网站返回500错误页面建设银行粤通卡网站
添加测试接口
在Spring Boot Demo项目里实现一个简单的用户管理系统的后端功能。具体需求如下:
-
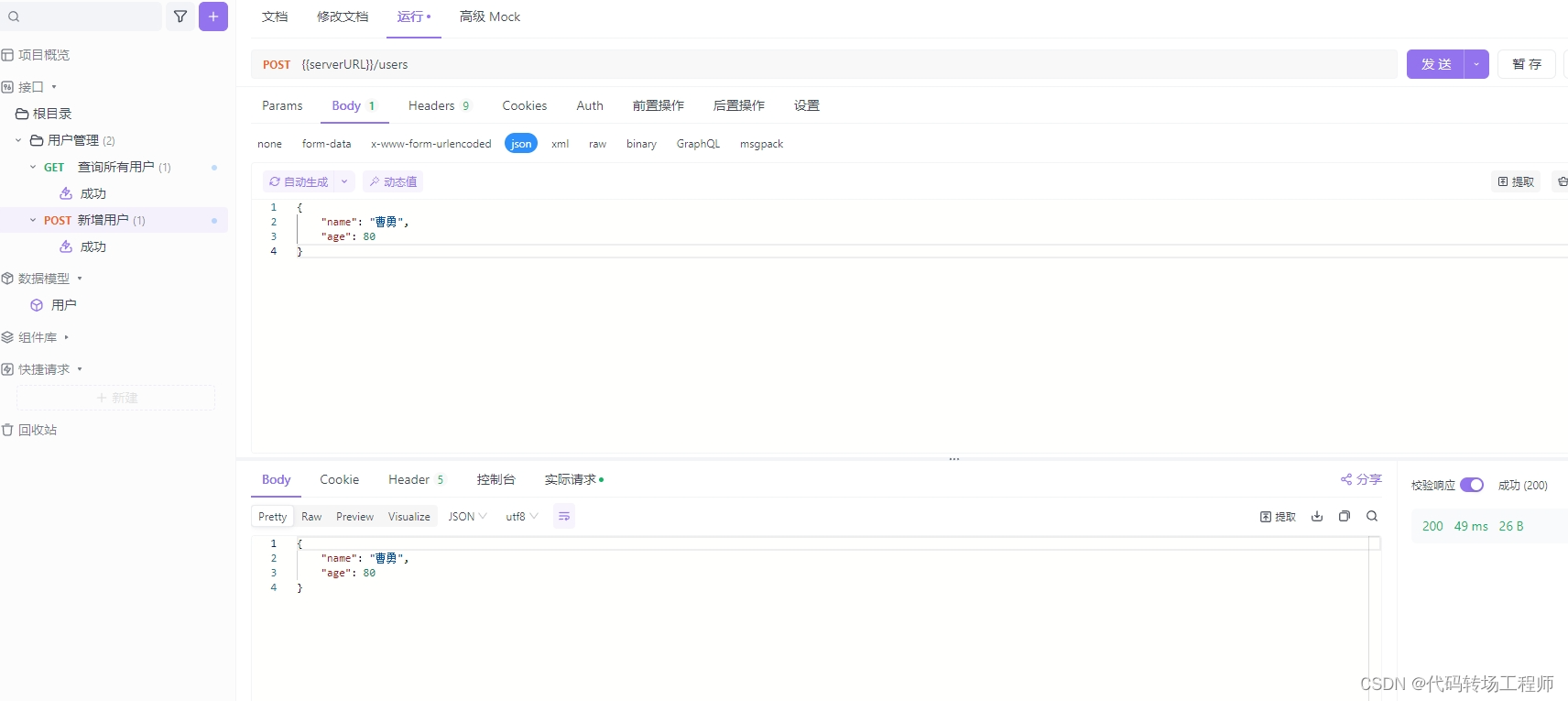
实现了一个RESTful API,提供了以下两个接口 :
- POST请求
/users:用于创建新的用户。 - GET请求
/users:用于获取所有用户的列表。
- POST请求
-
创建新用户功能:
- 用户可以通过向
/users发送 POST 请求来创建新用户。 - 新用户的信息通过请求体以 JSON 格式提供,包括用户的姓名和年龄。
- 用户可以通过向
-
获取所有用户列表功能:
- 用户可以通过向
/users发送 GET 请求来获取所有已创建用户的列表。 - 服务器将返回一个包含所有用户信息的 JSON 数组。
- 用户可以通过向
-
用户对象定义:
- 用户对象由姓名和年龄两个属性组成。
- 用户对象的定义嵌套在
UserController类内部,仅在该类中可见。
package com.copier.springbootdemo.rest;import org.springframework.web.bind.annotation.*;
import java.util.ArrayList;
import java.util.List;@RestController
@RequestMapping("/users")
public class UserController {// 用于存储用户对象的列表private List<User> users = new ArrayList<>();// 创建新用户的端点@PostMappingpublic User createUser(@RequestBody User user) {users.add(user); return user;}// 获取所有用户的端点@GetMappingpublic List<User> getAllUsers() {return users; }// 表示用户的内部类static class User {private String name;private int age;public String getName() { return name; }public void setName(String name) { this.name = name; }public int getAge() { return age; }public void setAge(int age) { this.age = age; }}
}构建Apifox Docker镜像
编辑如下内容的Dockerfile,从FROM node:18.13.0的基础镜像开始构建一个新的镜像,然后在其中安装了apifox-cli。
FROM node:18.13.0
RUN npm i -g apifox-cli@latest --registry=https://registry.npmmirror.com/
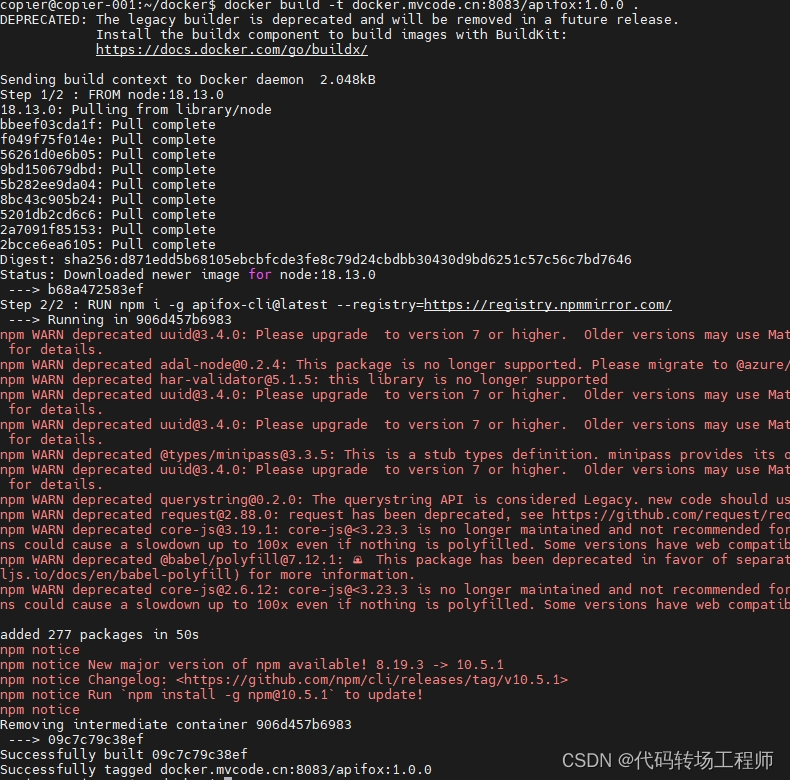
在同级目录下执行如下命令,构建工具镜像,有告警不要怕
docker build -t docker.mvcode.cn:8083/apifox:1.0.0 .
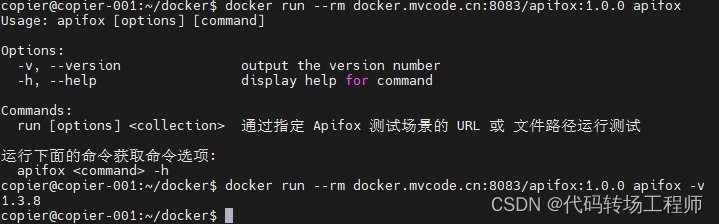
使用如下命令测试镜像是否构造成功
docker run --rm docker.mvcode.cn:8083/apifox:1.0.0 apixfox -v
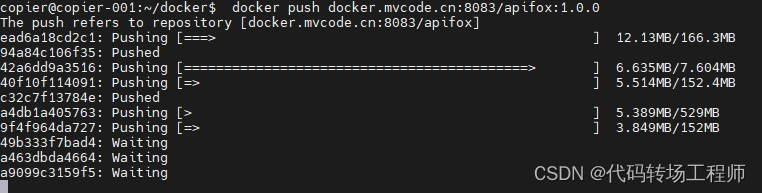
然后通过如下命令,将镜像推动到镜像库(如何构建镜像库点这里:Docker+nexus构建自己的制品库之(三)Docker仓库的使用)。推送到镜像库后我们就可以随便使用了。
docker push docker.mvcode.cn:8083/apifox:1.0.0
准备测试用例
如何使用Apifox不是本文档所关注的内容,禁用截图演示整个过程项目的文档请移步Apifox帮助文档。
创建数据模型
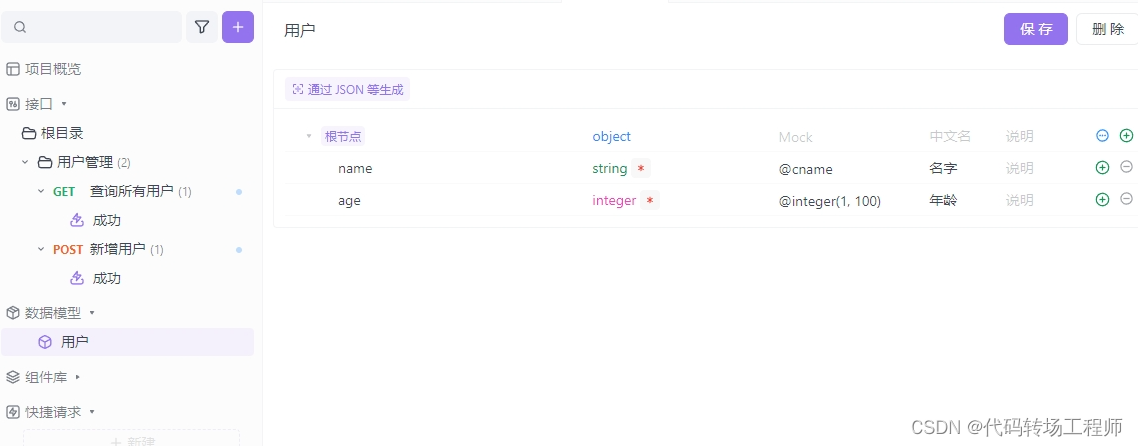
添加用户接口和测试用例
查询接口
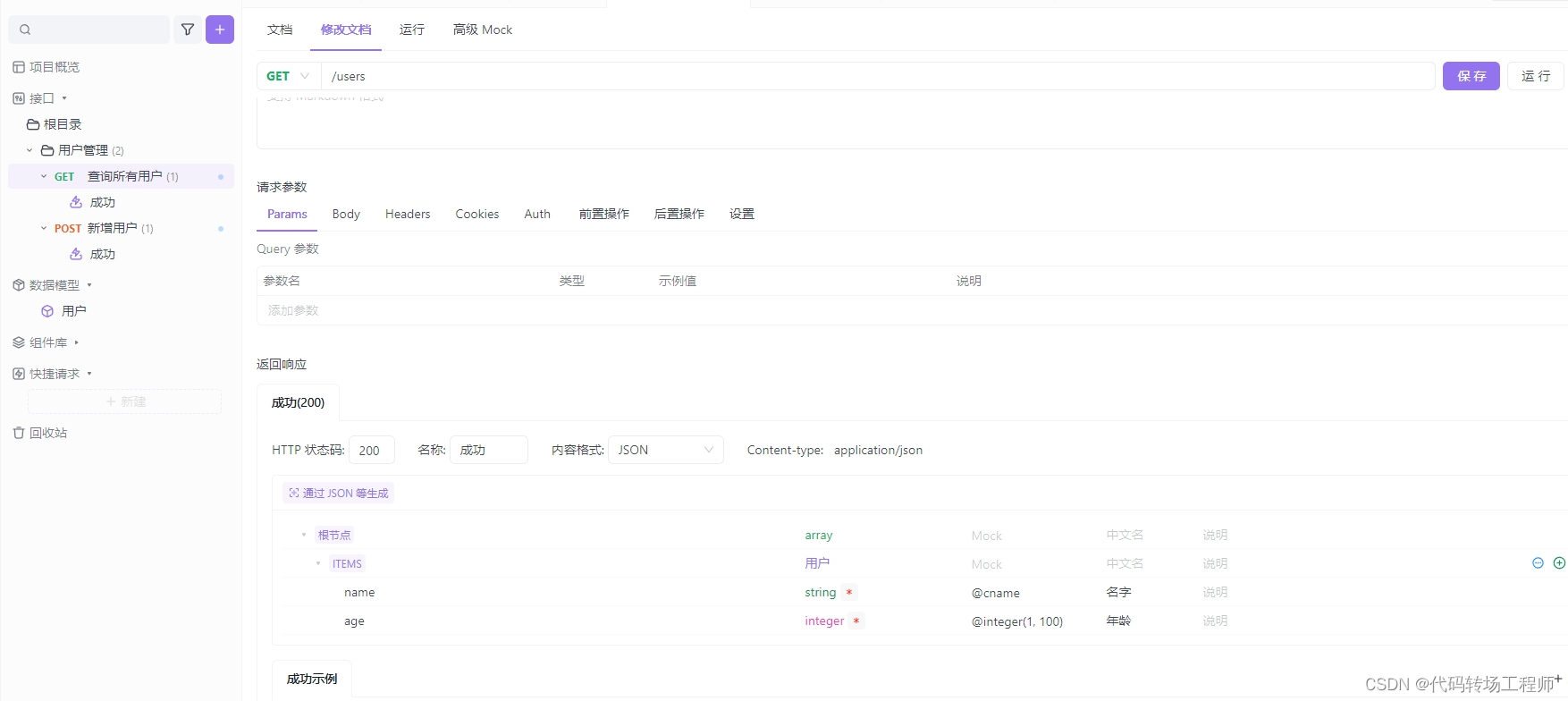
查询测试用例
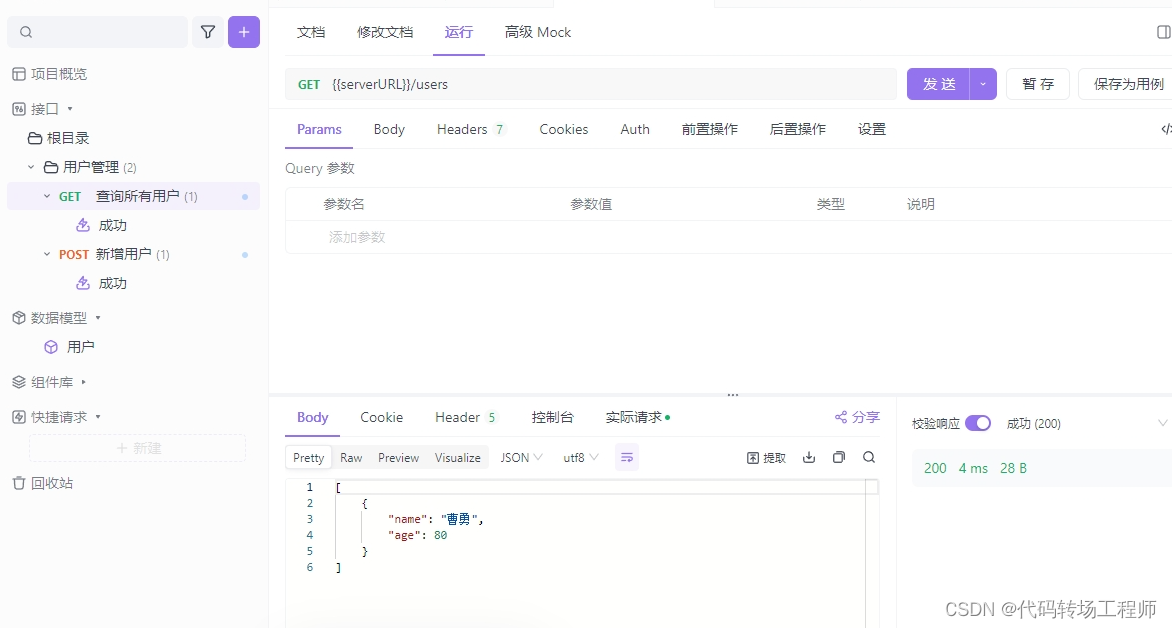
新增用户接口
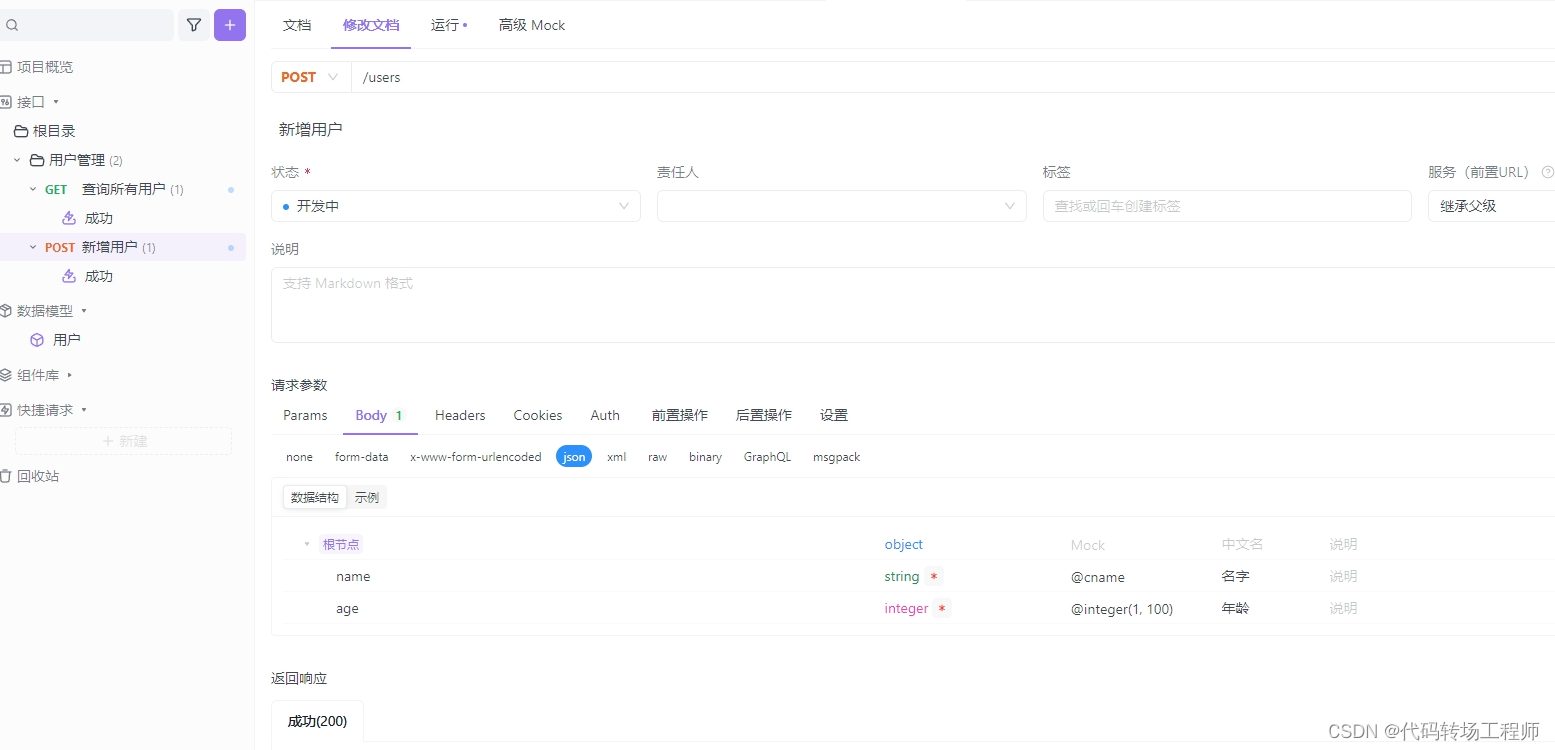
新增用户测试用例
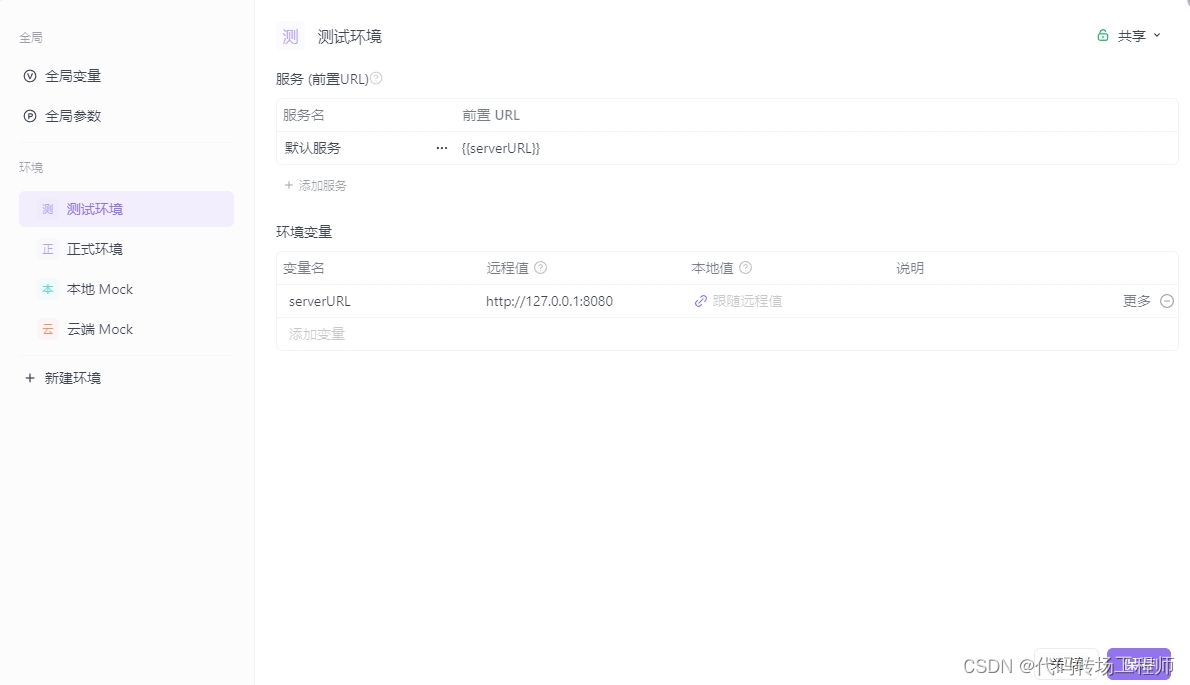
测试环境
测试场景
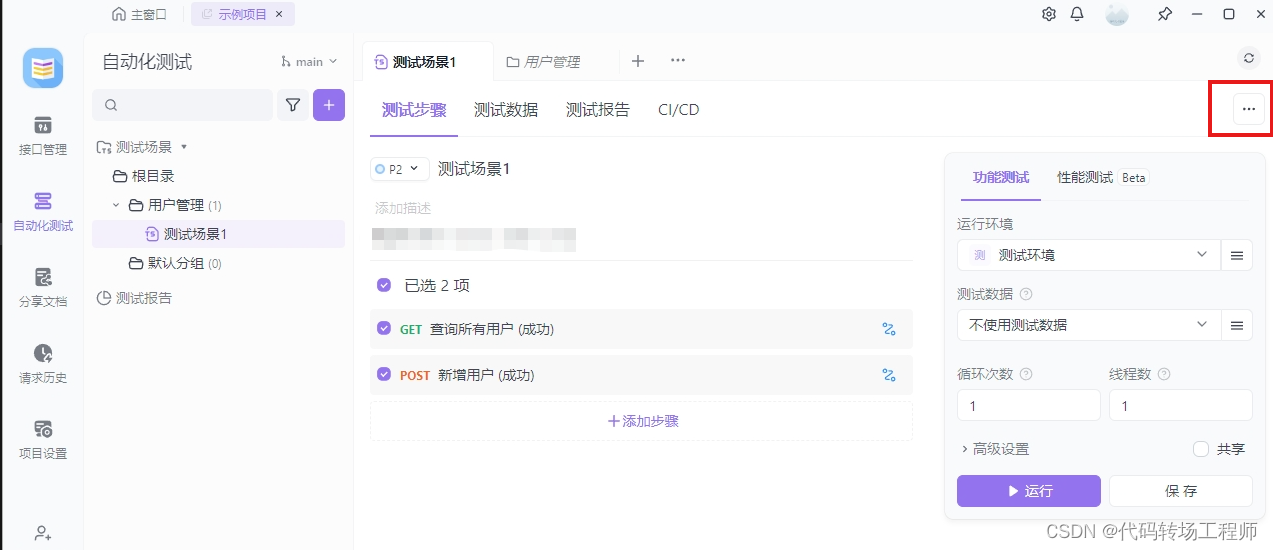
运行测试
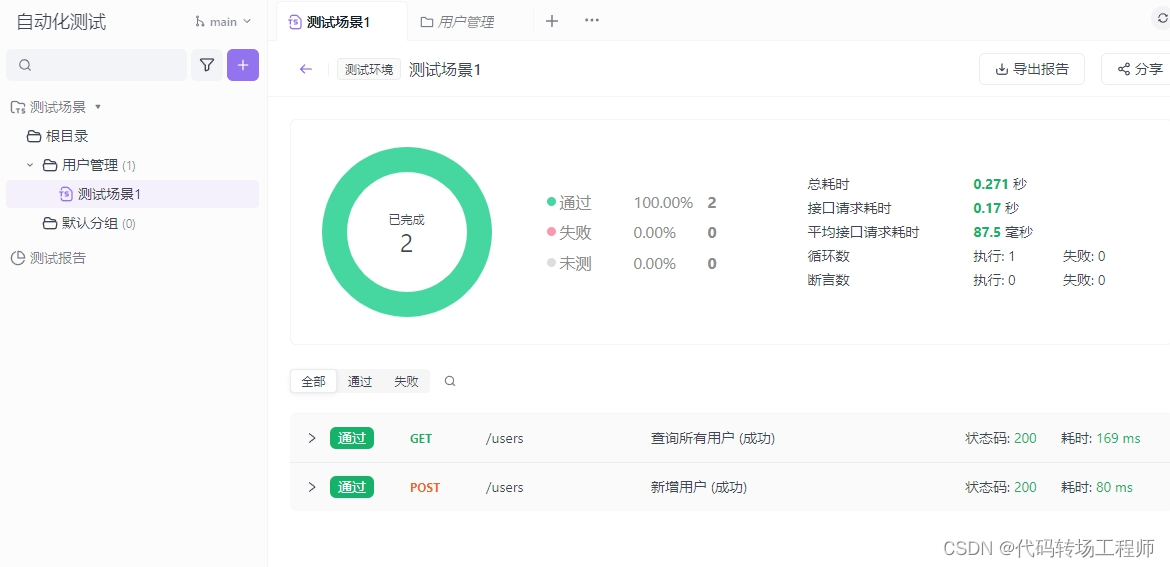
导出
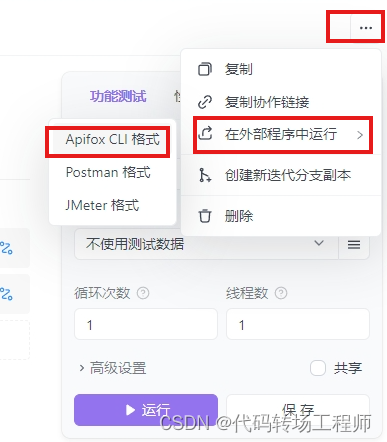
根据图中所示将测试场景导出为“Apifox ClI格式”。
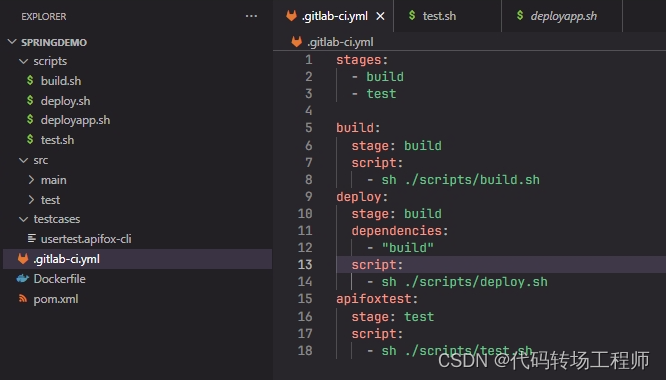
配置Gitlab CI/CD
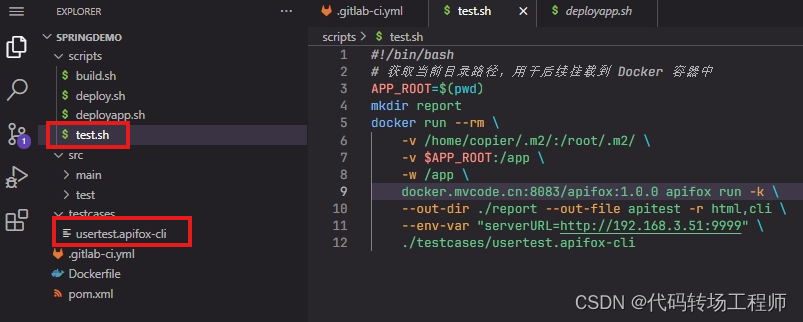
新增测试脚本
将导出的文件放在项目的testcases目录下
#!/bin/bash
# 获取当前目录路径,用于后续挂载到 Docker 容器中
APP_ROOT=$(pwd)
mkdir report
docker run --rm \-v /home/copier/.m2/:/root/.m2/ \-v $APP_ROOT:/app \-w /app \docker.mvcode.cn:8083/apifox:1.0.0 apifox run -k \--out-dir ./report --out-file apitest -r html,cli \--env-var "serverURL=http://192.168.3.52:9999" \./testcases/usertest.apifox-cli
这段脚本主要用于在 Docker 容器中运行apifox镜像,执行 API 测试,并生成测试报告。
-
APP_ROOT=$(pwd): 这一行代码将当前工作目录的路径保存在APP_ROOT变量中。 -
mkdir report: 创建一个名为report的目录,用于存储测试报告。 -
docker run --rm ...: 这是运行 Docker 容器的命令。下面是它的各个参数解释:--rm: 表示当容器退出时立即删除容器。这有助于在容器结束后自动清理资源,防止垃圾文件的堆积。-v /home/copier/.m2/:/root/.m2/: 将主机中的/home/copier/.m2/目录映射到容器内的/root/.m2/目录,这样容器内的 Maven 缓存可以重复使用。-v $APP_ROOT:/app: 将主机中的$APP_ROOT目录映射到容器内的/app目录,这样容器就可以访问主机上的测试用例文件等资源。-w /app: 指定容器的工作目录为/app,这是为了确保后续的命令在正确的工作目录下执行。docker.mvcode.cn:8083/apifox:1.0.0: 指定要运行的 Docker 镜像,其名称为apifox,版本为1.0.0。apifox run -k ...: 这是在容器内执行的具体命令,它启动了apifox工具来运行 API 测试。下面是各个参数的解释:-k: 表示以非交互式模式运行,即不需要用户输入。--out-dir ./report: 指定测试报告的输出目录为当前工作目录下的report目录。--out-file apitest: 指定测试报告的文件名为apitest。-r html,cli: 指定测试报告的格式为 HTML。--env-var "serverURL=http://192.168.3.52:9999": 设置一个环境变量serverURL,其值为http://192.168.3.52:9999,这个环境变量可能会在测试过程中被用到。./testcases/usertest.apifox-cli: 指定要运行的测试用例文件路径。
Apifox CLI(Command Line Interface,即命令行界面)主要用来以命令行方式运行接口测试过程,具体参数参照:如何使用以及参数说明。
执行自动化测试
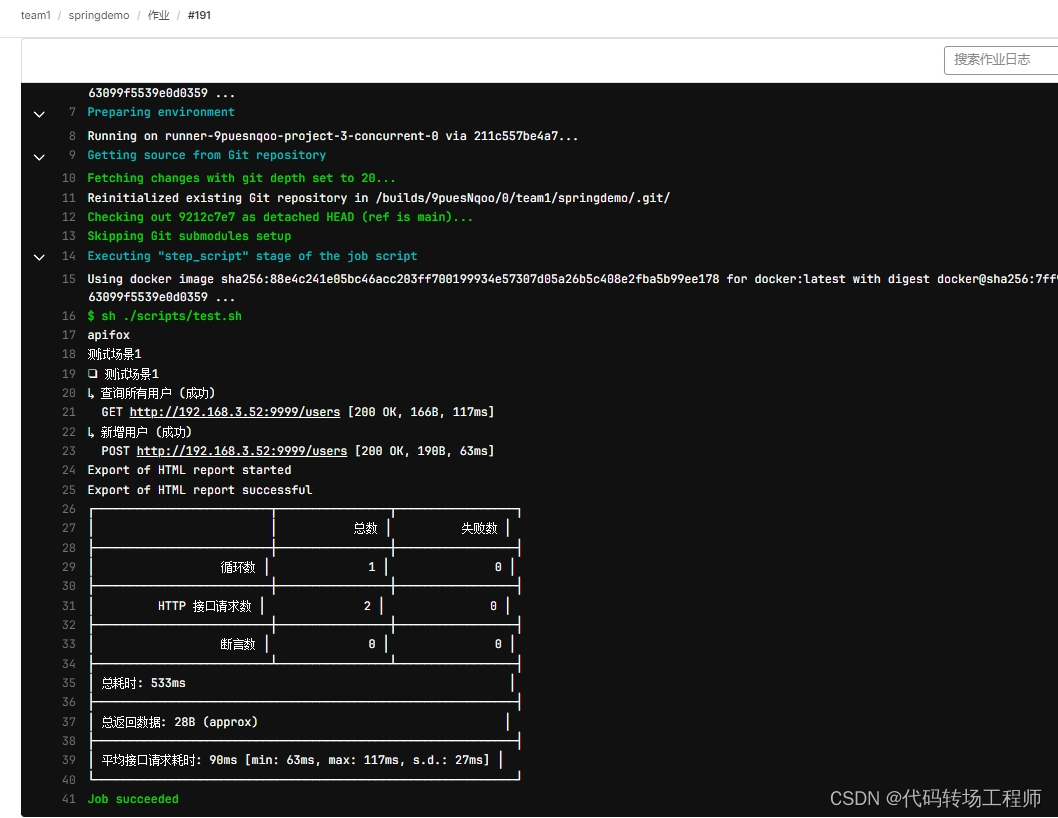
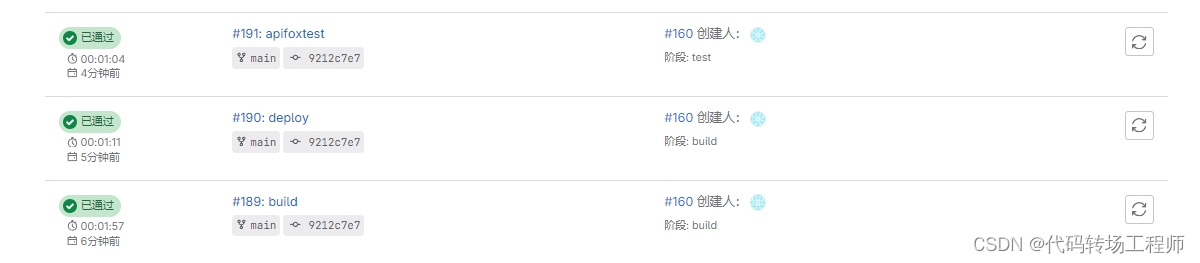
通过查看Gilab的流水线和作业我们可以查看运行结果。
流水线执行结果:
API测试结果: