康县建设局网站平原做网站
目录
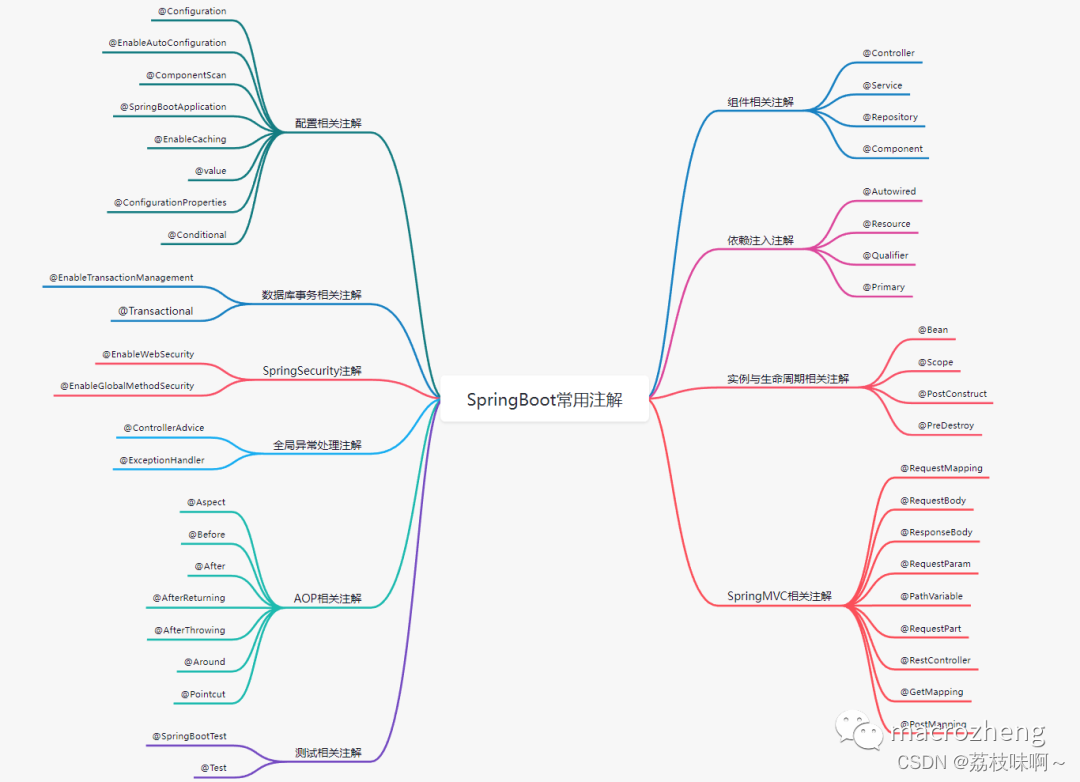
一、Web MVC 开发时,对于三层的类注解
1.1 @Controller
1.2 @Service
1.3 @Repository
1.4 @Component
二、依赖注入的注解
2.1 @Autowired
2.2 @Resource
2.3 @Resource 与 @Autowired 的区别
2.3.1 实例讲解
2.4 @Value
2.5 @Data
三、Web 常用的注解
3.1 @RequestMapping
3.2 @RequestParam
3.2.1 语法
3.2.2 实例
3.3 @PathVariable
3.4 @RequestParam 和 @PathVariable 区别
3.5 @ResponseBody 和 @RequestBody
3.6 @RestController
3.7 @ControllerAdvice 和 @ExceptionHandler
四、Spring Boot 常用的注解
4.1 @SpringBootApplication
4.2 @EnableAutoConfiguration
4.3 @Configuration
4.4 @ComponentScan
五、AOP 常用的注解
5.1 @Aspect
5.2 @After
5.3 @Before
5.4 @Around
5.5 @Pointcut
六、测试常用的注解
6.1 @SpringBootTest
6.2 @Test
6.3 @RunWith
6.4 其他测试注解
七、其他常用注解
7.1 @Transactional
7.2 @Cacheable
7.3 @PropertySource
7.4 @Async
7.5 @EnableAsync
7.6 @EnableScheduling
7.7 @Scheduled
一、Web MVC 开发时,对于三层的类注解
1.1 @Controller
@Controller 注解用于标识一个类是 Spring MVC 控制器,处理用户请求并返回相应的视图。
@Controller
public class MyController {// Controller methods
}
1.2 @Service
@Service 注解用于标识一个类是业务层组件,通常包含了业务逻辑的实现。
@Service
public class MyService {// Service methods
}
1.3 @Repository
@Repository 注解用于标识一个类是数据访问层组件,通常用于对数据库进行操作
@Repository
public class MyRepository {// Data access methods
}
1.4 @Component
@Component 是一个通用的组件标识,可以用于标识任何层次的组件,但通常在没有更明确的角色时使用。
@Component
public class MyComponent {// Class implementation
}
二、依赖注入的注解
2.1 @Autowired
@Autowired 注解用于自动装配 Bean,可以用在字段、构造器、方法上
@Service
public class MyService {@Autowiredprivate MyRepository myRepository;
}
2.2 @Resource
@Resource 注解也用于依赖注入,通常用在字段上,可以指定要注入的 Bean 的名称
@Service
public class MyService {@Resource(name = "myRepository")private MyRepository myRepository;
}
2.3 @Resource 与 @Autowired 的区别
@Autowired是 Spring 提供的注解,按照类型进行注入。@Resource是 JavaEE 提供的注解,按照名称进行注入。在 Spring 中也可以使用,并且支持指定名称。
2.3.1 实例讲解
新建 Animal 接口类,以及两个实现类 Cat 和 Dog。
public interface Animal {String makeSound();
}@Component
public class Cat implements Animal {@Overridepublic String makeSound() {return "Meow";}
}@Component
public class Dog implements Animal {@Overridepublic String makeSound() {return "Woof";}
}
编写测试用例:
@Service
public class AnimalService {@Autowiredprivate Animal cat;@Resource(name = "dog")private Animal dog;public String getCatSound() {return cat.makeSound();}public String getDogSound() {return dog.makeSound();}
}
2.4 @Value
@Value 注解用于从配置文件中读取值,并注入到属性中。
@Service
public class MyService {@Value("${app.message}")private String message;
}
2.5 @Data
@Data 是 Lombok 提供的注解,用于自动生成 Getter、Setter、toString 等方法。
@Data
public class MyData {private String name;private int age;
}
三、Web 常用的注解
3.1 @RequestMapping
@RequestMapping 注解用于映射请求路径,可以用在类和方法上。
@Controller
@RequestMapping("/api")
public class MyController {@GetMapping("/hello")public String hello() {return "Hello, Spring!";}
}
3.2 @RequestParam
@RequestParam 注解用于获取请求参数的值。
3.2.1 语法
@RequestParam(name = "paramName", required = true, defaultValue = "default")
3.2.2 实例
@GetMapping("/greet")
public String greet(@RequestParam(name = "name", required = false, defaultValue = "Guest") String name) {return "Hello, " + name + "!";
}
3.3 @PathVariable
@PathVariable 注解用于从 URI 中获取模板变量的值。
@GetMapping("/user/{id}")
public String getUserById(@PathVariable Long id) {// Retrieve user by ID
}
3.4 @RequestParam 和 @PathVariable 区别
@RequestParam用于获取请求参数。@PathVariable用于获取 URI 中的模板变量。
3.5 @ResponseBody 和 @RequestBody
@ResponseBody注解用于将方法的返回值直接写入 HTTP 响应体中。@RequestBody注解用于从 HTTP 请求体中读取数据。
3.6 @RestController
@RestController 注解相当于 @Controller 和 @ResponseBody 的组合,用于标识 RESTful 风格的控制器。
@RestController
@RequestMapping("/api")
public class MyRestController {@GetMapping("/hello")public String hello() {return "Hello, Spring!";}
}
3.7 @ControllerAdvice 和 @ExceptionHandler
@ControllerAdvice 注解用于全局处理异常,@ExceptionHandler 用于定义处理特定异常的方法。
@ControllerAdvice
public class GlobalExceptionHandler {@ExceptionHandler(Exception.class)public ResponseEntity<String> handleException(Exception e) {return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR).body("Internal Server Error");}
}
四、Spring Boot 常用的注解
4.1 @SpringBootApplication
@SpringBootApplication 是一个复合注解,包含了 @SpringBootConfiguration、@EnableAutoConfiguration 和 @ComponentScan
@SpringBootApplication
public class MyApplication {public static void main(String[] args) {SpringApplication.run(MyApplication.class, args);}
}
4.2 @EnableAutoConfiguration
@EnableAutoConfiguration 注解用于开启 Spring Boot 的自动配置机制。
4.3 @Configuration
@Configuration 注解用于定义配置类,替代传统的 XML 配置文件。
@Configuration
public class MyConfig {@Beanpublic MyBean myBean() {return new MyBean();}
}
4.4 @ComponentScan
@ComponentScan 注解用于配置组件扫描的基础包。
@SpringBootApplication
@ComponentScan(basePackages = "com.example")
public class MyApplication {public static void main(String[] args) {SpringApplication.run(MyApplication.class, args);}
}
五、AOP 常用的注解
5.1 @Aspect
@Aspect 注解用于定义切面类,通常与其他注解一起使用。
@Aspect
@Component
public class MyAspect {// Aspect methods
}
5.2 @After
@After 注解用于定义后置通知,方法在目标方法执行后执行。
@After("execution(* com.example.service.*.*(..))")
public void afterMethod() {// After advice
}
5.3 @Before
@Before 注解用于定义前置通知,方法在目标方法执行前执行
@Before("execution(* com.example.service.*.*(..))")
public void beforeMethod() {// Before advice
}
5.4 @Around
@Around 注解用于定义环绕通知,方法可以控制目标方法的执行。
@Around("execution(* com.example.service.*.*(..))")
public Object aroundMethod(ProceedingJoinPoint joinPoint) throws Throwable {// Before adviceObject result = joinPoint.proceed(); // Proceed to the target method// After advicereturn result;
}
5.5 @Pointcut
@Pointcut 注解用于定义切点,将切点表达式提取出来,供多个通知共享。
@Pointcut("execution(* com.example.service.*.*(..))")
public void serviceMethods() {// Pointcut expression
}
六、测试常用的注解
6.1 @SpringBootTest
@SpringBootTest 注解用于启动 Spring Boot 应用程序的测试。
@SpringBootTest
public class MyApplicationTests {// Test methods
}
6.2 @Test
@Test 注解用于标识测试方法。
@Test
public void myTestMethod() {// Test method
}
6.3 @RunWith
@RunWith 注解用于指定运行测试的类。
@RunWith(SpringRunner.class)
@SpringBootTest
public class MyApplicationTests {// Test methods
}
6.4 其他测试注解
@Before: 在测试方法之前执行。@After: 在测试方法之后执行。@BeforeClass: 在类加载时执行一次。@AfterClass: 在类卸载时执行一次。
七、其他常用注解
7.1 @Transactional
@Transactional 注解用于声明事务,通常用在方法或类上。
@Service
@Transactional
public class MyTransactionalService {// Transactional methods
}
7.2 @Cacheable
@Cacheable 注解用于声明方法的结果可以被缓存。
@Service
public class MyCachingService {@Cacheable("myCache")public String getCachedData(String key) {// Method implementation}
}
7.3 @PropertySource
@PropertySource 注解用于引入外部的属性文件。
@Configuration
@PropertySource("classpath:my.properties")
public class MyConfig {// Configuration methods
}
7.4 @Async
@Async 注解用于声明异步方法,通常用在方法上。
@Service
public class MyAsyncService {@Asyncpublic void asyncMethod() {// Asynchronous method implementation}
}
7.5 @EnableAsync
@EnableAsync 注解用于开启异步方法的支持。
@Configuration
@EnableAsync
public class MyConfig {// Configuration methods
}
7.6 @EnableScheduling
@EnableScheduling 注解用于开启计划任务的支持。
@Configuration
@EnableScheduling
public class MyConfig {// Configuration methods
}
7.7 @Scheduled
@Scheduled 注解用于定义计划任务的执行时间。
@Service
public class MyScheduledService {@Scheduled(cron = "0 0 12 * * ?") // Run every day at 12 PMpublic void scheduledMethod() {// Scheduled method implementation}
}
以上几乎涵盖了所有springBoot和springFramework的常见注解,博客整体框架参考学习Spring Boot 注解,这一篇就够了(附带部分注解实例讲解)_springboot注解 举例-CSDN博客