网站建设公司有哪些重要职务中国八冶建设集团网站
基于ChatGPT聊天的零样本信息提取
- 摘要
- 介绍
- ChatIE
- 用于零样本IE的多轮 QA
- 实验
- 总结

摘要
零样本信息提取(IE)旨在从未注释的文本中构建IE系统。由于很少涉及人类干预,因此具有挑战性。
零样本IE减少了数据标记所需的时间和工作量。最近对大型语言模型(LLMs,GFI-3,ChatGPT)的研究在零样本设置下显示出了良好的性能,从而激励我们研究基于提示的方法。
在这项工作中,我们询问是否可以通过直接提示LLM来构建强IE模型。
具体来说,我们将零样本IE任务转换为多轮问题解答问题,使用两阶段框架(ChatIE)。借助ChatGPT的强大功能,我们在三个IE任务上对我们的框架进行了广泛的评估:实体关系三重提取、命名实体识别和事件提取。
在两种语言的六个数据集上的经验结果表明,ChatIE在几种数据集上取得了令人印象深刻的性能,甚至超过了一些完整的模型。
介绍
信息提取旨在将非结构化文本中的结构化信息提取为结构化数据格式,包括实体关系提取(RE)、命名实体识别(NER)、事件提取(EE)等任务。这是自然语言处理中一项有趣的重要任务。处理大量的标签数据总是非常繁忙、劳动密集且耗时。
最近的工作在大规模预训练大语言模型上,例如GPT-3。
InstructGPT和ChatGPT表明,LLM即使不调整参数,仅使用少数示例作为说明,也能很好地执行各种下游任务。因此,这是一个时间问题:LLM提示在同一框架下执行零样本IE任务是否可行。这也是一个挑战,因为包含多个相关元素的结构化数据很容易通过一次预测来提取,尤其是对于像RE这样的复杂任务。以前的工作将这些复杂任务分解为不同的部分,并训练几个模块来解决每个部分。
基于这些线索,在本文中,我们转向ChatGPT,并假设ChatGPT天生具有在交互模式下存放统一正确零样本IE模型的能力。
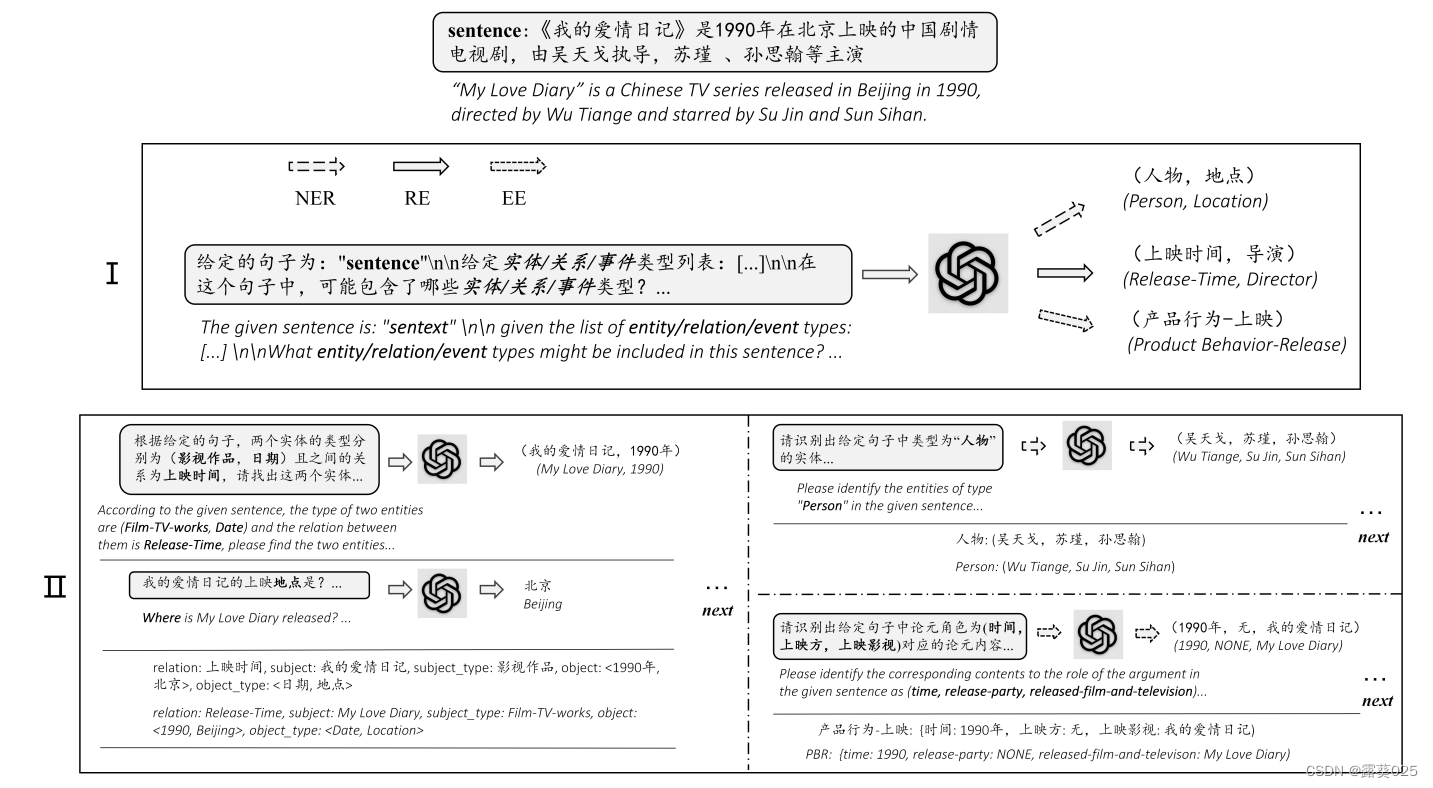
更具体地说,我们提出了ChatIE,将零样本任务转化为一个多回合问题,并使用两阶段框架回答问题。
- 在第一阶段,我们的目的是找出一个句子中可能存在的相应元素类型。
- 在第二阶段,我们对来自阶段1的每个元素类型进行链式信息提取。
每个阶段都通过一个多回合的QA过程来实现。在每一轮,我们都会根据设计的模板和之前提取的信息构建提示,以询问ChatGPT。最后,我们将每个转弯的结果组成结构化数据。我们对IE、NER和EE进行了广泛的实验任务,包括两种语言的六个数据集:英语和汉语。
实验结果表明,当不使用ChatIE的普通ChatGPT无法用原始任务指令解决IE时,当IE任务分解为多个更简单、更容易的子任务时,我们提出的在ChatGPT上实例化的两阶段框架成功了。令人惊讶的是,ChatIE在几个数据集上取得了令人印象深刻的性能,甚至超过了一些全镜头模型。
ChatIE
用于零样本IE的多轮 QA
将IE框架分解成两个阶段,每个阶段都包含几轮QA,参考与ChatGPT的对话。
在第一阶段,我们的目标是在三个任务中分别找出句子中存在的实体、关系或事件的类型。这样,我们过滤掉不存在的元素类型,以减少搜索空间和假设的复杂性,有助于提取信息。
在第二阶段,我们在第一阶段提取的元素类型以及相应的任务特定方案的基础上进一步提取相关信息。
第一阶段:对于这个例子而言,这一步仅包含了一轮QA。为找到在句子中呈现的元素类型,我们首先利用任务特定的 TypeQues模板和元素类型列表 来构建问题。然后我们将问题和句子组合到ChatGPT中。为了便于提取答案,我们要求系统 以列表形式回复 。如果这些内容不包含任何元素类型,系统将生成一个带有NONE Token的响应。
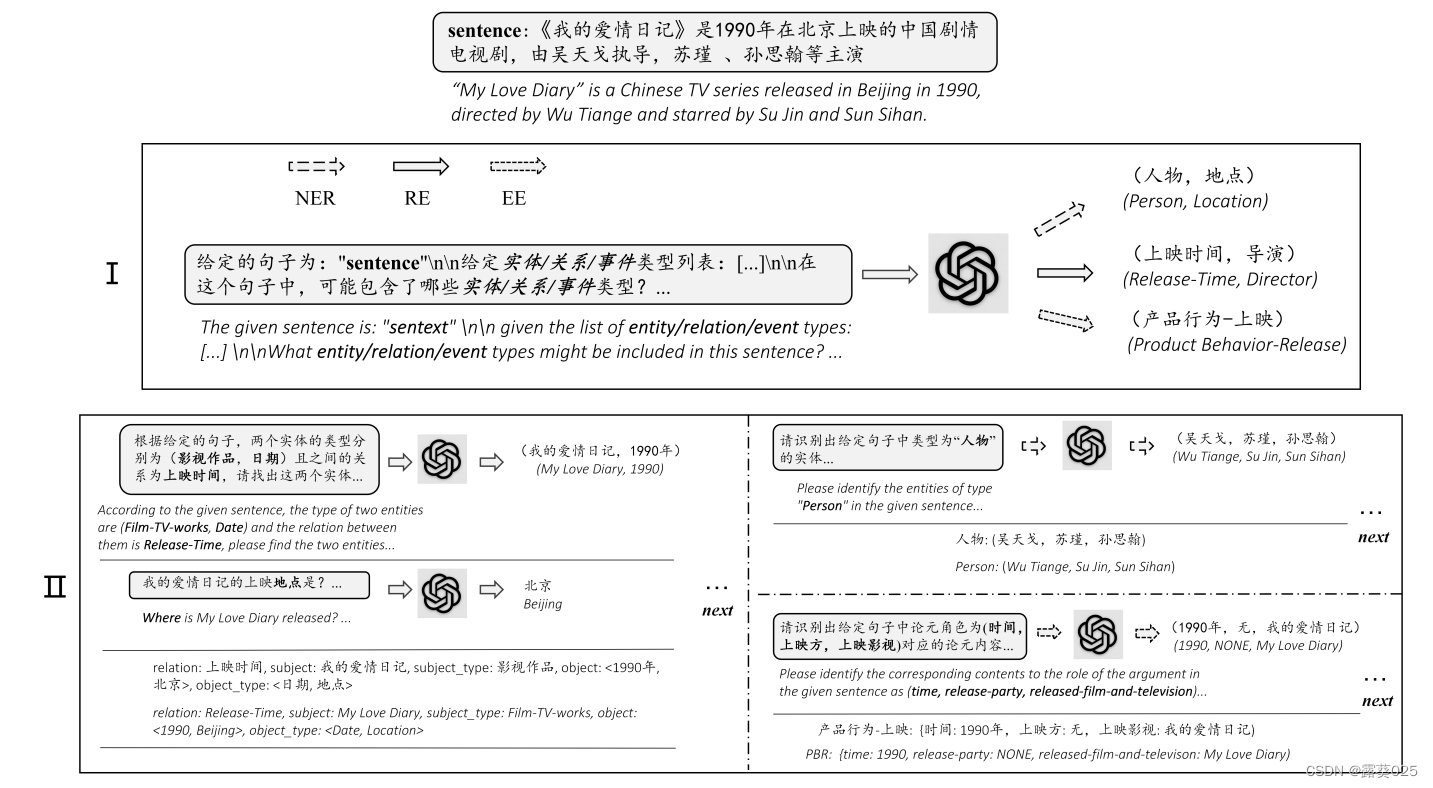
第二阶段:该阶段通常包括多个QA轮次。在那之前,我们根据任务的方案设计了一系列特定的元素类型 ChainExtractionTemplate。ChainExtractionTemplates定义了一个问题链模板,链的长度通常为为1。但对于复杂的方案,如实体关系三重提取中的复数二元值提取,链的长度大于1。在这一点上,一个元素的提取可能依赖于另一个先前的元素,因此我们称之为链式模板(chained template)。
我们按照先前提取的元素类型的顺序以及ChainExtractionTemplates的理论执行多回合QA。为了生成问题,我们需要检索具有元素类型的模板,并在必要时填充相应的槽。然后我们访问ChatGPT并获得响应。最后,我们根据每一轮提取的元素组成结构化信息。同样,为了便于答案提取,我们要求系统以表格形式回复。如果没有提取任何内容,系统将生成一个带有NONE的令牌响应。
实验
略
总结
这是知识抽取和语言模型的结合,重点在于提出的基于ChatGPT的多轮QA框架——ChatIE,用于零样本信息提取。
ChatIE将每个回合的结果合成最终的结构化结果。