网站建设的实训报告的实训感受悬停提示 wordpress
最近因为项目原因需要在阿里云服务器上部署MongoDB,操作系统为Ubuntu,网上查阅了一些资料,特此记录一下步骤。
1.运行apt-get install mongodb命令安装MongoDB服务(如果提示找不到该package,说明apt-get的资源库版本比较旧,运行apt-get update来更新资源库)
![]()
2.安装好后输入mongo测试
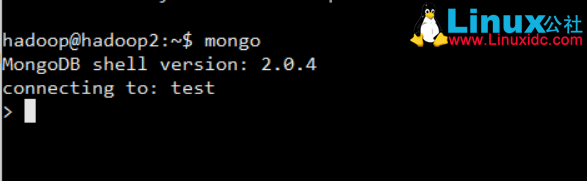
如果成功进入mongo命令行界面就证明安装成功了
3.如果想要关闭,开启,重启mongodb服务
sudo systemctl status mongodb
sudo systemctl start mongodb
sudo systemctl restart mongodb
3. 设置服务开机自启动
sudo systemctl enable mongod
由于项目需要,我需要设置能够允许远程连接该服务器上的mongodb数据库
编辑mongodb的配置文件 sudo vi /etc/mongodb.conf:
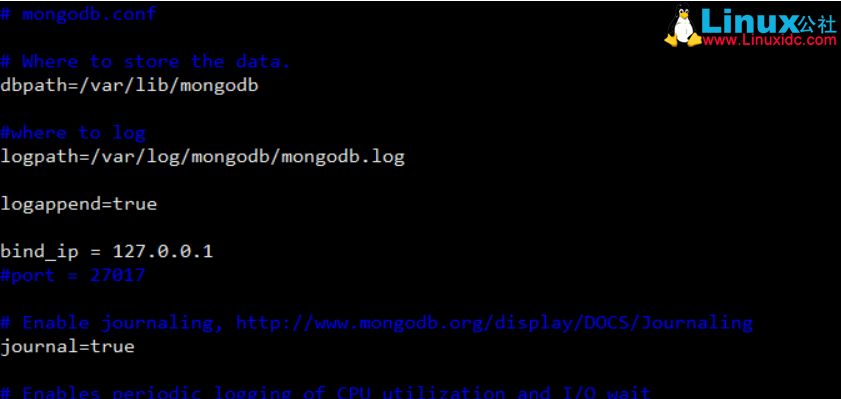
dbpath是数据存放的地址修改为你想存放的路径
logpath是日志存放的地址同理
另外将bind_ip注释掉或者改为 0.0.0.0,因为bind_ip是127.0.0.1的话只允许本地IP连接mongodb数据库
修改后
MongoDB 默认安装完成以后,默认安装的MongoDB是无账号密码即可访问的;为了连接的安全性必须开启认证登录以保证数据的安全性
开启认证登录:auth = true
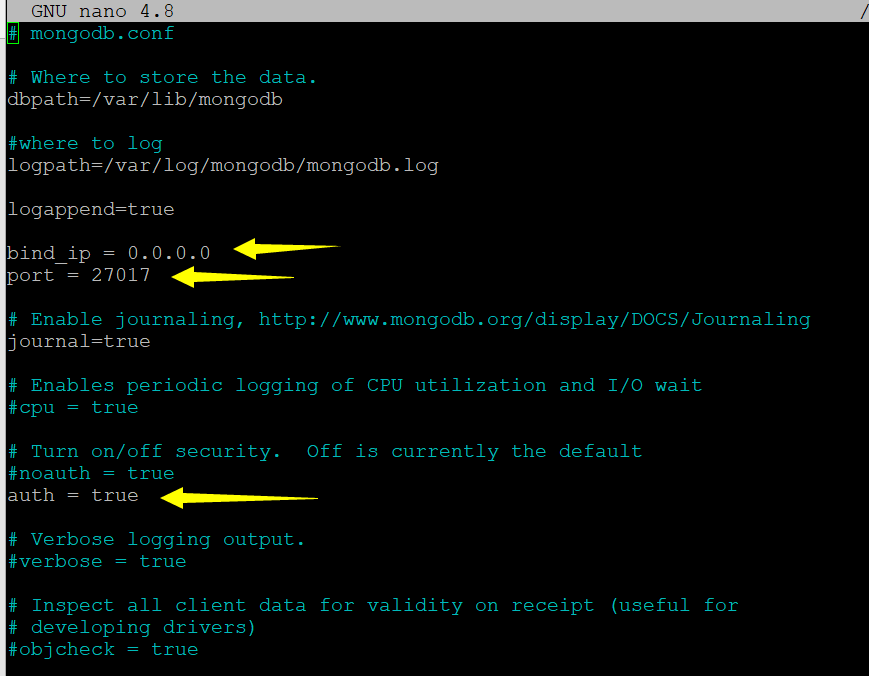
创建超级用户
use admin;
db.createUser({user: 'admin', pwd: 'admin', roles: [{role: 'root', db: 'admin'}]});
# 在"admin"数据库中,创建"admin"用户,密码设置为"admin",授予该用户"超级用户角色"
注:”超级用户角色“拥有数据库最高管理权限,可以管理所有数据库
附:MongoDB权限类型

6.接下来重启服务令修改生效
sudo systemctl restart mongodb
备注:
默认端口27017:
使用mongo命令就可进入到mongo shell,
修改端口后 需要使用mongo --port 端口进入 mongo shell;