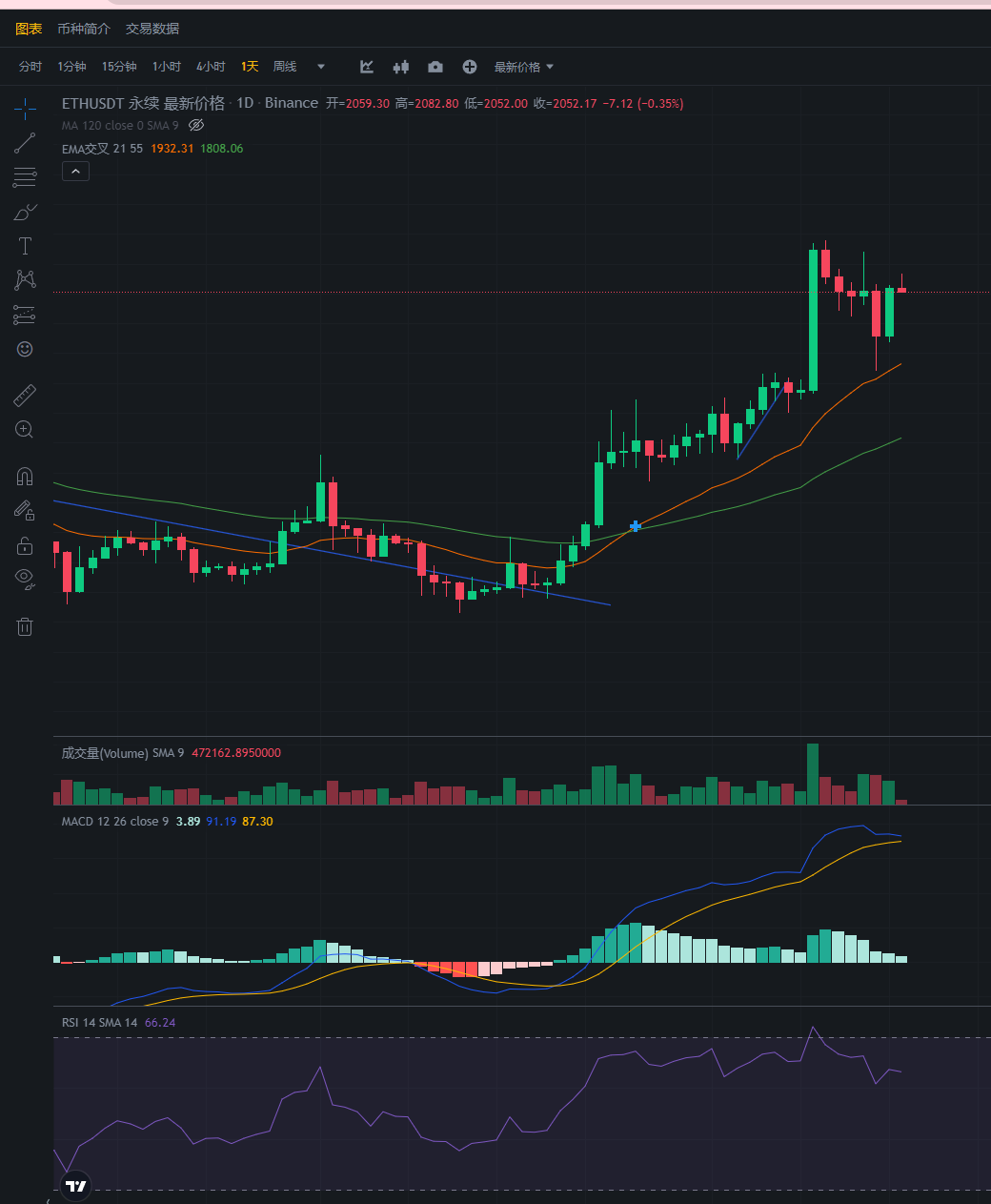
以太今日可以入场空单2060附近即可
策略:入场2060 止盈1950-1920 止损2150
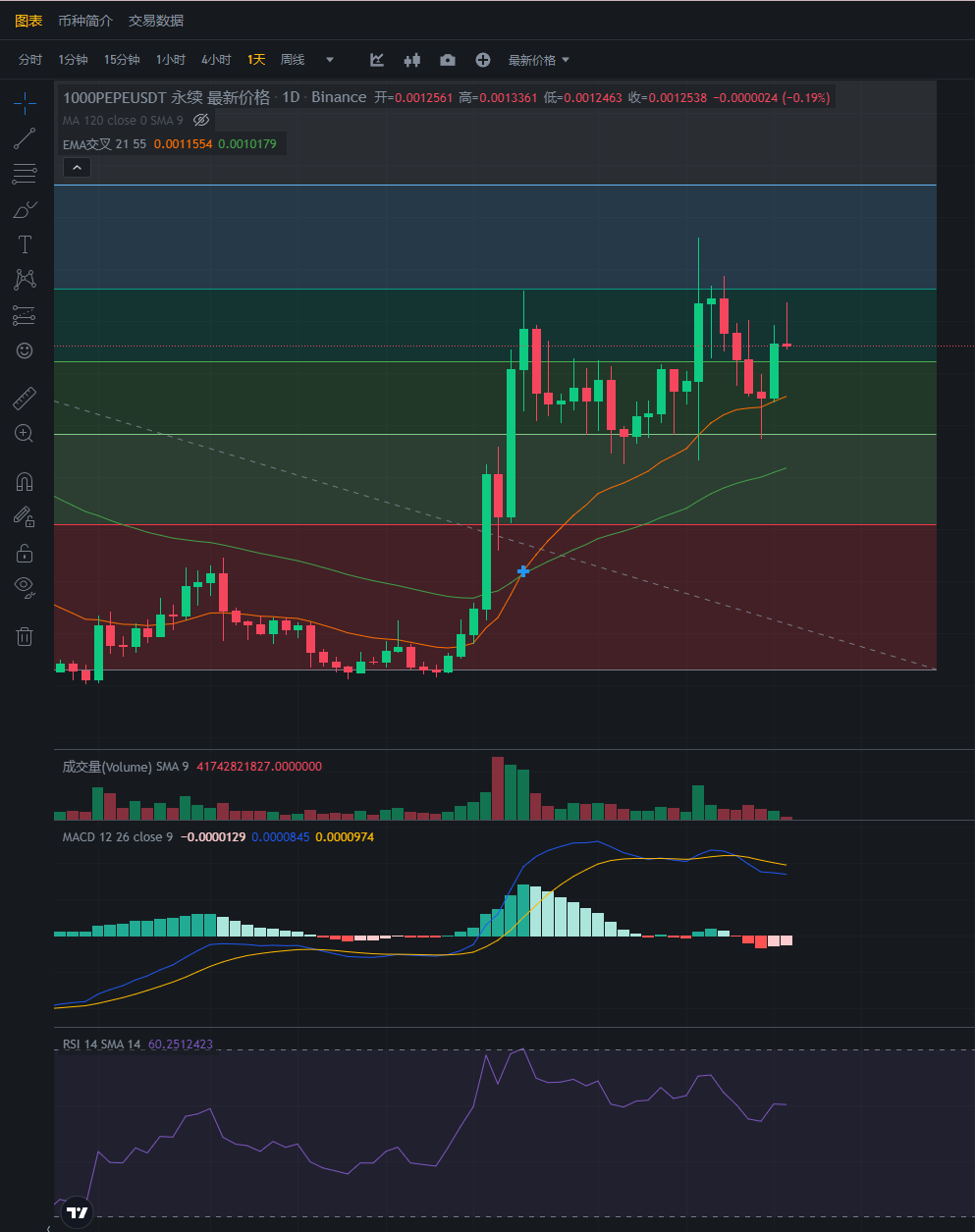
接下来看看山寨行情,昨日大盘回调,山寨普涨。
Pepe山寨最近上涨都很猛,反弹也很猛,可以不入场。
MACD四小时空单策略:入仓0.00125 止盈0.00113-0.00108 止损0.00135
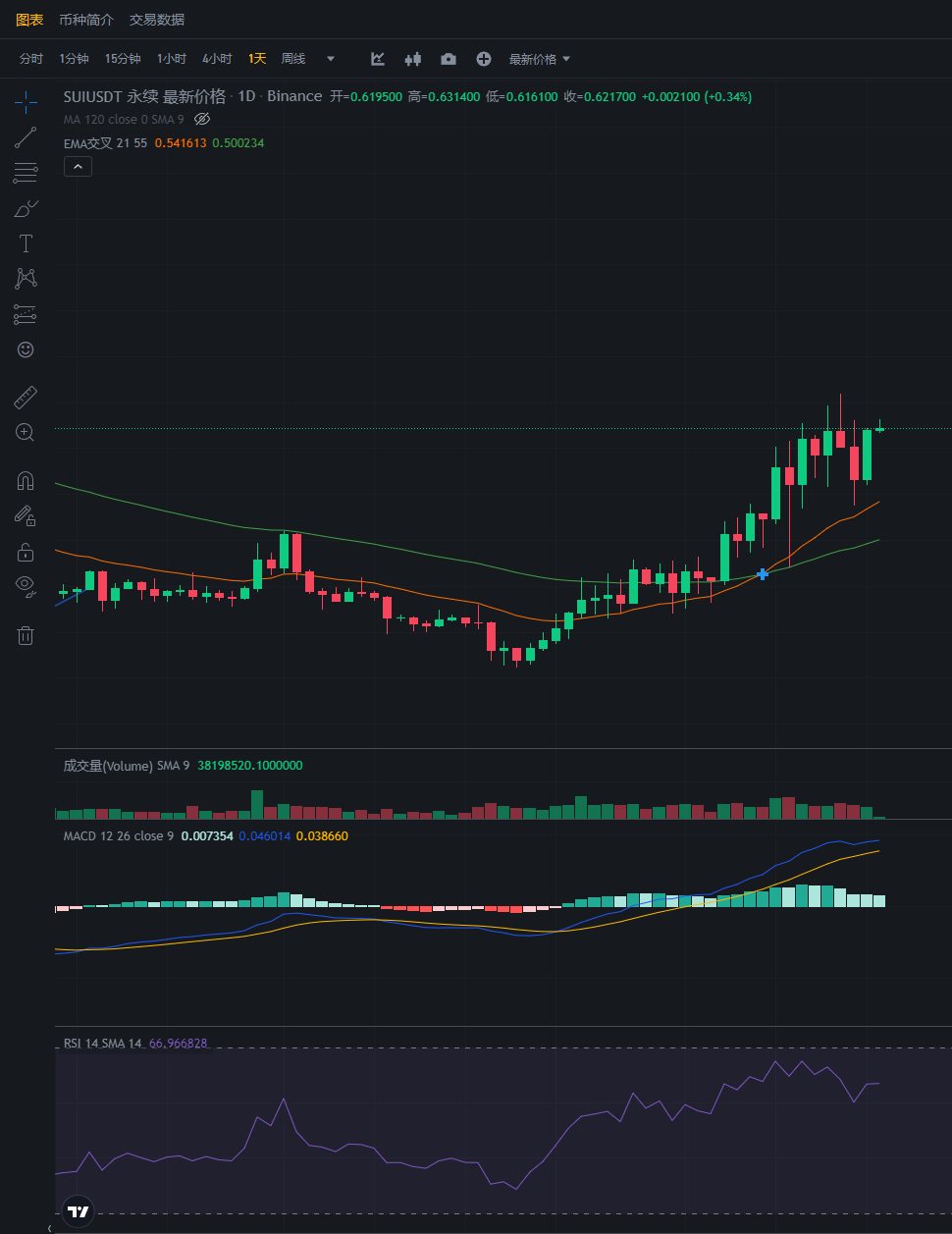
Sui目前现在价格0.62,昨日已经打了止损,暂时不碰。
总结
笔者建议稳健的朋友就做大饼和以太,其他山寨不碰。