做汽车配件的都在那个网站做呀网站开发专业就业好不好
目录
- 引言
- 一,string类对象的常见构造
- 二,string类对象的容量操作
- 三,string类对象的访问及遍历操作
- 四,string类对象的修改操作
- 五,string类非成员函数
- 六,整形与字符串的转换
引言
string 就是我们常说的"串",它是一种字符数组,只不过这个数组具备扩容,增删查改等功能。string类在我们日常生活中是十分常用的,并且在笔试,面试中也经常出现,它是学习C++的不可缺少的一部分。
string类大概有120个函数接口,注意下面只讲解最常用的接口,想要了解更多,前往https://legacy.cplusplus.com/reference/string/string/网站里浏览。
一,string类对象的常见构造
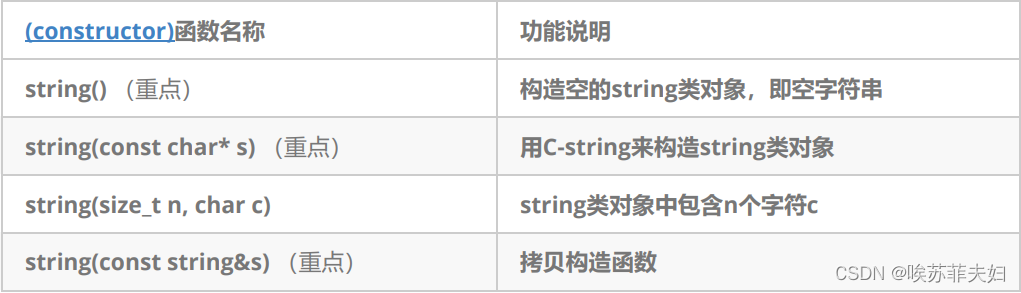
代码演示:
void test_string1()
{string s1;//无参默认构造string s2("hello world");//用字符串构造//从str中的pos下标位置,拷贝len个字符string s4(s2, 3, 5);//不传第三个参数,默认拷贝到结尾,缺省参数npos是整型最大值string s5(s2, 3);string s3(s2);//拷贝构造
}
二,string类对象的容量操作
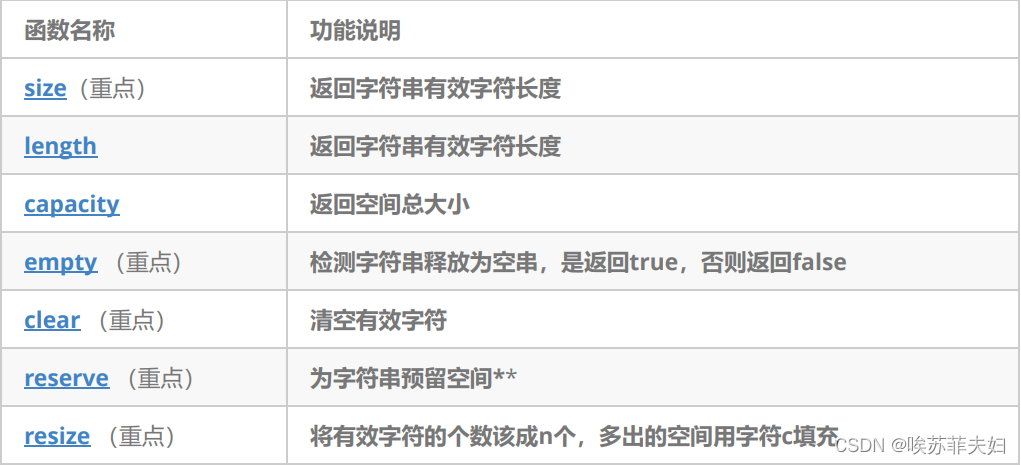
代码演示1:
// size/clear/resize
void Test_string2()
{// 注意:string类对象支持直接用cin和cout进行输入和输出string s("hello, world!!!");cout << s.size() << endl;//计算字符个数,不算\0cout << s.length() << endl;cout << s.capacity() << endl;cout << s << endl;// 将s中的字符串清空,注意清空时只是将size清0,不改变底层空间的大小s.clear();cout << s.size() << endl;cout << s.capacity() << endl;// 将s中有效字符个数增加到10个,多出位置用'a'进行填充//当传的值大于size时,此时会影响capacity+size,两个都会增加// “aaaaaaaaaa”s.resize(10, 'a');cout << s.size() << endl;cout << s.capacity() << endl;// 将s中有效字符个数增加到15个,多出位置用缺省值'\0'进行填充// "aaaaaaaaaa\0\0\0\0\0"// 注意此时s中有效字符个数已经增加到15个s.resize(15);cout << s.size() << endl;cout << s.capacity() << endl;cout << s << endl;// 将s中有效字符个数缩小到5个s.resize(5);cout << s.size() << endl;cout << s.capacity() << endl;cout << s << endl;
}
代码演示1:
//测试reserve
void test_string3()
{string s;//一般用在知道需要多少空间,提前开好s.reserve(100);string s1("111111111");cout << s1.capacity() << endl;//15//扩容//reserve只影响capacity,不影响size,即不改变里面的数据s1.reserve(100);cout << s1.capacity() << endl;//111//缩容//传的值比当前的capacity小时,// vs一般不缩容,g++会缩s1.reserve(10);cout << s1.capacity() << endl;//15
}
注意:
- size()与length()方法底层实现原理完全相同,引入size()的原因是为了与其他容器的接口保持一致,一般情况下基本都是用size()。
- clear()只是将string中有效字符清空,使size = 0,不改变底层空间大小。
- resize(size_t n) 与 resize(size_t n, char c)都是将字符串中有效字符个数改变到n个,不同的是当字符个数增多时:resize(size_t n)用0来填充多出的元素空间,resize(size_t n, char c)用字符c来填充多出的元素空间。注意:resize在改变元素个数时,如果是将元素个数增多,可能会改变底层容量的大小,如果是将元素个数减少,底层空间总大小不变。
- reserve(size_t res_arg=0):为string预留空间,不改变有效元素个数,当reserve的参数小于string的底层空间总大小时,reserver不会改变容量大小。
三,string类对象的访问及遍历操作
string类对象的访问及遍历有三种方式:
1. 迭代器:begin()+end()
2. for+[]
3. 范围for
注意:string遍历时使用最多的还是for+下标 或者 范围for(C++11后才支持)。
begin()+end()大多数使用在需要使用STL提供的算法操作string时,比如:采用reverse逆置string,使用sort按字典序排序(按ASCII码值排序)。
代码演示:
void Teststring4()
{string s("hello Bit");// 3种遍历方式:// 需要注意的以下三种方式除了遍历string对象,还可以遍历是修改string中的字符,// 另外以下三种方式对于string而言,第一种使用最多// 1. for+operator[]for (size_t i = 0; i < s.size(); ++i)cout << s[i] << endl;// 2.迭代器string::iterator it = s.begin();while (it != s.end()){cout << *it << endl;++it;}// string::reverse_iterator rit = s.rbegin();// C++11之后,直接使用auto定义迭代器,让编译器推到迭代器的类型auto rit = s.rbegin();while (rit != s.rend()){cout << *rit << endl;}// 3.范围for//自动取出s中的数据赋给ch,自动判断结束,自动++。//其实底层就是迭代器。for (auto ch : s){cout << ch << endl;}
}
使用sort按字典序排序(按ASCII码值排序):
void test_string5()
{string s1("hello world");cout << s1 << endl;//按字典序排序(按ASCII码值排序)//用排序函数sort [first last)左闭右开,last传的不是有效数据//sort(s1.begin(), s1.end());//第一个和最后一个不参与排序//sort(++s1.begin(), --s1.end());//前5个排序 [0,5)sort(s1.begin(), s1.begin() + 5);cout << s1 << endl;
}
四,string类对象的修改操作
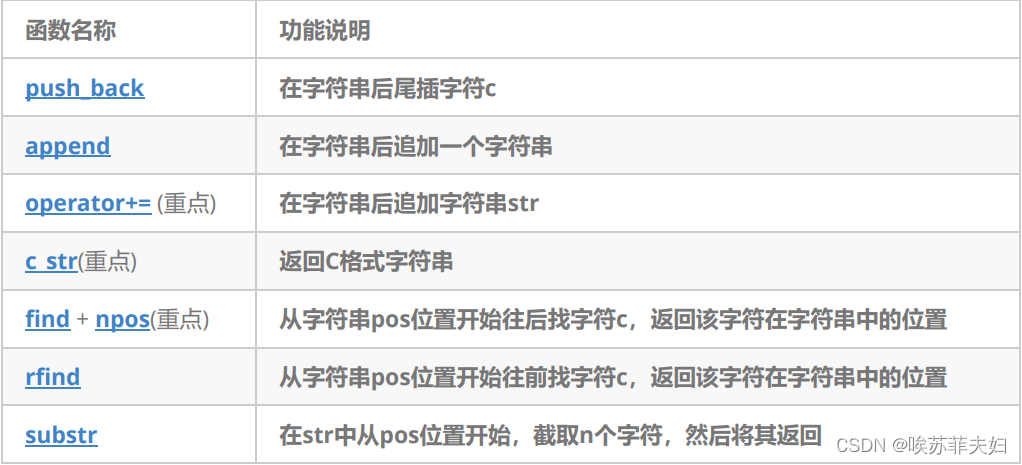
- 插入(拼接)方式:push_back append operator+=
- 正向和反向查找:find() + rfind()
- 截取子串:substr()
- 删除:erase
代码演示1:
void test_string6()
{string s1("hello world");cout << s1 << endl;s1.push_back('x');//一个字符一个字符尾插cout << s1 << endl;s1.append(" yyyyyyy!!");//尾插一个字符串cout << s1 << endl;string s2("22222");//直接尾插s1 += 'aaa';s1 += 'd';s1 += s2;cout << s1 << endl;
}
代码演示2:
void test_string7()
{// 获取file的后缀string file("string.cpp");//从后往前找'.'size_t pos = file.rfind('.');string suffix(file.substr(pos, file.size() - pos));cout << suffix << endl;// npos是string里面的一个静态成员变量// static const size_t npos = -1;// 取出url中的域名string url("http://www.cplusplus.com/reference/string/string/find/");cout << url << endl;size_t start = url.find("://");if (start == string::npos){cout << "invalid url" << endl;return;}start += 3;size_t finish = url.find('/', start);string address = url.substr(start, finish - start);cout << address << endl;// 删除url的协议前缀pos = url.find("://");url.erase(0, pos + 3);cout << url << endl;
}
注意:
- 在string尾部追加字符时,s.push_back( c ) / s.append(1, c) / s += 'c’三种的实现方式差不多,一般情况下string类的+=操作用的比较多,+=操作不仅可以连接单个字符,还可以连接字符串。
- 对string操作时,如果能够大概预估到放多少字符,可以先通过reserve把空间预留好。
五,string类非成员函数

代码演示1:
void test_string8()
{string s1 = "hello";string s2 = "world";string ret1 = s1 + s2;cout << ret1 << endl;string ret2 = s1 + "xxxxx";cout << ret2 << endl;string ret3 = "xxxxx" + s1;cout << ret3 << endl;//按字典序比较cout << (s1 < s2) << endl;
}
代码演示2:
int main()
{string str;string str2;//如何停止输入?//ctrl+c//ctrl+z+空格// while (cin >> str2)// {// cout << str2 << endl;// }//cin 遇到空格或者换行会停止提取//cin >> str;//获取一行包含空格的字符串getline(cin, str);int pos = str.rfind(' ');cout << str.size() - (pos + 1) << endl;return 0;
}
六,整形与字符串的转换
int main()
{int x = 0, y = 0;cin >> x >> y;//to_string:整形转字符串string str = to_string(x + y);cout << str << endl;//stoi:字符串转整形int aa = stoi(str);cout << aa << endl;return 0;
}