学会计算机编程可以做网站吗全能网站建设

按照锁的粒度来分可分为:全局锁(锁住当前数据库的所有数据表),表级锁(锁住对应的数据表),行级锁(每次锁住对应的行数据)

加全局锁:flush tables with read lock; //为当前实例加上全局锁
然后使用 mysqldump -u用户名 -p密码 备份的数据库名 > 要备份到的sql文件,注意mysqldump在windows命令行下执行。
备份完成使用unlock tables;

-------------------------------------------
表级锁分为表锁,元数据锁和意向锁
1.表锁:read lock 和 write lock 即共享读锁和独占写锁

客户端a加了读锁后,所有客户端都可以读,a不可以对该表更新,其他客户端的写操作会被阻塞,直到该锁被释放。
客户端a加了写锁后,当前a客户端对该表可读可写,但其他客户端的读写操作都会被阻塞
2.元数据锁

对一张表进行crud时会加上mdl读锁,对表结构进行变更时,会加上mdl写锁

3.意向锁(lock in share mode)
因为表锁和行锁冲突,表锁在添加时会检查每一行数据是否加了行锁,而意向锁的存在,使得免去了逐行检查行锁的必要,只要检查意向锁是否和要加的表锁兼容即可
意向锁分为:意向共享锁IS和意向排他锁IX


------------------------------------
行级锁,每次锁住对应的行数据,锁定的粒度最小,并发度最高,发生锁冲突的概率最低,在innoDB中应用。行级锁分为:行锁,间隙锁,临键锁
1.行锁是通过索引上的索引项加锁来实现的,而不是对记录加的锁,锁定了单个行记录,在RC,RR隔离级别下都支持

默认情况下,innoDB在RR隔离级别下运行,使用临键锁进行搜索和索引扫描来防止幻读
针对唯一索引,例如主键索引进行检索时,对已存在记录进行等值匹配,会自动优化为行锁
如果不通过索引检索数据,那么就会恶化为表锁

2.间隙锁,锁的是不含该记录的间隙,防止其他事务在这个间隙进行insert,产生幻读,在RR隔离级别下支持。

(1)给不存在的记录加锁时,会给相邻的记录之间加上间隙锁,注意不包含间隙两边的记录。
(2)当使用普通索引时,
例如为3加锁,这时会锁住3到7之间的间隙,即3之后第一个不满足查询需求的值,同时会把3和3之前加间隙锁,因为不知道是否会在3之前再插入一个3。
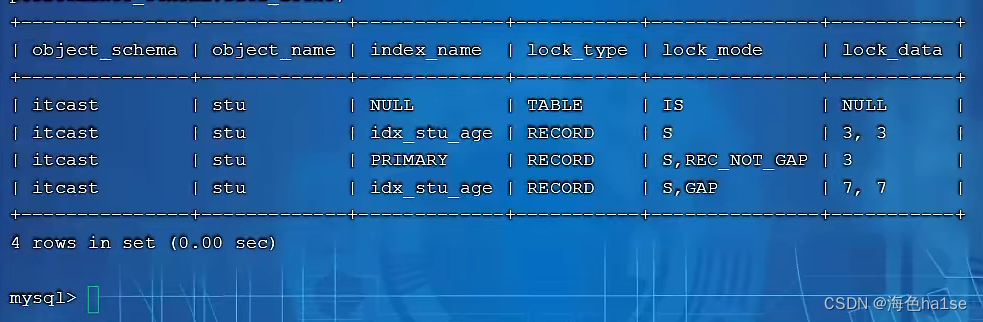
(3)当使用范围查询时,例如查询id >= 19 会对该19记录加上行锁,还会对满足查询的下一个记录25之间加上临键锁,即锁住19-25的间隙,然后再加一个临键锁,锁住25和25之后到正无穷的间隙

3.是行锁和间隙锁的结合,锁住数据的同时,锁住了间隙。