长春市网站制作可以做网站的编程有什么软件
项目中遇到多个模块需要打印Controller请求日志,在每个模块里面加AOP并且配置单独的切面笔者认为代码冗余,于是乎就打算把AOP日志打印抽离成一个公共模块,谁想用就引入Maven坐标就行。
定义公共AOP模块 并编写AOP工具
AOP模块pom.xml如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns="http://maven.apache.org/POM/4.0.0"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><parent>这里根据自己需要引入 公共AOP父模块</parent><modelVersion>4.0.0</modelVersion><artifactId>xx-common-aop</artifactId><description>xx-common-aop切面</description><dependencies><!-- Lombok --><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><!-- SLF4J --><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-bootstrap</artifactId></dependency><!-- FastJSON --><dependency><groupId>com.alibaba.fastjson2</groupId><artifactId>fastjson2</artifactId></dependency><!-- Hutool --><dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId></dependency><dependency><groupId>org.aspectj</groupId><artifactId>aspectjweaver</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency></dependencies></project>AOP核心代码
import cn.hutool.extra.servlet.ServletUtil;
import com.alibaba.fastjson2.JSON;
import lombok.extern.slf4j.Slf4j;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.Signature;
import org.aspectj.lang.annotation.*;
import org.aspectj.lang.reflect.MethodSignature;
import org.springframework.stereotype.Component;
import org.springframework.web.context.request.RequestContextHolder;
import org.springframework.web.context.request.ServletRequestAttributes;import javax.servlet.http.HttpServletRequest;
import java.util.*;/*** 类名称: ServiceLogAop * 类描述: api入参, 出参打印*/
@Aspect
@Component
@Slf4j
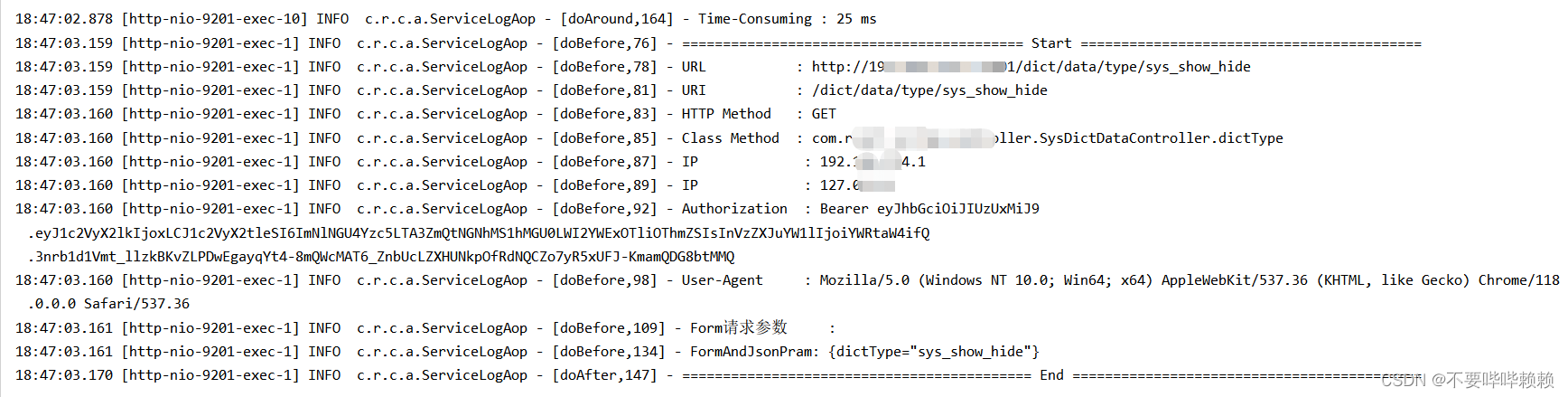
public class ServiceLogAop {/*** 换行符*/private static final String LINE_SEPARATOR = System.lineSeparator();/*** 以自定义 @ServiceLogAop 注解为切点*/@Pointcut("execution(public * com.*.*.controller.*.*(..))")public void webLog() {}//基本类型定义,用于判断请求参数的类型private static List typeList = new ArrayList();private static String[] types = {"java.lang.Integer", "java.lang.Double","java.lang.Float", "java.lang.Long", "java.lang.Short","java.lang.Byte", "java.lang.Boolean", "java.lang.Char","java.lang.String", "int", "double", "long", "short", "byte","boolean", "char", "float"};static {for (int i = 0; i < types.length; i++) {typeList.add(types[i]);}}/*** 在切点之前织入** @param joinPoint* @throws Throwable*/@Before("webLog()")public void doBefore(JoinPoint joinPoint) {// 开始打印请求日志ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();HttpServletRequest request = attributes.getRequest();// 获取 @WebLog 注解的描述信息// 打印请求相关参数log.info("========================================== Start ==========================================");// 打印请求 urllog.info("URL : {}", request.getRequestURL().toString());//uriString uri = request.getRequestURI();log.info("URI : {}", uri);// 打印 Http methodlog.info("HTTP Method : {}", request.getMethod());// 打印调用 controller 的全路径以及执行方法log.info("Class Method : {}.{}", joinPoint.getSignature().getDeclaringTypeName(), joinPoint.getSignature().getName());//IPlog.info("IP : {}", request.getRemoteAddr());// 打印请求的 IPlog.info("IP : {}", ServletUtil.getClientIP(request));//TokenString authorization = request.getHeader("Authorization");log.info("Authorization : {}", authorization);
/* //cokieString Cookie = request.getHeader("Cookie");log.info("Cookie : {}", Cookie);*///User-AgentString userAgent = request.getHeader("User-Agent");log.info("User-Agent : {}", userAgent);StringBuffer requestParam = new StringBuffer("");//参数Enumeration<String> paramter = request.getParameterNames();while (paramter.hasMoreElements()) {String str = (String) paramter.nextElement();String strValue = request.getParameter(str);requestParam.append(str + "=" + strValue + "&");}log.info("Form请求参数 : {}", requestParam.toString());// 打印请求入参// log.info("Json请求参数 : {}", JSONUtil.toJsonStr(joinPoint.getArgs()));Signature signature = joinPoint.getSignature();MethodSignature methodSignature = (MethodSignature) signature;// 通过这获取到方法的所有参数名称的字符串数组String[] parameterNames = methodSignature.getParameterNames();//获取到所有参数的NAMEObject[] args = joinPoint.getArgs(); //获取到所有参数的VALUEStringBuilder sb = new StringBuilder();Map paramMap = new HashMap();if (parameterNames != null && parameterNames.length > 0 && args != null && args.length > 0) {for (int i = 0; i < parameterNames.length; i++) {//考虑入参要么为基础类型参数,要么为对象类型。以下方法都适合解析出来if (typeList.contains(args[i].getClass().getTypeName())) {//基本数据类型paramMap.put(parameterNames[i], JSON.toJSONString(args[i]));} else {//实体类paramMap = JSON.parseObject(JSON.toJSONString(args[i]));}}}log.info("FormAndJsonPram: " + paramMap.toString());}/*** 在切点之后织入** @throws Throwable*/@After("webLog()")public void doAfter() {// 接口结束后换行,方便分割查看log.info("=========================================== End ===========================================" + LINE_SEPARATOR);}/*** 环绕** @param proceedingJoinPoint* @return* @throws Throwable*/@Around("webLog()")public Object doAround(ProceedingJoinPoint proceedingJoinPoint) throws Throwable {long startTime = System.currentTimeMillis();Object result = proceedingJoinPoint.proceed();// 打印出参// log.info("Response Args : {}", JSONUtil.toJsonStr(result));// 执行耗时log.info("Time-Consuming : {} ms", System.currentTimeMillis() - startTime);return result;}}@Pointcut(“execution(public * com.ruoyi..controller..*(…))”) 作为AOP切入口
此切入口必须为静态常量 不能为动态参数 所以说从yml读取切入点是干不成。
但 @Pointcut 可以同时配置多个参数 这个就可以解决多个不同路径下面的Controller都能被切入进来。
@Pointcut("execution(* xx.xx.xxx.xx.*.save*(..))"+ "||execution(* xx.xx.xx.*.delete*(..))"+ "||execution(* xx.xx.xx..*.update*(..))")
子模块
-
使用需要引入公共AOP模块maven
-
创建图片中目录文件 并引入公共模块定义好的ServiceLogAop ( 这里也可以通过 @Bean方式把ServiceLogAop 注册进来 )

-
效果