网站建设电话销售技巧和话术校园网站建设教程
一、前言
RPS (Request Per Second)一般用来衡量服务端的吞吐量,相比于并发模式,更适合用来摸底服务端的性能。我们可以通过使用 JMeter 的常数吞吐量定时器来限制每个线程的RPS。对于RPS,我们可以把他理解为我们的TPS,我们就不过多解释了。
RPS 取决于压测的并发数以及服务的响应时间,并发数过高,可能压力过大压垮后端服务,并发数过低,可能压不到指定的 RPS。为了避免压力过大压垮后端服务以及摸底后端服务性能上限,可以通过设置常数吞吐量定时器来限制线程的 RPS 上限。接下来我们用很短的篇幅来简单说下如何控制脚本的RPS
二、配置RPS
常数吞吐量定时器的设置十分的简单,这里我们设置的RPS就是21000/60=350RPS。
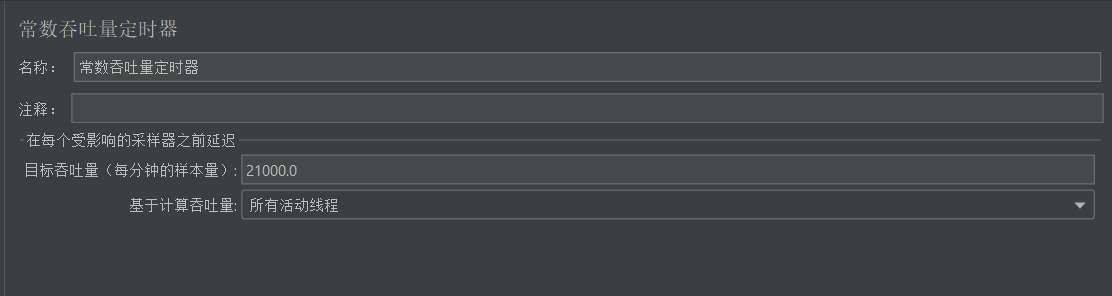
第二个基于计算吞吐量字段,字面意思也很清晰了
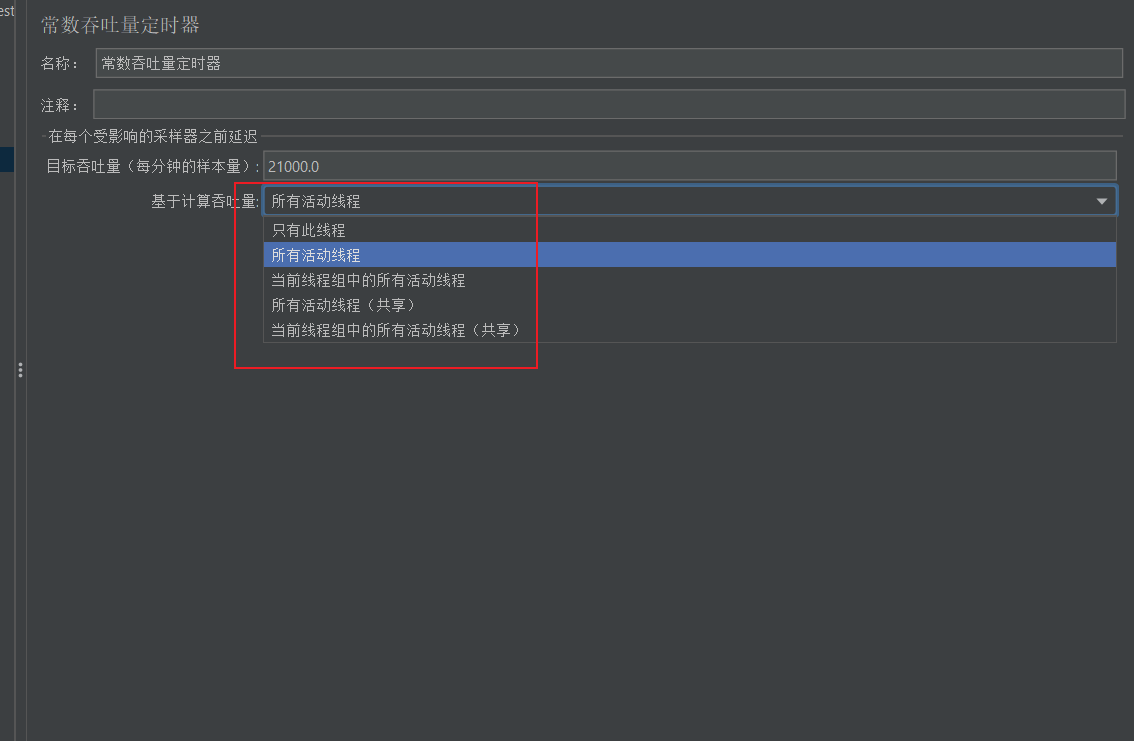
只有此线程:控制每个线程的吞吐量,总的吞吐量为设置的目标吞吐量乘以该线程的数量
所有活动线程:设置的目标吞吐量将分配在每个活跃线程上,每个活跃线程在上一次运行结束后等待合理的时间后再次运行。活跃线程指同一时刻同时运行的线程。
所有活动线程(共享):与所有活动线程的选项基本相同。唯一区别是,每个活跃线程都会在所有活跃线程上一次运行结束后等待合理的时间后再次运行。
当前线程组中的所有活动线程:设置的目标吞吐量将分配在当前线程组的每一个活跃线程上,当测试计划中只有一个线程组时,该选项和所有活动线程选项的效果完全相同。
当前线程组中的所有活动线程(共享):与当前线程组中的所有活动线程基本相同,唯一的区别是,每个活跃线程都会在所有活跃线程的上一次运行结束后等待合理的时间后再次运行。
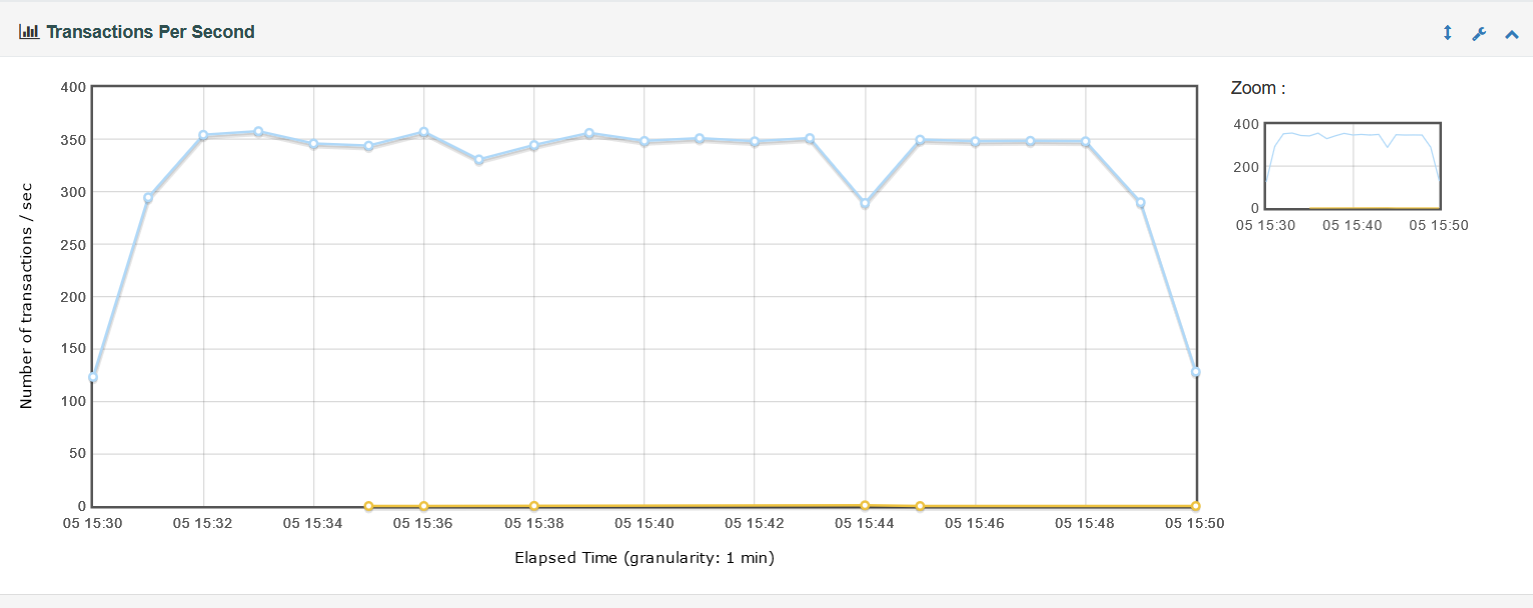
三、运行结果
很明显,运行结果中RPS最高为350左右
以上就是这节的全部内容,如有错误,还请各位指正!
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!
