宜昌公司做网站机械加工网上怎么接单

Kotlin设计模式:享元模式(Flyweight Pattern)
在移动应用开发中,内存和CPU资源是非常宝贵的。享元模式(Flyweight Pattern)是一种设计模式,旨在通过对象重用来优化内存使用和性能。本文将深入探讨享元模式的应用,并通过Kotlin代码示例展示其实现方式。

享元模式的目的
享元模式的主要目的是平衡应用程序中的内存使用。该模式强调对象的重用,而不是每次都创建新的对象。这意味着,通过享元模式,你可以节省对象创建时的CPU和内存开销,同时加快垃圾回收的速度。
享元模式有两种实现方式:
- 控制对象池中的对象移除:需要小心处理,以防止移除正在使用的对象。
- 为未使用的对象分配内存:不删除对象池中的对象,这意味着需要为当前未使用的对象分配内存。
这两种方法各有利弊,应根据具体需求选择合适的实现方式。
示例场景
假设你的应用在同一个屏幕的多个地方使用相同的图片。如果每次都创建新对象,你的应用可能会因OutOfMemoryError崩溃。通过使用享元模式,可以显著减少内存占用。例如,有3张大小为5MB的图片,通常总共需要15MB内存,但使用享元模式后,只需要5MB内存。
Kotlin中的享元模式实现
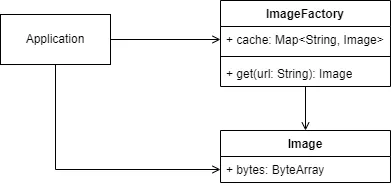
在享元模式中,我们通常使用一个工厂类(Factory)来创建对象。应用程序依赖于Image和ImageFactory,通过ImageFactory创建Image对象。
代码示例
首先,定义一个Image数据类和一个ImageFactory工厂类:
data class Image(val bytes: ByteArray)class ImageFactory {private val cache = mutableMapOf<String, Image>()private suspend fun getImage(url: String): Image =cache[url] ?: fetchImage(url).also { image -> cache[url] = image }
}
使用享元模式
以下是如何在应用中使用上述工厂类的示例:
fun main() {val factory = ImageFactory()val scope = CoroutineScope(Dispatchers.IO)scope.launch {val image = factory.get("image")}scope.launch {val image = factory.get("image")}
}
在这个示例中,有一个同步问题:在第一个fetchImage(url)结束之前,另一个协程也尝试从缓存中获取相同URL的图片,由于缓存中尚未存在该图片,因此也调用了fetchImage(url)。
使用Mutex解决同步问题
我们可以使用Mutex来解决这个问题,它的工作原理与享元模式类似:
class ImageFactory {private val cache = mutableMapOf<String, Image>()private val locks = mutableMapOf<String, Mutex>()private val lock = Mutex()suspend fun get(url: String): Image {val imageMutex = lock.withLock {locks.getOrPut(url) { Mutex() }}val image = imageMutex.withLock {getImage(url)}locks.remove(url)return image}private suspend fun getImage(url: String): Image =cache[url] ?: fetchImage(url).also { image -> cache[url] = image }
}
在这个实现中,我们使用了一个全局的Mutex来管理每个URL对应的Mutex。通过这种方式,可以确保同一时间只有一个协程在获取和缓存相同的图片。
结论
享元模式是一种强大的设计模式,适用于需要频繁创建相似对象的场景。通过重用对象,可以显著减少内存和CPU开销。本文展示了如何在Kotlin中实现享元模式,并通过实际示例演示了其应用。希望这些内容能帮助你在实际开发中更高效地管理资源。