聊城做网站嘉兴官网
SQL Server 2008 数据定时自动备份和自动删除方法,同一个计划兼备数据备份数数据删除的操作方法
工具/原料
-
SQL Server 2008
方法/步骤
-
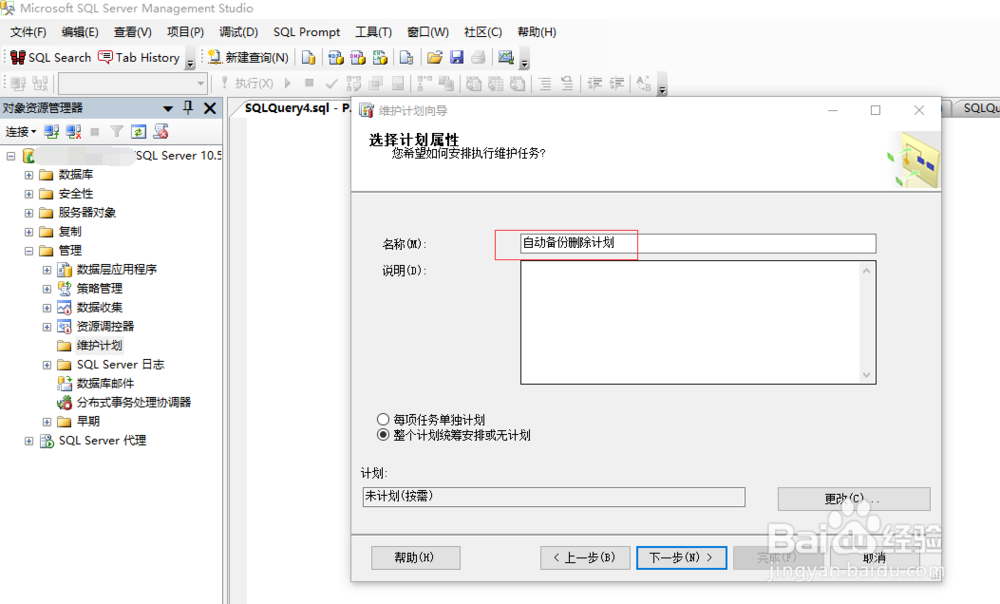
1、 点击实例名下的【管理】-【维护计划】-点击鼠标右键,点击【维护计划向导】,填写计划名称,然后再点击【下一步】;

-
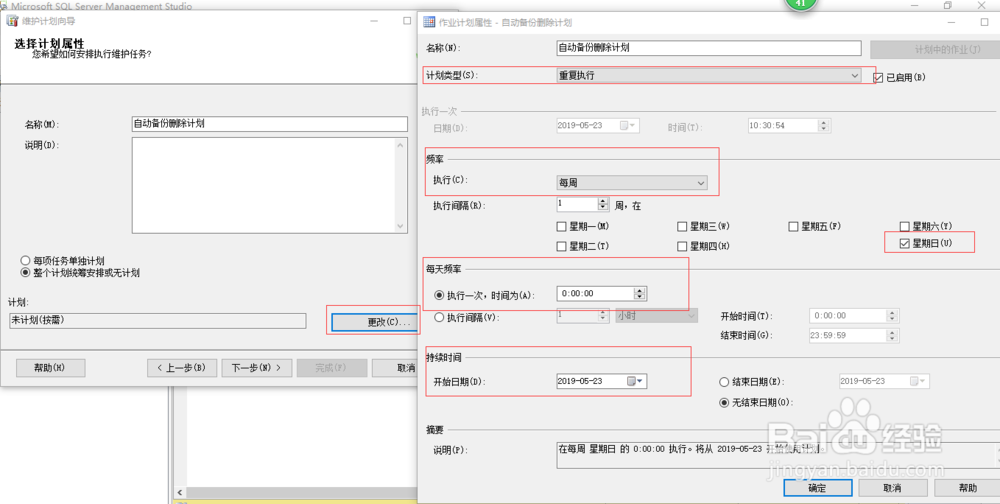
1、 在维护计划向导窗口中,点击【更改】按钮,并设置作业计划属性,包括执行计划的属性、执行计划的频率、执行计划的开始时间;然后点击【确定】-【下一步】;
-
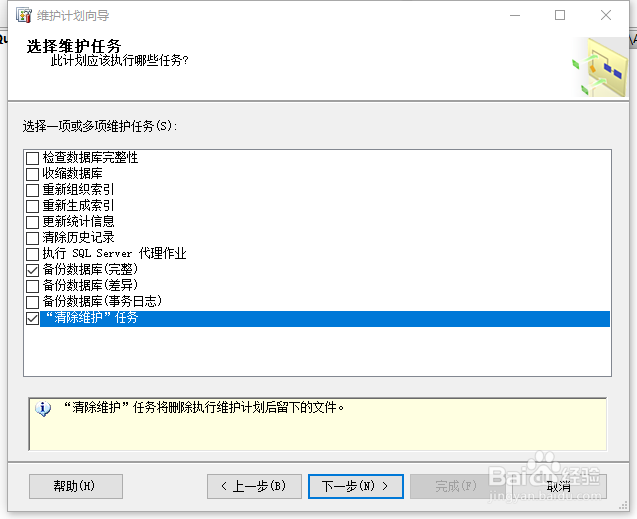
1、 在维护计划向导任务窗口中,勾选【备份数据库(完整)】-【“清除维护”任务】,然后点击【下一步】;
-
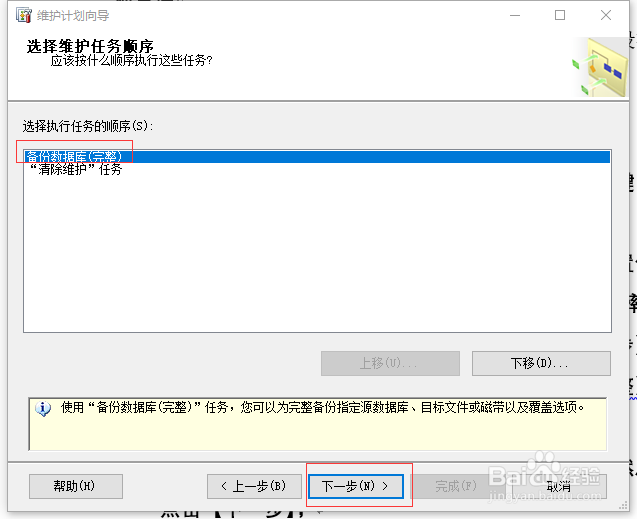
1、 在维护顺序窗口中,选择【备份数据库(完整)】,然后点击【下一步】;
-
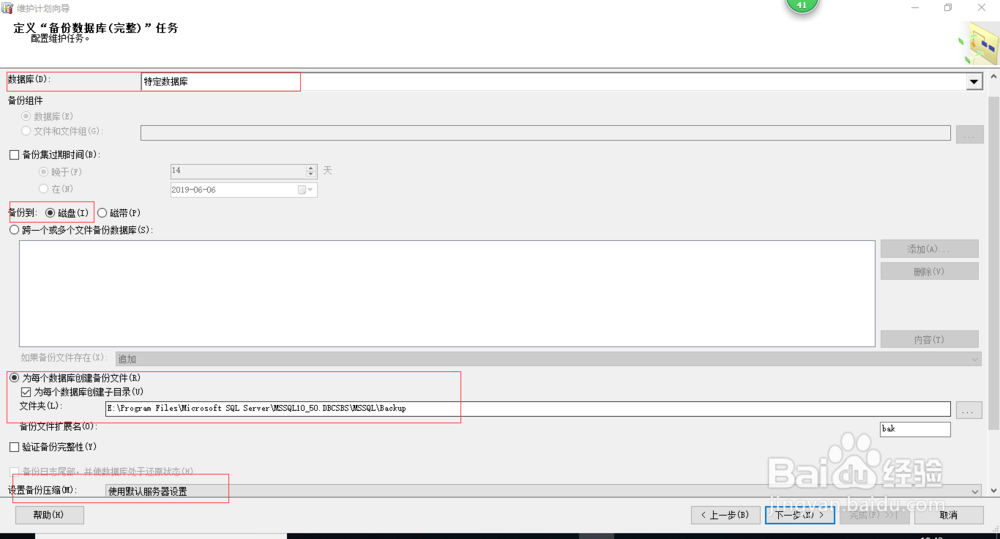
1、 在定义“备份数据库(完整)”任务窗口中,选择我们要备份的数据库(备份库可以多选)、备份的路径、备份数据的扩展名、备份数据是否压缩备份,然后点击【下一步】;
-
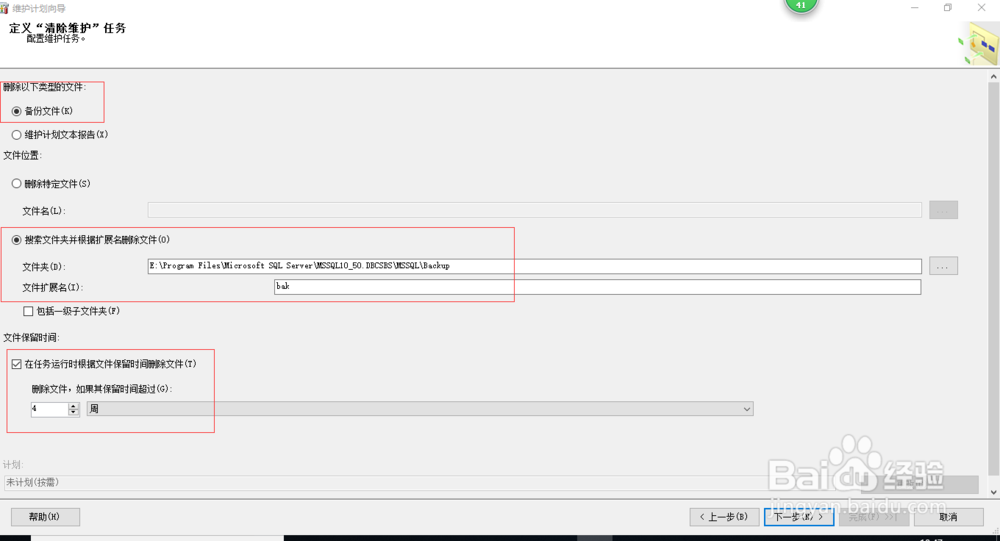
1、 在定义“清除维护”任务窗口中,选择要删除数据类型文件的类型、文件位置、扩展名、删除文件的周期,然后点击【下一步】;
-
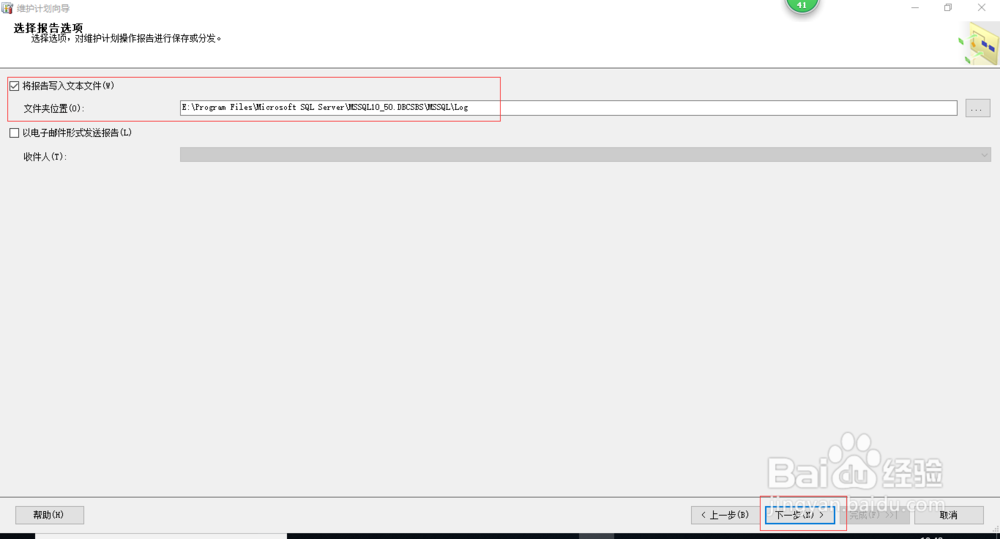
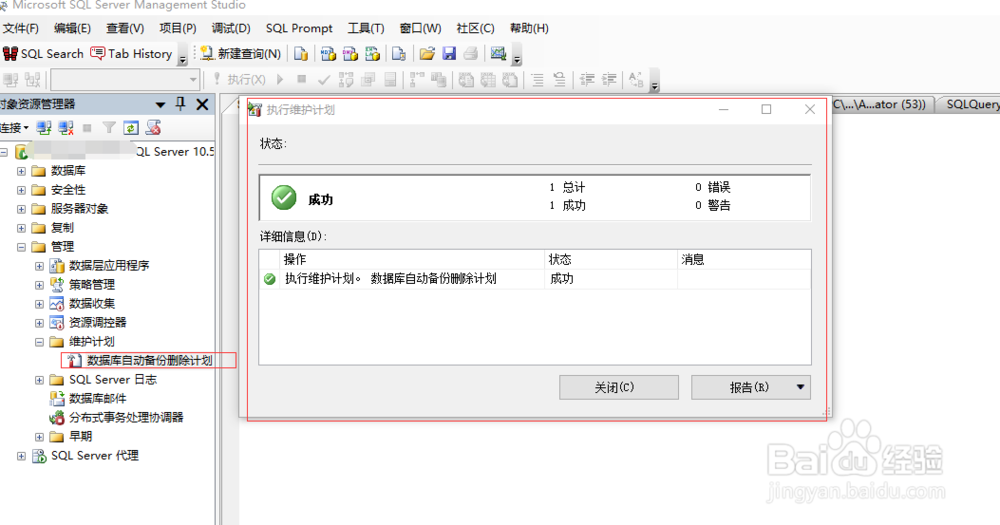
1、 再选择维护计划日志的存储位置,点击【下一步】-【完成】,就完成了数据库的自动备份、自动删除计划;