佛山市建设工程交易中心已矣seo排名点击软件
2022年开始,PMP®考试启用了新考纲,不光考试内容进行了大刀阔斧的改革,出题方式也进行了更新。除原有的PMBOK6®和PMBOK7®主考教材外,还增加了一本《敏捷实践指南》。
别小看新加的这本书,它虽然与PMBOK®代表的预测法属于完全不同的两种项目管理方法,但在新考纲后的PMP®考试占到了一半以上的题目,成为了PMP考生的又一本必学教材。现在的PMP——有难度。

试的出题方式也有了较大改变,虽然题型还是选择题(单选+多选共180道),但题目从原来的教材理论题变成了情景题。给你一个实际项目管理情境,根据情境选出最合适的选项,更加深入的考察PMP考生对教材内容的理解与运用。
(1)在真正备考PMP时,那究竟难在哪儿呢?
1、内容多知识杂 自学根本记不住
PMP®内容繁多又复杂,知识点涉及到范围管理、时间管理、成本管理、质量管理、人力资源管理、沟通管理、风险管理、采购管理、干系人管理等等多个方面,这些知识点涉及到的内容非常广泛,就算在培训班跟着老师学习,都要按照计划走才能捋明白,所以,如果没有强大的知识基础,千万别自学考试。这也是很多人觉得难的原因之一。
2、自律性差 备考时间管理难把控
大部分考PMP®证书的都是在职打工人,每天上班已经很累,下班后只想躺在沙发上刷手机放空自己,备考这件事,如果没人监督,很容易偷懒放弃。
3、考试费用高 时间精力投入多
PMP®考试3900,这本身就是一笔不小的费用,如果一次不过,复考除了再投入更多的精力和时间,还要再补2500,合算下来,时间、精力、金钱成本都非常高。这也造成了有些人因为经济原因吐槽“难”。
所以我建议还是去选择一个学习队伍,至少是可以节省很多时间精力了,而且也能帮助工作党快速高效的备考,后续为拿pmp证书打下很好的基础。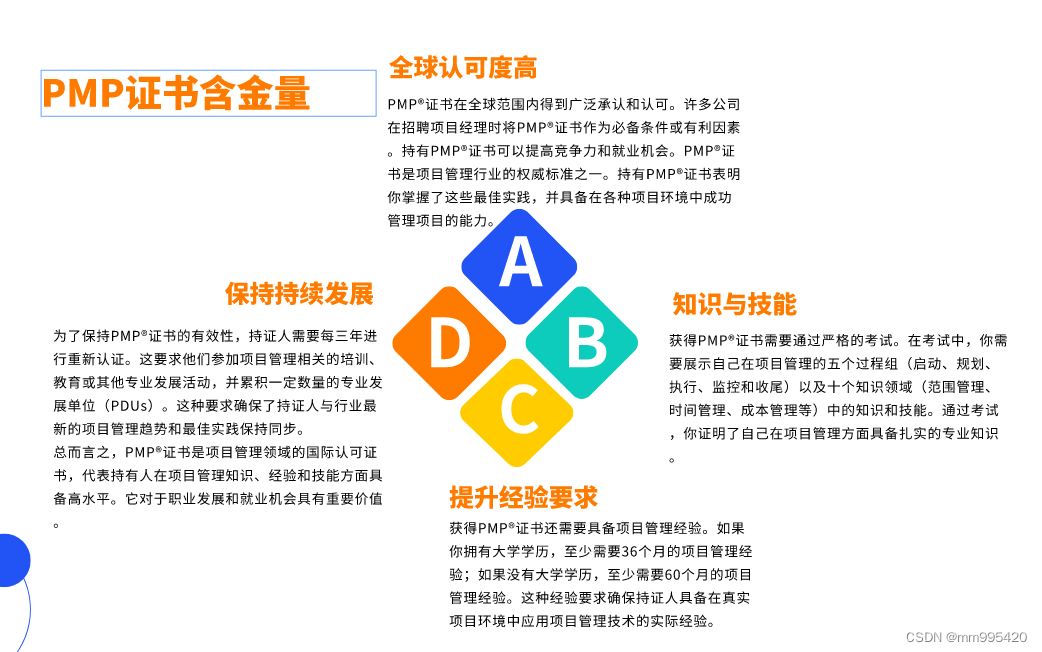
pmp备考学习整理内容都在里面了,备考pmp的可以获取
全新PMP备考攻略指南全套!好东西别错过腾讯文档-在线文档![]() https://docs.qq.com/doc/DQVJhbndQTVJwZWht
https://docs.qq.com/doc/DQVJhbndQTVJwZWht
