网站开发费用包括美工费吗互联网网站开发合同范本
第一题 FusionCompute
一、题目介绍
1.1. 扩容CAN节点与对接共享存储(必选)
题目及【考生提醒关键点】
- 扩容一台CNA节点,配置管理地址设置为:192.168.100.212。
- 密码设置为:Cloud12#$。【
输入之前确认自己的大小写是否正确】 - 主机名设置为CNA2。
- 为两个CNA分别添加存储接口,分别为:192.168.21.211/24、192.168.21.212/24。【
本题单独给了一张图,图中标明了4/5口为存储接口对接到存储交换机,下解一台IPSAN设备,单接一个控制器接口】 - 对接物理共享存储OceanStor,lun已经创建好。【
(50G或者100G),给出了管理ip:192.168.21.215;存储ip192.168.21.xxx。web登陆的用户名和密码也都给了。/加共享存储100G的lun,存储管理地址:192.168.21.213,存储业务地址:192.168.21.216,admin/Huawei@123。】
【共享存储给的v3版本,注意接口协议类型,存储中已新建lun和NAS】
【注意:lun已经是创建好的,你需要做的是创建lun组、启动器、主机、主机组,最后创建映射视图,只需要将lun组和主机组建立映射就行(不要去勾选端口组,不需要映射端口组,里面有一个已经建好的端口是nfs+cifs协议的,是给ebackup备份那道题用的,所以不用去管端口、端口组什么的),做好前面的步骤之后就可以去FC添加存储资源。】 - 新建一个空虚拟机,并进行热迁移。【
磁盘必须要选择物理共享存储】
1.2. FC操作(二选一)
1.2.1. EulerOS欧拉1
题目及【考生提醒关键点】
- 将FC里的Euler-temp模板转为虚拟机并命名为EulerOS
- 将EulerOS转为模板并更名为Euler-temp-new,并安装Tools
- 创建 IE-DVS 上行链路为 CNA 的 eth6、7 端口聚合,并创建端口 组 FA 10.0.0.0/24。 FA 端口上联交换机配置如下:
Port link-type hybrid
Port default pvid 120
Untage port vlan 120
【根据上面交换机的配置可得知FA端口vlan设置为0】 - 用Euler-temp-NEW模板发放虚拟机,要求部署过程中完成以下要求:
(1)root 密码统一设置为 Huawei@123;
(2)主机名分别设置为EulerOS1、EulerOS2;
(3)EulerOS1使用端口组Management,IP地址设置为:192.168.100.xxx/24,EulerOS2使用端口组FA,IP地址设置为:10.0.0.xxx/24,要求两台虚拟机可以相互ping通。 - 配置合适的DRS规则,使EulerOS1和EulerOS2运行在不同的主机上
【注意:这里是个坑,你们要先看完整一道题再去操作,因为这个题目要做互斥规则,所以上一道题发放虚拟机EulerOS1、EulerOS2的时候磁盘必须要选择物理共享存储,才能做出效果,所以记住发虚拟机选择磁盘为物理共享存储,不然默认是本地磁盘,又要删了重新发放虚拟机,浪费时间。】 - 登陆estor:192.168.21.xxx:8088,创建1G的lun,给 EulerOS2 添加 1G 的硬件直通存储,使用端口 P0/挂载给Euler0S2作为硬件直通存储使用,eStor中使用端口P0进行映射。
【跟平时练习的步骤一样,该做什么做什么。因为物理存储OceanStor和estor在同一个存储平面,都是192.168.21.0这个网段,所以不需要再去新建一个存储接口,用回原来上一题的存储接口:192.168.21.211/24 192.168.21.212/24就可以】 - 登录 ebackup 创建备份策略、每天 23 点自动备份 EulerOS2
【注意:登陆eackup的用户名和密码都已给出,我考试登陆ebackup的时候,提示:(密码已过期,需要重新更改密码),这时候注意注意注意!千万不能自己去改一个新密码,要跟考官说密码过期了,无论什么题目凡是密码过期都要跟考官说,后台的技术人员会帮你改回原来的密码。考试地址信息表给的是这样的(NFS:192.18.21.xxx HCIE15)没有给出完整的路径,需要你自己会写正确的格式,比如:192.168.21.51:/HCIE15,这才是正确的写法。】
1.2.2. Windows
题目及【考生提醒关键点】
- 将win-tmp模板转换为win10虚拟机(Win10/Huawei@123),修改网卡为DHCP。
- 将虚拟机Win10转换为模板,并改名为win-tmp-NEW,转换为模板。
- 新建一台IE_EVS,上行链路为eth6、eth7做聚合,新建FA端口组。FA端口上联交换机配置:
Port link-type hybrid
Port default pvid 120
Untage port vlan 120 - 使用Win-temp-new模板发放win10-1和win10-2虚拟机,要求在发放中完成以下配置:
(1)设置管理员密码为Cloud12#$;
(2)Win10-1和Win10-2都在WORKGROUP工作组;
(3)Win10-1使用ManageMent分布式交换机,Win10-2使用IE_DVS分布式交换机。【需提前制定虚拟机规格,发放虚拟机时自动按照规格发】 - Win10-1配置地址192.168.100.241/24,网关192.168.100.254;Win10-2配置地址10.0.0.241/24,网关10.0.0.254。Win10-1在management端口组,win10-2在FA端口组,使用正确的配置端口组、安全组配置,要求仅允许Win10-2 ping通Win10-1。
- 设置合适的策略,要求Win10-1虚拟机蓝屏HA虚拟机,Win10-2虚拟机蓝屏原主机重启。
- 给Win10-2添加1G的硬件直通存储(存储管理地址192.168.100.12,业务地址192.168.21.12,admin/Huawei@123,使用端口P0)。【
Estor模拟器,v6版本,和平时练习的一致,只新建了存储池,自己建立lun、端口、主机等】 - 在1G盘中新建一个测试文件,对Win10-2打快照。
- 删掉测试文件后,恢复快照。
二、按题解题
目的:题目是考试会出现,根据解读题目,也能记住解题步骤,将解题步骤跟题目绑定,也可以起到提醒作用。
2.1. 扩容CAN节点与对接共享存储(必选)
题目可以分为四个要求,如下:
要求1:扩容一台CNA节点,配置管理地址设置为:192.168.100.212,密码设置为:Cloud12#$,主机名设置为CNA2。
要求2:为两个CNA分别添加存储接口,分别为:192.168.21.211/24、192.168.21.212/24。
要求3:对接物理共享存储OceanStor,lun已经创建好。
要求4:新建一个空虚拟机,并进行热迁移。
其中,
要求1
“扩容一台CNA节点,配置管理地址设置为:192.168.100.212,密码设置为:Cloud12#$,主机名设置为CNA2。”=“安装CNA,添加CNA主机。”
要求2
“为两个CNA分别添加存储接口,分别为:192.168.21.211/24、192.168.21.212/24。”⟺“配置CNA存储接口。”
要求3
“对接物理共享存储OceanStor,lun已经创建好。”=“配置阵列”=“添加LUN组→启动器→主机→主机组→网络→端口→端口组→主机组和端口组完成映射”
\iff
要求4
“新建一个空虚拟机,并进行热迁移。”
2.2. FC操作(二选一)
2.2.1. EulerOS欧拉1
2.2.2. Windows
三、阅读心得
详细看手册,简记是为了梳理大纲和记忆
来自自己阅读手册
准备:本次测试中使用到访问方式:
登录扩容CNA方式:通过VNC访问192.168.100.212
登录VRM方式:http://192.168.22.15:8088
登录Estor方式:http://192.168.22.15:8088(但视频中用的是OceanStor DeviceManager:https://172.28.164.16:8088与手册不同进行阵列配置,是因为使用的物理阵列管理平台,配置有所不同)
登录BCManager:http://192.168.100.21:8088
一、扩容
(一)安装CNA
通过VNC安装:点击“ctrl+alt+del”,立即按“esc”,按“3”,选“光驱引导”,选“install”。
按“回车”进到Hard Drive:保持默认按“Table”将光标跳转到“OK”,两次“YES”完成磁盘配置。
按“方向键”“回车”进到Network:选IPv4,选eth0,按"Table"到“Manual address configuration”再按“Table”到“IP Address”填“192.168.100.12”和“Netmask”填“255.255.255.0”和“Default Gateway”填“192.168.100.254”【按实际环境地址填写】
按“方向键”“回车”进到Hostname:CNA02。
按“方向键”“回车”进到Password:xx。
按“F12”选“OK”。
(二)添加CNA主机
登录VRM后选“Cluster”,点击“添加主机”:名称填“CNA02”,IP地址填写192.168.100.12。
(三)配置CNA存储接口
登录VRM后选“集群Cluster”→选“主机CNA01”,点击“配置”:
进到“存储”→“存储适配器”:用txt记录下IQN号;【按视频讲,此处之前需要修改IQN号】
进到“网络”→“聚合网口”→“绑定网口”:名称填“bond”,绑定模式填“主备”,勾选“eth1”“eth2”;
进到“网络”→“添加接口”:点击“添加存储接口”,勾选刚创建的“bond”,VLAN ID填“27”,IPv4地址填“192.168.27.11”,子网掩码填“255.255.255.0”。【按实际环境地址填写】
【完成CNA01存储接口,继续CNA02】
登录VRM后选“集群Cluster”→选“主机CNA02”,点击“配置”:
进到“存储”→“存储适配器”:用txt记录下IQN号;【按视频讲,此处之前需要修改IQN号】
进到“网络”→“聚合网口”→“绑定网口”:名称填“bond”,绑定模式填“主备”,勾选“eth1”“eth2”;
进到“网络”→“添加接口”:点击“添加存储接口”,勾选刚创建的“bond”,VLAN ID填“27”,IPv4地址填“192.168.100.12”,子网掩码填“255.255.255.0”。【按实际环境地址填写】
(四)配置阵列(添加LUN组→启动器→主机→主机组→网络→端口→端口组→主机组和端口组完成映射)
1.登录Estor后选“服务”,点击“LUN组”后,
进到“块服务”→“LUN组”→“LUN组”→“创建”:勾选“已创建LUN”,勾选“LUN001”“LUN002”(测试环境没有LUN,需自行创建,详见补充说明)
进到“块服务”→“主机组”→“启动器”→“iSCSI”→“创建”:复制黏贴CNA01的IQN,别名填“CNA01”
进入“块服务”→“主机组”→"主机"→":创建”:名称填“CNA01”,IP填“192.168.27.11”,选“iSCSI”,勾选“CNA01的IQN”
【完成CNA01的启动器和主机配置后,再添加CNA02的,别名填“CNA02”,IP填“192.168.100.12”】
进入“块服务”→“主机组”→“主机组”:名称填“HostGroup001”,勾选“CNA01”、“CNA02”
进入“网络”→“以太网络”:勾选“xxPO”,点击“修改”,名称填“PO”,角色选“数据”,数据协议选“iSCSI”,IP地址类型选“IPv4”,IP填“192.168.27.15”,子网掩码填“255.255.255.0”,端口类型选“以太网端口”,主端口选“xxPO(已连接)【可以创建PO逻辑端口,也可以按照视频中修改环境中有的PO】
进入“网络”→“逻辑端口”→“创建”:名称填‘nas’,角色选“数据”,协议选“NFS”、IP地址类型选“IPv4”,IP填“192.168.27.16”,子网掩码填“255.255.255.0”,网关填“192.168.27.254”,端口类型选“以太网端口”,主端口选“xxPO(已连接)”【添加用于对接NAS的逻辑端口】
进入“块服务”→“端口组”→“创建”:名称填“PortGroup01”,勾选“xxPO”
进入“块服务”→“LUN组”→“LUN组”→“映射”:勾选“LUNGroup01”,映射到选“主机组”“HostGroup001”,端口组选“PortGroup001”,主机LUN选“自动”
2.退回Estor后选“服务”,点击“文件系统”后,
进入“文件服务”→“文件系统”→“创建”:容量填“5”,NFS“开启”
进入“文件服务”→“共享”→“NFS共享”→“创建”:勾选“/nfs”,点击“更多”选“修改”,点击“高级”,权限级别选“读写”,权限控制选“no_all_squash”,root权限选“no_root_squash”
(五)对接NAS(添加存储资源、数据存储)
登录FC后,
选“存储”→“存储资源”→“添加存储资源”:类型填“NAS”,名称填“nas”,存储IP类型填“IPv4”,存储IP填“192.168.27.16”,勾选“关联主机”,点击“下一步”,勾选“site”“Cluster”“CNA01”“CNA02”,点击“下一步”,勾选“扫描存储设备”
选“存储”→“数据存储”→“添加数据存储”:勾选“类型为NAS存储”,点击“下一步”,名称填“nas”,勾选“site”“Cluster”【练习环境中配置了NFS,发放FA桌面时请使用NFS发放桌面,否则有可能导致发放桌面失败(考场提供有物理NAS发放桌面时使用物理NAS)】
(六)对接IPSAN(添加存储资源、虚拟化存储、裸设备映射数据存储)
选“存储”→“存储资源”→“添加存储资源”:类型填“IPSAN”,名称填“ipsan”,管理IP填“192.168.20.15”,存储IP1填“192.168.27.15”,勾选“关联主机”,勾选“site”“Cluster”【管理IP随便填,存储IP1不可以填错】
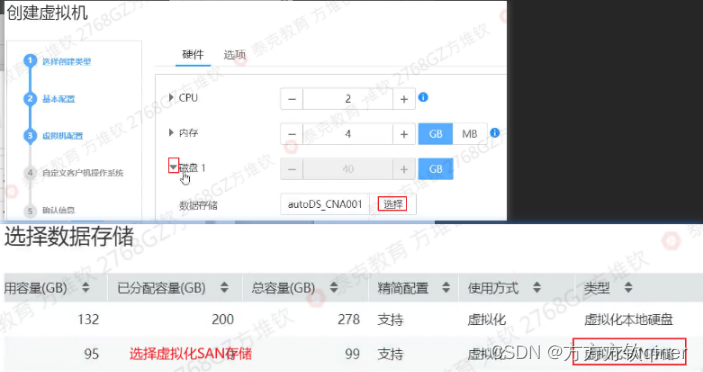
选“存储”→“数据存储”→“添加数据存储”:勾选“IP SAN存储 100G”,点击“下一步”,名称填“san”,使用方式选“虚拟化”,勾选“site”“Cluster”【100G必须当虚拟化使用】
选““存储”→数据存储”→“添加数据存储”:勾选“IP SAN存储 1G”,点击“下一步”,名称填“rdm”,使用方式选“裸设备映射”,勾选“site”“Cluster”
二、Window部分
(一)添加虚拟机属性规格
登录FC,选“资源池”→“配置”→“虚拟机属性规格”→“创建”:目标虚拟机操作系统类型选“WIndows”,虚拟机属性规格名称填“win-flavor”,点击“下一步”,计算机名称填“win10”,工作组填“WORKGROUP”,点击“下一步”,网卡设置的网卡数填“1”
【因为如下题目要求才有这一步】

(二)导入虚拟机(设密码,挂载Tools)
登录FC,选“资源池”→"Cluster"→“CNA01”→“创建虚拟机”:选“导入虚拟机”,勾选“从本地导入”,模板路径选“XX”,点击“下一步”,名称填“win10-temp”,选择计算资源选“Cluster”,点击“下一步”,勾选“stor”,点击“下一步”,配置模式选“精简”,取消“生成系统初始密码”,勾“创建完成后直接启动虚拟机”
(三)配置Windows虚拟机
登录win10-temp,“电脑”→“管理”→“本地用户和组”→“用户”→“Administrator”右键“设置密码”为XX,“属性”取消“账户已禁用”
登录FC,选“资源池”→“Cluster”→"CNA01"→“win10-temp”:选“更多操作”,选“Tools”选“挂载Tools”
登录win10-temp,“电脑”,“Setup”右键“以管理员身份运行”,点“Restart”
登录FC,选“资源池”→“Cluster”→"CNA01"→“win10-template”→“概要”:修改虚拟机名称填“win10-temp-new”
登录FC,选“资源池”→“Cluster”→"CNA01 "→“win10-temp-new”:选“模板”,选“转为模板”
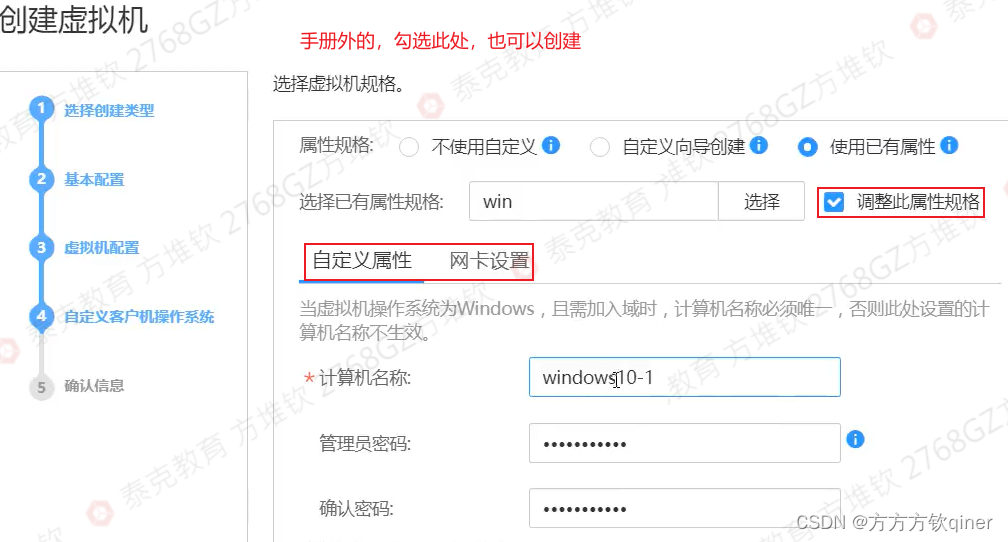
登录FC,选“资源池”→“虚拟机模板”→“win10-temp-new”→右键选“按模板部署虚拟机”:名称填“win10-01”, 选“磁盘1”,数据存储选“虚拟化SAN存储”,网卡1填“Manageaggr”,网卡类型“virtio”,点击“下一步”,网卡设置的网卡数填“1”,选择虚拟机属性规格勾选“win-flavor”,勾选“调整此属性规格”,计算机名称为“win10-01”(勾选“调整此属性规格”,IP填192.168.100.241,子网255.255.255.0,网关192.168.100.254,这里填写后,应该可以去掉登录win10-1手动配置),勾“创建完成后直接启动虚拟机”
登录FC,选“资源池”→“虚拟机模板”→“win10-temp”→“创建虚拟机”:名称填“win10-02”, 选“磁盘1”,数据存储选“虚拟化SAN存储”,网卡1填“FA”,网卡类型“virtio”,点击“下一步”,网卡设置的网卡数填“1”,选择虚拟机属性规格勾选“win-flavor”,勾选“调整此属性规格”,计算机名称为“win10-02”,IP填10.0.0.241,子网255.255.255.0,网关10.0.0.254,勾“创建完成后直接启动虚拟机”
【注意在发放Win10-1时,选择网卡为ManageDVS的Manageaggr端口组,发放Win10-2时需要选择网卡为IE_DVS的FA端口组】
登录FC,选“资源池”→“文件夹”→“安全组”→“添加安全组”:名称填“s1”,添加规则中协议填“ICMP”,类型填“子网”,IP地址10.0.0.0,子网掩码255.255.255.0,ICMP类型选“Any”
登录FC,选“资源池”→“Cluster”→“win10-1”→“网卡”→“配置”:选“更多”中“配置安全组”,开启安全组,安全组填“s1”
登录FC,选“资源池”→“Cluster”→“win10-2”→“网卡”→“配置”:选“更多”中“配置安全组”,开启安全组,安全组填“s1”
登录win10-1,IP填192.168.100.241和关闭防火墙,登录win10-2,IP地址配置10.0.0.241和关闭防火墙,结果为“仅win10-2ping通win10-1,反之不行”
(四)配置互斥(聚集)规则
登录FC,选“资源池”→“Cluster”→“集群资源控制”:选“计算资源调度配置”,开启计算资源调度
登录FC,选“资源池”→“Cluster”→“配置”→“DRS规则”→“规则组”:选“添加”,名称填“huchi”,类型选“互斥虚拟机”,勾选“Euleros-01”“Euleros-02”【手册出错,题目要求的是配置Euleros,不是win10,已修正,位置就不更改了】
(五)配置HA特性
登录FC,选“资源池”→“Cluster”→“集群资源控制”:选“HA配置”,开启
登录FC,选“资源池”→“Cluster”→“配置”→“配置”→“虚拟机替代项”:勾选“win10-1”,windows虚拟机蓝屏处理策略选“HA虚拟机”。勾选“win10-2”,windows虚拟机蓝屏处理策略选“重启虚拟机”
(六)绑定裸设备磁盘
登录FC,选“资源池”→“Cluster”→“CNA01”→“win10-2”→“配置”→“磁盘1/40GB”→“绑定磁盘”:选“创建并绑定磁盘”,数据存储选“rdm”,总线类型选“SCSI”
登录win10-2,“电脑”右键“管理”→“存储”→“磁盘管理”:磁盘1处右键选“新建简单卷”,双击打开“新加卷”,在“新加卷”中新建测试txt
登录FC,选“资源池”→“Cluster”→“CNA01”→“win10-2”→“快照”:快照名填snap01,取消“一致性快照”【不取消一致性快照,会报错虚拟机存在共享磁盘,不能进行该操作】
登录win10-2,在“新加卷”中删除测试txt
登录FC,选“资源池”→“Cluster”→“CNA01”→“win10-2”→“快照”:点击“恢复虚拟机”,结果测试txt没有恢复
【因为裸设备映射的磁盘不支持快照,所以恢复快照好被删除的文件不会恢复,属于正常】
三、EulerOS部分
(一)导入虚拟机:导入虚拟机→虚拟机挂载Tools→虚拟机转换为模板→根据模板发放虚拟机
登录FC,选“资源池”→"Cluster"→“CNA01”→“创建虚拟机”:选“导入虚拟机”,名称填“Euleros-template”,选择计算资源选“Cluster”,勾选“stor”,配置模式选“精简”,取消“生成系统初始密码”
登录FC,选“资源池”→“Cluster”→"CNA01"→“Euleros-template”:选“更多操作”,选“Tools”选“挂载Tools”
登录Euleros-template,输入root,密码xx,mkdir cdrom,mount /dev/sr0 /root/cdrom/,【ls /root/cdrom/查看】,cp /root/cdrom/vmtools-2.5.0.155.tar.bz2 ./,tar -xf vmtools-2.5.0.155.tar.bz2,【ls查看】,cd vmtools/,./install,等待tools安装完后reboot,重启后查看eth0为DHCP:cd /etc/sysconfig/network-scripts/,ls,cat ifcfg-eth0
登录FC,选“资源池”→“Cluster”→"CNA01"→“Euleros-template”→“概要”:修改虚拟机名称填“Fuleros-temp-new”
登录FC,选“资源池”→“Cluster”→“Euleros-temp-new”:选“模板”,选“转为模板”
登录FC,选“资源池”→“虚拟机模板”→“Euleros-temp-new”→→右键选“按模板部署虚拟机”: 名称填“Euleros-01”,选“磁盘1”,数据存储选“虚拟化SAN存储”,配置模式填“精简”,网卡1填“manageaggr”,选“自定义向导创建”,计算机名称填“Euleros-01”,密码xx,勾选“保存为计算机属性规格”,虚拟机属性规格名称填“linux”,IP填192.168.100.240,掩码255.255.255.0,网关192.168.100.254,勾“创建完成后直接启动虚拟机”【此处与win10相比,少了一步“添加虚拟机属性规格”,是因为这里使用另一种方式‘’自定义向导创建】
登录FC,选“资源池”→“虚拟机模板”→“Fuleros-temp-new”→→右键选“按模板部署虚拟机”:名称填“Euleros-02”, 选“磁盘1”,数据存储选“虚拟化SAN存储”,配置模式填“精简”,网卡1填“FA”,勾选“使用已有属性”,选择已有属性规格选“linux”,计算机名称填“Euleros-02”,密码xx,IP填10.0.0.240,掩码255.255.255.0,网关10.0.0.254,勾“创建完成后直接启动虚拟机”
【根据模板发放虚拟机,发放EulerOS-1网卡使用ManageDVS的Manageaggr端口组,EulerOS-2网卡使用IE_DVS的FA端口组】
登录Euleros-template,输入hostnamectl set-hostname Euleros01,exit
(二)配置网络
登录Euleros01,cd /etc/sysconfig/network-scripts/,vi ifcfg-eth0,BOOTPROTO=static,ONBOOT=yes,IPADDR=192.168.100.240,NETMASK=255.255.255.0,GATEWAY=192.168.100.254,systemctl restart network,ip a
登录Euleros02,nmcli connection modify eth0 ipv4.addresses 10.0.0.240/24 ipv4.gateway 10.0.0.254 \,nmcli con up eth0,ip a,ping 192.168.100.240通
(三)RDM配置
登录FC,选“资源池”→“Cluster”→“CNA02”→“Euleros-02”→“配置”→‘“磁盘1/40GB”→“绑定磁盘”:总线类型填“SCSI”,勾选“rdm”【SCSI支持指令透传,直通需要指令透传特性才能实现】
登录Euleros-02,输入lsblk看1G的sda,fdisk /dev/sda,n,默认敲回车,w【lsblk看到sda中的sda1】mkfs.ext4 /dev/sda1,mkdir -p disk,mount /dev/sda1 disk/,cd disk/,touch 1.txt【ls确认是否创建成功】
【若挂载裸设备磁盘后,主机无法识别,请重启虚拟机 】
(四)迁移虚拟机
登录FC,选“资源池”→“Cluster”→“创建虚拟机”:查看“选择数据存储”是勾选“nas”【创建空虚拟机要保证其磁盘使用的共享存储】
登录FC,选“资源池”→“Cluster”→“CNA01”→“Euleros-01”:右键“Euleros-01”选“迁移”,勾选“更改主机”,选择迁移目的主机勾选“site→Cluster→CNA02”

(五)备份
登录BCManager【http://192.168.100.21:8088】,选“受保护环境”:点击“+”,VRM IP填192.168.100.20,用户名填“vdisysman”,密码填“VdiEnginE@234”,证书选“自动匹配”
(六)配置存储
登录BCManager,选“备份存储”→“存储单元”→“修改存储单元”:名称填“Storage_当天日期”,路径选“192.168.100.224/home/share”
登录BCManager,选“备份存储”→“存储池”→“创建存储池”:名称填“Pool_当天日期”,增加存储单元选“Storage_当天日期”
登录BCManager,选“备份存储”→“存储库”→“创建存储库”:名称填“Repository_当天日期”,容量填“50”,存储池选“Pool_当天日期”【存储库是实际备份虚拟机的】
(七)创建备份任务
登录BCManager,选“备份”→“保护集”→“创建保护集”:名称填“Protected_当天日期”,将“可选对象的Euleros-02”转移到“已选对象”【保护集是指需要备份的对象,对象可以是主机,集群,存储等】
登录BCManager,选“备份”→“备份策略”→“创建备份策略”:名称填“Policy_当天日期”,按天执行选“星期X”,执行时间点选“23:00”
登录BCManager,选“备份”→“备份计划”→“创建”:名称填“Plan_当天日期”,保护集选“Protected_当天日期”,备份策略选“Policy_当天日期”,存储库选“Repository_当天日期”【此处将备份所创建的东西都使用上了,可以在这里复核之前是否有漏做】
补充说明:
配置网络视频和手册不一致,视频更为复杂,手册应该是描述少了;20221019_1扩容视频中间;
做实验中途有事,可以设置超时时间长点;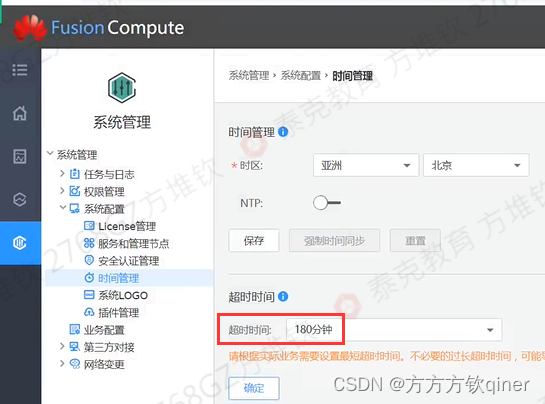
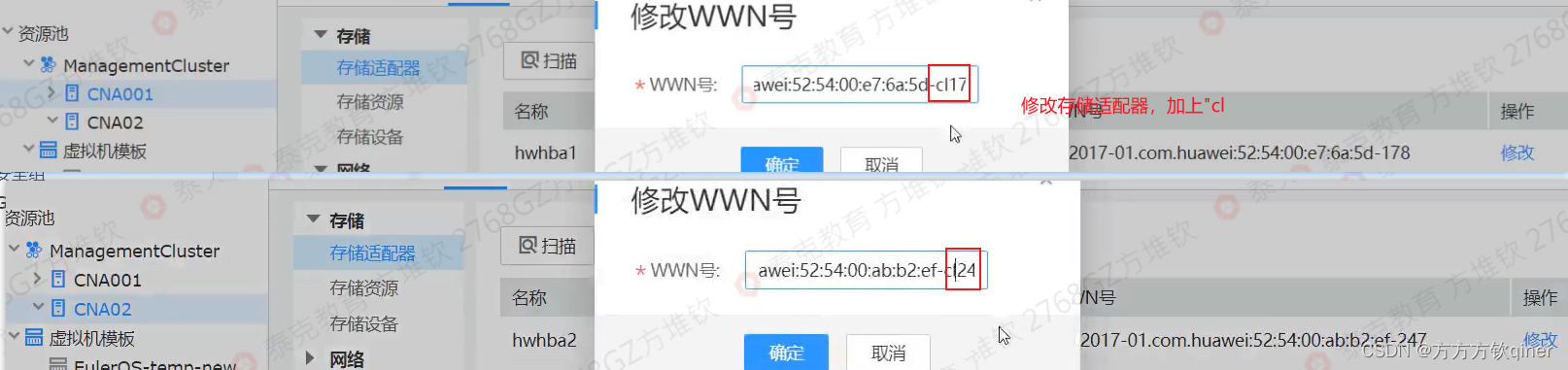
需要手动修改存储适配器,随意给两个字母区分,如下图,修改的必要性:防止冲突,考场中采用的是虚拟化部署,导致所有CNA的IQN号是一样,又因为考试中是有多套环境,而连接的物理阵列只有一套,如果多个IQN是一样的,那么先挂载上物理阵列的会成功,其他无法识别。
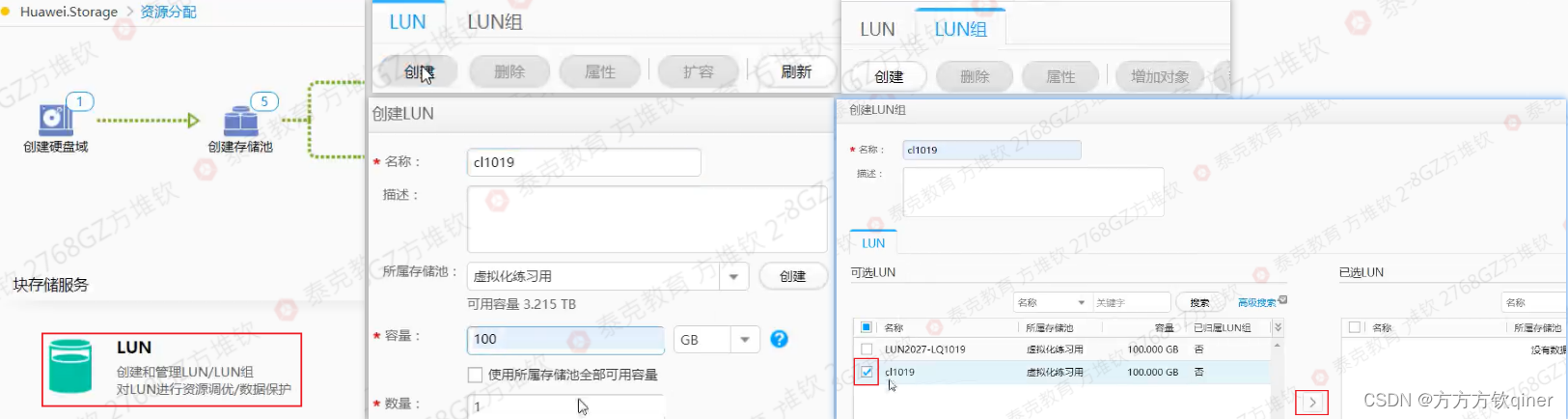
测试环境没有LUN,需自行创建,需要登录物理阵列管理平台进行创建:
来自20220401的记录
1.FC
1.1. Euler
1.1.1.安装CNA
1.截图磁盘、hostname、时区、地址
2. FC中添加CNA,截图地址
3. CNA02管理口添加到原始dvs里去
1.1.2.创建共享目录
1.CNA中添加存储用的捆绑接口,加存储接口(vlan与上联交换机配置相关)(与estor同一段)
2. estor创建lun、lun组、启动器、主机、主机组、端口组,在lun组中把主机组和端口组关联
3. CNA中存储项目扫描san,添加存储介质
1.1.3. 创建空虚拟机,迁移
1.创建空虚拟机,磁盘选择精简,然后点击迁移,然后截图
1.1.4.修改euler模板名称,安装tools
1.mount /dev / sre / mnt
2.cp /mnt/ vmxxxxx.tar /dev
3.cd /dev
4.tar -xvf vmxxxxx.tarv. cd /vmtools
5. ./install
6.passwd换行敲新密码Huawei@123
7.重启后,截图tool运行的界面
1.1.5.创建IE-DVS
1.捆绑CNA01/02的eth6 7
2.根据上联端口的配置,选择端口组的vlan
1.1.6.新模板创建2台euler
1.EulerOS1选择mgmt端口组,EulerOS2选择FA端口组
2.配置ip地址,注意网关、device对应的端口号
3.EulerOS1 ping EulerOS2
4.设置安全组,1ping2,设置192的段,2ping1设置10的段
5.关机应用安全组
6.在ping截图
1.1.7.添加直通存储
1.直通存储需要设置成iscsi
2.fdisk /dev/sre
换行输入n回车回车回车,最后选择w保存配置
3.mkfs.ext4 /dev/ sr1
4. mkdir /root/disk
5. mount /dev / sr1 / root/ disk
6. cd /root/disk
7. touch 1.txt
1.1.8. ebackup备份
1.对接FC,在FC中创建接口对接用户ebackup
2.创建存储单元nfs地址
3.创建存储池
4.创建存储库
5.创建保护集(选择FC里的)
6.创建备份策略(确定时间)
7.创建备份计划
1.2. windows
1.2.1.安装CAN
1.截图磁盘、hostname、时区、地址
2.FC中添加CNA,截图地址
1.2.2.创建共享目录
1.CNA中添加存储用的捆绑接口,加存储接口(vlan与上联交换机配置相关)(与estor同一段)
2.estor创建lun、lun组、启动器、主机、主机组、端口组,在lun组中把主机组和端口组关联
3.CNA中存储项目扫描san,,添加存储介质
1.2.3. 创建空虚拟机,迁移
1.创建空虚拟机,磁盘选择精简,然后点击迁移,然后截图
1.2.4. 创建IE-DVS
1.捆绑CNA01/02的eth6 7,
2.根据上联端口的配置,选择端口组的vlan
1.2.5. win10改模板名称、工作组、ping测试、聚集虚拟机模式
1.启动administrator,修改密码Huawei@123,这两步都要截图
2.安装tools,重启
3.创建win10-1win10-2,用资源池虚拟机规格属性配置地址、修改密码、工作组,创建虚拟机时,分别选择mgmt的端口组、FA端口组
4.在集群设置中,使用DRS规则、规则组win10-1 -2两台设置聚集虚拟机
5.设置安全组,1ping2,设置192的段,2ping1设置10的段
6.关机应用安全组
7.在ping截图
1.2.6. win10-2添加共享存储,快照,删除直通盘文件
1.在管理->磁盘选项中生成盘符
2.在新盘符创建文件,FC中打快照
3.删除文件、恢复快照,截图文件不会恢复到直通盘里
1.2.7.集群设置虚拟机替代项
1.win10-1蓝屏HA,在原来的主机中恢复
2.win10-2蓝屏重启,在原来的主机中恢复
四、考生建议
- 安装CNA2系统的时候要格外注意键盘在VNC界面里的大小写状态,我大小写混淆了导致密码配置有问题,装好后试了很久登陆不进去。建议在安装界面,配置主机名的时候,测试一下键盘的大小写状态,确认好再去配密码。
- 物理存储的地址信息在资料卡的最下面,不在表格里面,一定要把所有资料看完整,每个文件都看到最下面最后一行为止。
- 物理存储只给了:管理地址XXX,业务地址XXX,访问web页面要记得自己在管理地址前加https,在后面加端口号8088。存储配置界面参考老版本实验手册。考试时候只需要创建主机、启动器、主机组,不需要创建端口组也不需要配端口,直接添加映射试图。然后在FC里面用“业务地址”添加存储就可以直接扫描到。
- 做子题目的时候注意需求,所有牵扯到集群特性的,比如迁移、互斥、资源调度、HA这些的,对应的虚拟机一定注意创建的时候选择共享存储,我因为光顾着点下一步,不小心选了本地存储,后面通过迁移存储搞定了,但是浪费了时间。
- 要记忆欧拉系统修改主机名、修改root密码的命令,要会修改网卡配置,考试都会用到。
- 两台虚拟机不同DVS互通的题目,我其中一台不明原因无法正确配置IP地址,折腾了十分钟之后放弃,重新发放了一台后一切正常,考试的时候建议果断一些,搞不懂的问题不要纠结太久,有时候排错比推倒重来还浪费时间。
- 给欧拉2添加裸设备存储,考试环境用的模拟器和咱们实验环境完全一致,正常配就可以。要记忆欧拉系统查看分区、创建分区、创建文件系统、挂载分区、新建文件的命令,题目没有明确要求要新建文件,但是我个人觉得好一些。时间不紧张的话可以修改fstab做一下永久挂载,题目没有明确要求,但是希望给点步骤分吧。
- 注意的点就是你要确定你要扩容CNA2这台主机的密码的一个大小写情况,方法的话就是在设置这台主机的主机名那里可以确定。扩容部分我做的就是对接100G的物理存储(共享存储)以及estor,这里要说的是,物理存储的lun和端口组是不用我们去创建的,而estor的话就按照手册里面的过程进行创建就行,最后就是创建一台空虚拟机进行热迁移(磁盘使用共享存储),要提前将CNA2添加上行链路。
- FC部分我抽到的是Euler这一部分,这里需要注意的就是先把这一部分的题目审完,因为后面可能会要求做DRS,所以虚拟机要使用共享存储,如果已经用本地磁盘做了前面的小题,那么可以使用林哥说的磁盘迁移进行操作;对所给的Euler模板修改后转为新的模板,然后发放虚拟机,题目所要求的主机名、root用户的密码以及虚拟机的IP地址等配置可以在发放虚拟机的过程中进行自定义,就不用登录到虚拟机里面改;后面的ebackup部分需要注意的一点就是使用NFS的地址路径格式,根据考场给我们的地址信息表(pdf文件)进行填写即可。
EulerOS是基于开源技术的开放的企业级Linux操作系统软件,具备高安全性、高可扩展性、高性能等技术特性,能够满足客户IT基础设施和云计算服务等多业务场景需求。 ↩︎ ↩︎