深圳自适应网站开发网站开发平台建设
99-面向对象(进阶)-面向对象的特征三:多态性_哔哩哔哩_bilibili

1.多态(仅限方法)
父类引用指向子类对象。
调用重写的方法,就会执行子类重写的方法。
编译看引用表面类型,执行看实际变量类型。

2.父子同名属性是否满足多态?不满足
满足就近原则,父类引用调用一个父类子类的同名属性,默认调父类的属性。
因为引用是父类的,调用的就是父类的属性


3.为什么要多态
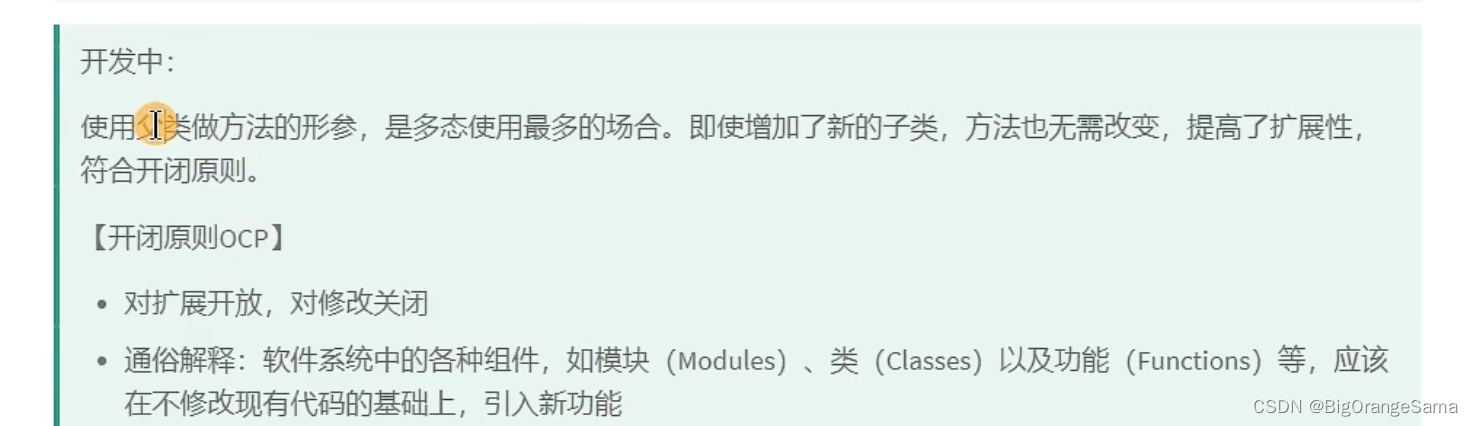
4.多态弊端
不能直接调用子类里的方法和属性,编译通不过

5.向下转型
父类引用不能直接使用子类特有的内容,所以需要向下转型‘

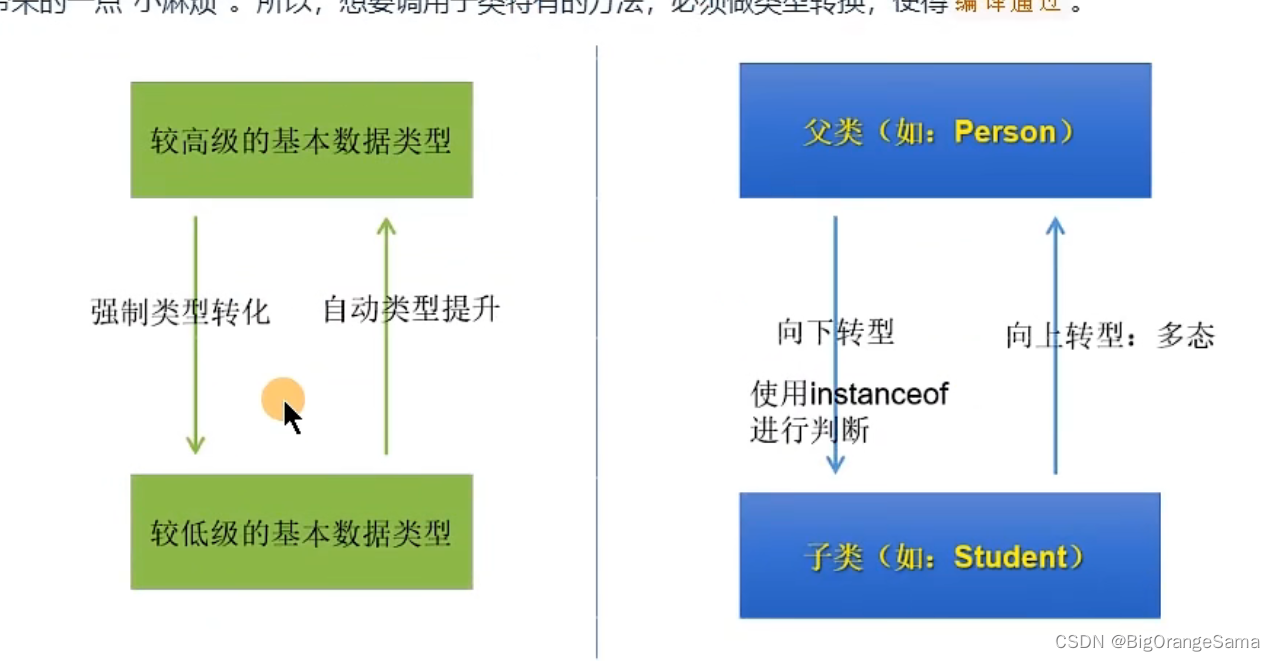
instanceof有点像golang的断言

向下转型和强转的用法很类似
6.转型可能导致异常,因此需要判断instanceof
如果实际类型不一致(woman不能转man),编译没问题,但是运行出错。

需要判断实例类型 ,
golang的断言就类似于这里的instanceof + 强转
