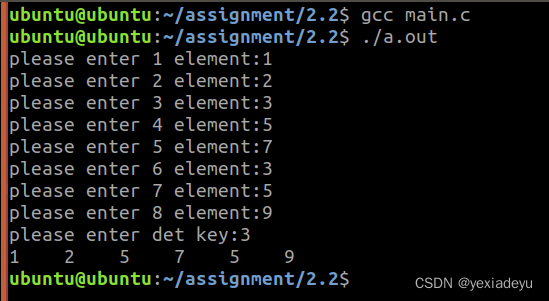
1、请简述栈区和堆区的区别?

2、有一个整形数组:int arr[](数组的值由外部输入决定),一个整型变量: x(也
由外部输入决定)。要求:
1)删除数组中与x的值相等的元素
2)不得创建新的数组
3)最多只允许使用单层循环
4)无需考虑超出新数组长度后面的元素,所以,请返回新数组的长度
例如: (1,2,3,5,7,3,5,9) x=3
原数组的有效部分变为:1,2,5,7,5,9)
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
typedef int datatype;
#define MAXSIZE 8
enum num
{FALSE=-1,SUCCESS
};
typedef struct List
{datatype data[MAXSIZE];int len;
}slist;
slist* create()
{slist *list=(slist*)malloc(sizeof(slist));if(list==NULL)return NULL;memset(list->data,0,sizeof(list->data));list->len=0;return list;
}
int full(slist *list)
{return list->len==MAXSIZE?FALSE:SUCCESS;
}
int insert_rear(datatype element,slist *list)
{if(NULL==list||full(list))return FALSE;list->data[list->len++]=element;return SUCCESS;
}
int empty(slist*list)
{return list->len==0?FALSE:SUCCESS;
}
int output(slist*list)
{if(NULL==list||empty(list))return FALSE;for(int i=0;i<list->len;i++){printf("%-5d",list->data[i]);}puts("");return SUCCESS;
}
void det_index(slist*list,int index)
{if(NULL==list||empty(list)||index<0||index>list->len)return ;for(int i=index+1;i<list->len;i++){list->data[i-1]=list->data[i];}list->len--;
}
void det_key(slist*list,datatype key)
{if(NULL==list||empty(list))return ;for(int i=0;i<list->len-1;i++){if(list->data[i]==key) {det_index(list,i);i--;}}
}
int main(int argc, const char *argv[])
{slist *list=create();int arr[MAXSIZE];for(int i=0;i<MAXSIZE;i++){printf("please enter %d element:",i+1);scanf("%d",&arr[i]);}int len=sizeof(arr)/sizeof(arr[0]);for(int i=0;i<len;i++){int flag=insert_rear(arr[i],list);if(flag==FALSE){puts("NULL or full");break;}}int key;printf("please enter det key:");scanf("%d",&key);det_key(list,key);output(list);return 0;
}
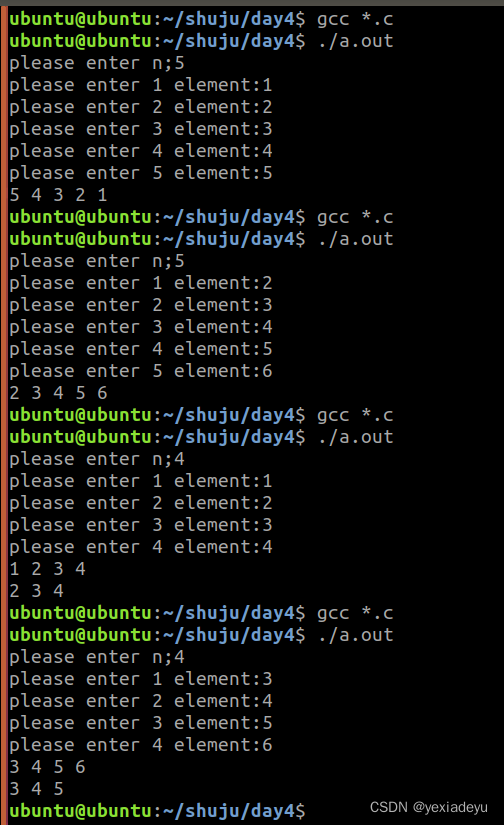
3、请编程实现单链表的头插,头删、尾插、尾删
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
enum{FALSE=-1,SUCCESS};
typedef int datatype;
//定义节点结构体
//节点:数据域、指针域
typedef struct Node
{//数据域:存储数据元素datatype data;//指针域:存储下一个节点的地址struct Node *next;
}*Linklist;
Linklist insert_head(Linklist head,datatype element);
Linklist create();
void output(Linklist head);
Linklist insert_rear(Linklist head,datatype element);
Linklist det_head(Linklist head);
Linklist det_rear(Linklist head);
int main(int argc, const char *argv[])
{Linklist head=NULL;int n;datatype element;printf("please enter n;");scanf("%d",&n);for(int i=0;i<n;i++){printf("please enter %d element:",i+1);scanf("%d",&element);// head=insert_head(head,element);//头插head=insert_rear(head,element);//尾插}//遍历output(head);//头删
// head=det_head(head);
// output(head);//尾删head=det_rear(head);output(head);return 0;
}
//创建新节点
Linklist create()
{Linklist s=(Linklist)malloc(sizeof(struct Node));if(NULL==s)return NULL;s->data=0;s->next=NULL;return s;
}
//头插入
Linklist insert_head(Linklist head,datatype element)
{//创建新节点Linklist s=create();s->data=element;//判断链表是否为空if(NULL==head){head=s;}else{s->next=head;head=s;}return head;
}
//遍历输出
void output(Linklist head)
{//判断链表是否为空if(NULL==head){puts("error");return;}//输出Linklist p=head;while(p!=NULL){printf("%d ",p->data);p=p->next;//后移}puts("");
}
//尾插
Linklist insert_rear(Linklist head,datatype element)
{//创建新节点Linklist s=create();s->data=element;//判断链表是否为空if(NULL==head){head=s;}else //存在多个链表{Linklist p=head;while(p->next!=NULL){p=p->next;}p->next=s;}return head;
}
//头删
Linklist det_head(Linklist head)
{//判断链表是否为空if(NULL==head)return head;//存在多个节点 >=1Linklist del=head;head=head->next;free(del);del=NULL;return head;
}
//尾删
Linklist det_rear(Linklist head)
{//判断链表是否为空if(NULL==head)return head;//一个节点else if(head->next==NULL){free(head);head=NULL;return head;}//多个节点 >=2else{Linklist del=head;while(del->next->next!=NULL){del=del->next;}free(del->next);del->next=NULL;return head;}
}