做网站 信息集成过程的顺序网站域名归属权
前言:
每日一练系列,每一期都包含5道选择题,2道编程题,博主会尽可能详细地进行讲解,令初学者也能听的清晰。每日一练系列会持续更新,暑假时三天之内必有一更,到了开学之后,将看学业情况更新。
5道选择题:
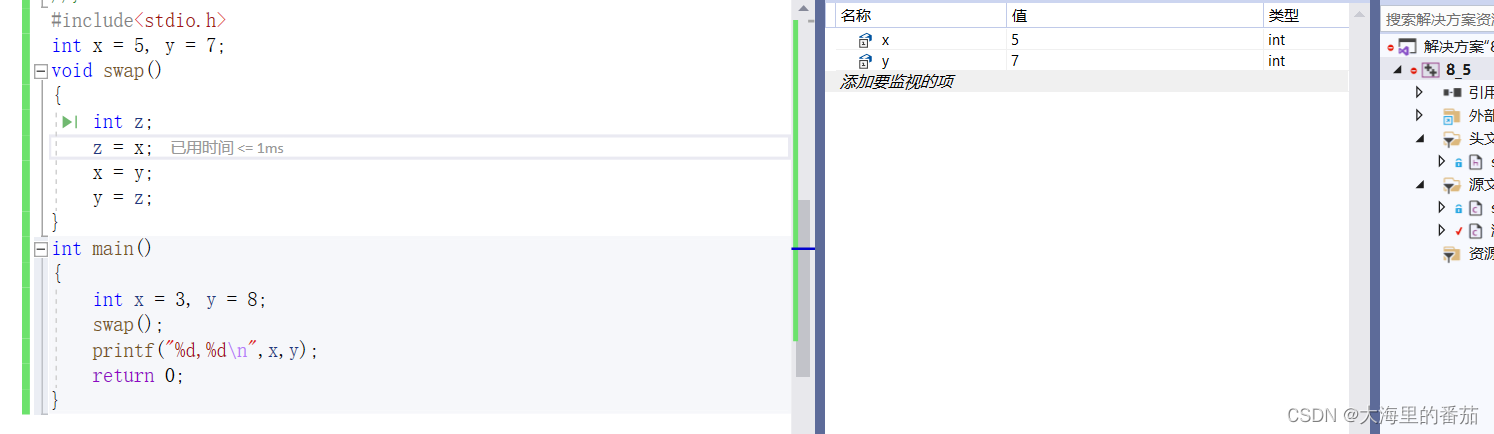
1、执行下面程序,正确的输出是( )
#include<stdio.h>
int x=5,y=7;
void swap()
{
int z;
z=x;
x=y;
y=z;
}
int main()
{
int x=3,y=8;
swap();
printf("%d,%d\n",x,y);
return 0;
} A.5,7 B.7,5 C.3,8 D.8,3
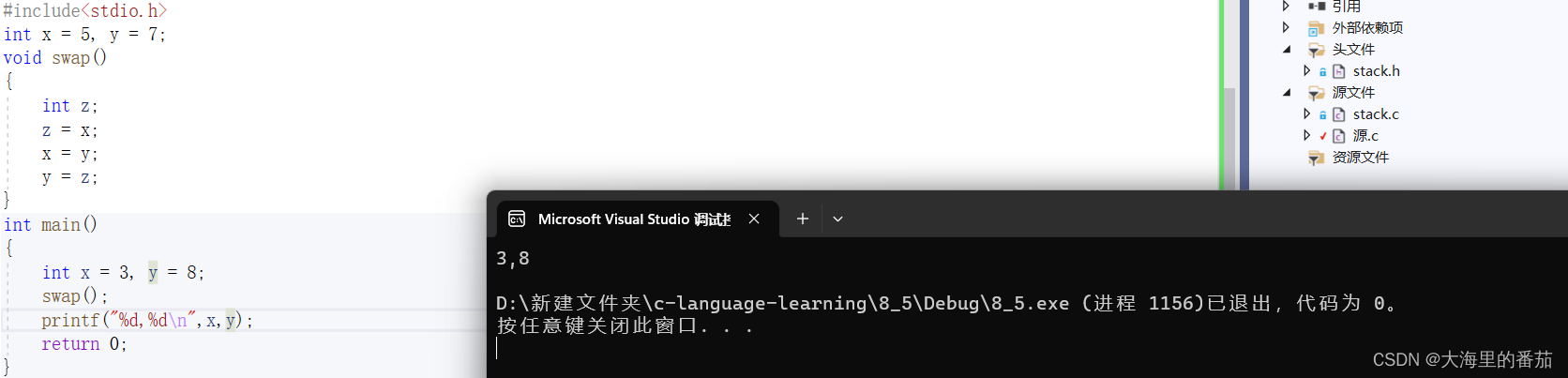
解析:根据代码分析,注意:虽然首先定义了两个全局变量x,y,但我们依然可以将局部变量的名称作x,y 我们从main进入程序,先在局部中定义x,y为3和8,swap函数的作用是将x和y的值进行交换,z是实现它们交换的中间变量。但是,但是,要注意的一点是,swap并没有传参,更没有传实参,也就是说,交换x,y是影响不到main函数中的,它交换的仅仅只是全局变量x,y 所以最后打印出来的结果为原来的数据,也就是3,8,选C
2、以下不正确的定义语句是( )
A: double x[5] = {2.0, 4.0, 6.0, 8.0, 10.0};
B: char c2[] = {'\x10', '\xa', '\8'};
C: char c1[] = {'1','2','3','4','5'};
D: int y[5+3]={0, 1, 3, 5, 7, 9};
解析:\x后面的数代表着是十六进制的数,而\或者是\0之后的数代表着是八进制的数,而八进制数只能是0~7,B显然不对,故选B
3、 test.c 文件中包括如下语句,文件中定义的四个变量中,是指针类型的变量为【多选】( )
define INT_PTR int*
typedef int* int_ptr;
INT_PTR a, b;
int_ptr c, d;A.a B.b C.c D.d
解析:根据宏定义的理解,我们直接将INT_PTR给替换成int*,则为int*a,b;故可以判断出,a为指针变量,b不是,而typedef int* int_ptr相当于是给int*取了个叫int_ptr的类型,是一个将int和*联合在一起的整体,故c,d为指针变量,选ACD
4、 若给定条件表达式 (M)?(a++):(a--) ,则其中表达式 M ( )
A: 和(M==0)等价 B: 和(M==1)等价 C: 和(M!=0)等价 D: 和(M!=1)等价
解析:(M)?(a++):(a--)的意思是,M为真即执行a++,为假执行a--。这里M的含义便是M不为0,M为真,M为0,则为假。那么一步步分析,A选项,M==0是M为0为真,错。B选项,M==1是M为1为真,错。C选项M!=0即当M不为0时为真,对。D选项M!=1当M不等于1时为真,错。综上所述,答案为C
5、有如下定义语句,则正确的输入语句是【多选】( )
int b;
char c[10]; A: scanf("%d%s",&b,&c); B: scanf("%d%s",&b,c);
C: scanf("%d%s",b,c); D: scanf("%d%s",b,&c);
解析:b是一个整型,c是一个字符数组,而只有数组的名字在9成9情况下代表着数组起始地址。而scanf的使用需要目标取地址,然后根据地址对目标内容修改,选项A:在这里,&c不是单一的c,故c此时不是首元素的地址,而是首元素,&c效果和单个c一样。故A对。选项B:&b没错,c没错,故B对。选项C,b错,没取地址,故C错。选项D和选项C犯了一样的错误,故D错。选AB
编程题1:
打印从1到最大的n位数_牛客题霸_牛客网
static int arr[100001];
int* printNumbers(int a,int*x)
{
int b = 1;
while (a)
{
b *= 10;
a--;
}
int c = 0;
for (c = 1; c < b; c++)
{
arr[c - 1] = c;
}*x=--b;
return arr;
}编程题2:
计算日期到天数转换_牛客题霸_牛客网

这道题简单解法其实将每个月的天数枚举出来,然后根据当前月份向前累加满月的天数,然后再加上当前月所在的天数。最终考虑平闰年的2 月份区别是否增加一天。
其中需要注意的是平年和闺年的判断,而且是闺年的月份大于2 的时候,也就是 2月走完,总天数才能加1比如2000年2月18日,虽然是闰年,但是2月都没走完那是不能加上闰年多出的一天的)
#include<stdio.h>
int main()
{
int year = 0;
int month = 0;
int day = 0;
scanf("%d %d %d", &year, &month, &day);
int arr1[13] = { 0,31,28,31,30,31,30,31,31,30,31,30,31 };
int arr2[13] = { 0,31,29,31,30,31,30,31,31,30,31,30,31 };
int sum = 0;
int i = 0;
for (i = 1; i < month; i++)
{
if (year % 400 == 0 || (year % 4 == 0 && year % 100 != 0))
{
sum += arr2[i];
}
else
{
sum += arr1[i];
}
}
sum += day;
printf("%d", sum);
}好了,今天的练习到这里就结束了,感谢各位友友的来访,祝各位友友前程似锦O(∩_∩)O