以下可以制作二维码的网站为广西执业药师培训网站
一、峰会简介
本次大会由主论坛和3场分论坛组成,嘉宾阵容强大,内容丰富多彩。来自政企学界的百名专家从产学研用多种维度对企业数据管理、产业数据资源化建设等视角展开。大会围绕“产业数据价值化”为主题,秉持“让数据用起来”的使命,共同缔造了5场圆桌论坛,31场主题分享。
大会还围绕“智能制造+”“智慧政务+”“智慧校园+”三大热点板块设置智慧校园、数字政务、智能制造平行分论坛。以理论研究和技术应用为切入点,与会人员就分论坛主题——“智造中台 制造未来”“共建共享,发挥公共数据价值”“以人为本、数据为善,推进数字化转型”发表主旨演讲、开展圆桌论坛,输出观点、碰撞思维。
产业数据价值化对于企业的运营和发展具有重要意义,可以帮助企业提高效率和效益、实现精准营销、实现精细化管理、预测市场需求和趋势、提高产品质量和客户满意度等。因此,对于现代企业来说,重视并加强产业数据价值化工作是非常必要的。
1、提高效率和效益:通过对产业数据进行分析和挖掘,企业可以了解自身的运营情况和市场需求,从而调整生产和销售策略,提高生产效率和销售效益。例如,通过分析销售数据,企业可以了解不同产品的销售情况,从而调整产品结构和定价策略,提高销售额和利润率。
2、实现精准营销:通过对消费者行为数据的分析,企业可以了解消费者的兴趣和需求,从而制定精准的营销策略。例如,通过对消费者购买记录和浏览行为的分析,企业可以向感兴趣的消费者推送相关产品的广告和促销信息,提高广告的点击率和转化率。
3、帮助企业实现精细化管理:通过对产业数据的采集和分析,企业可以更加精确地了解产品的需求、市场的变化、消费者的喜好等信息。企业可以根据这些数据,调整产品的生产计划、销售策略和市场定位,从而提高产品的市场竞争力和盈利能力。
4、预测市场需求和趋势:通过对大量产业数据的分析和挖掘,企业可以预测未来的市场需求和趋势,从而提前做好准备,把握商机。例如,通过分析历史销售数据和市场趋势,企业可以预测未来一段时间内产品的需求量和市场价格,从而调整生产和销售策略。
5、提高产品质量和客户满意度:通过对产品数据的分析和挖掘,企业可以了解产品的质量和客户反馈情况,从而及时发现和解决问题,提高产品质量和客户满意度。例如,通过分析客户反馈和产品使用数据,企业可以发现产品存在的问题和改进点,从而进行改进和优化。
二、峰会核心资料清单
主论坛

大数据技术应用实践论坛(主论坛下午)

智慧校园论坛

数字政务论坛

智能制造论坛
![]()
三、峰会核心资料截图示例
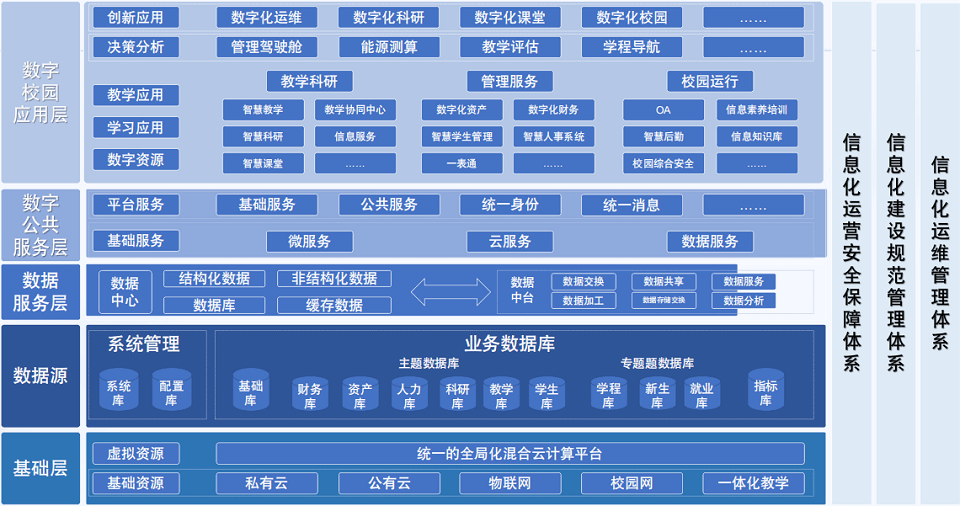
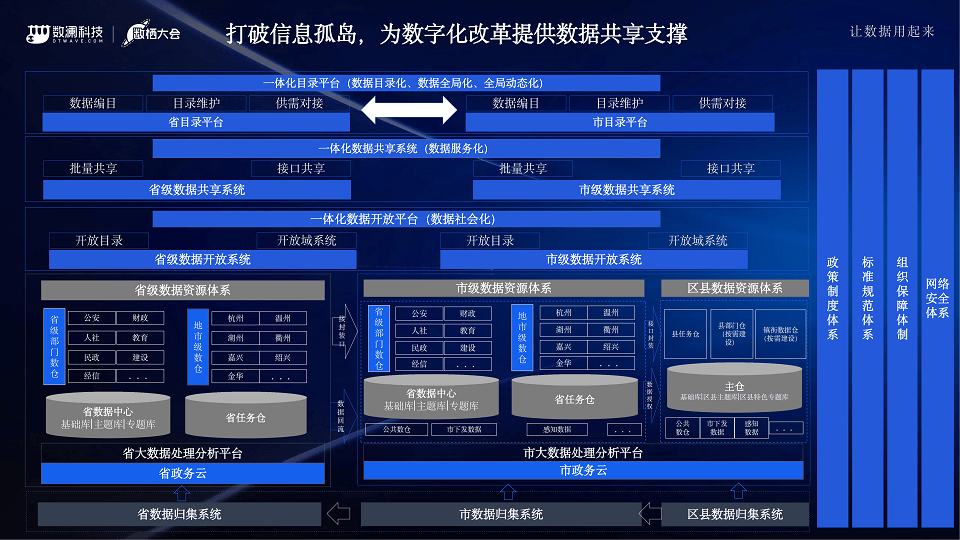
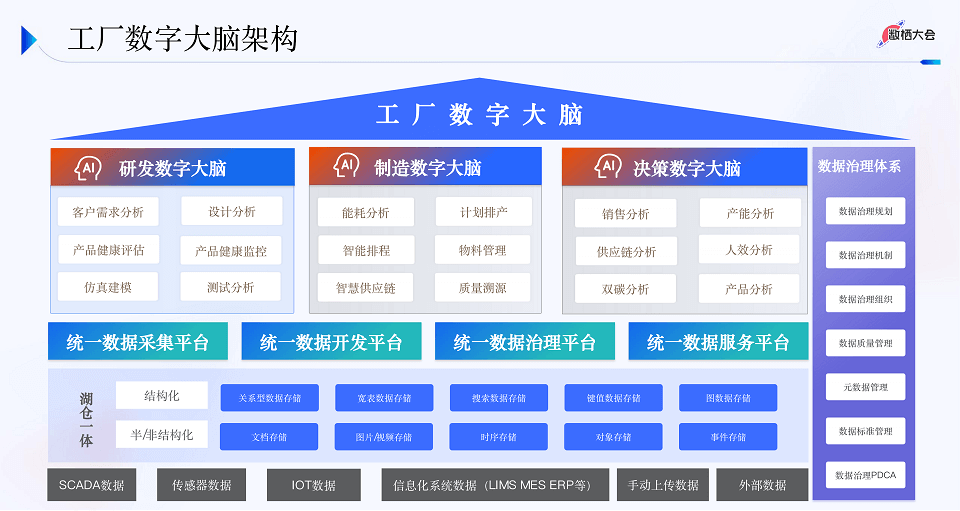
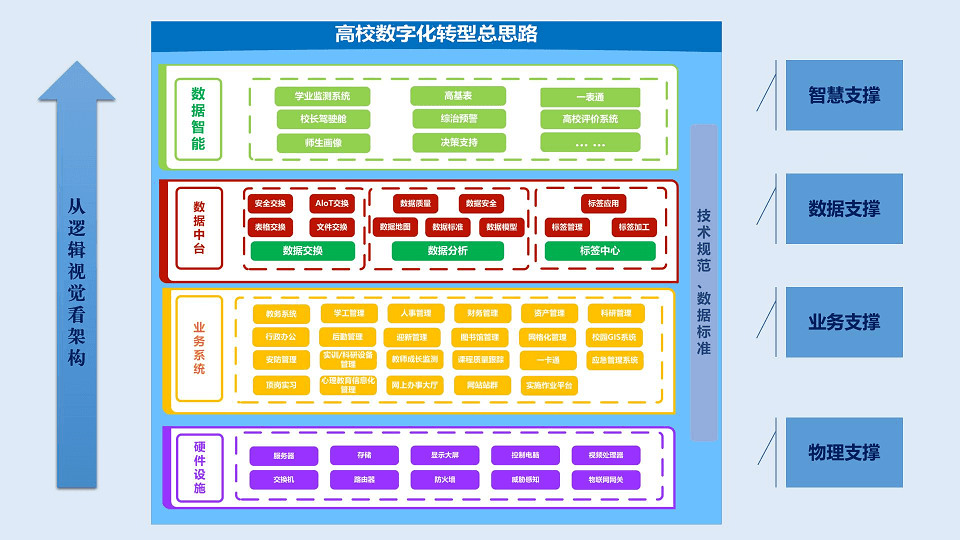
四、获取大会核心PPT全套资料
百度搜索 "百家峰会” ,或点击下方链接获取。
百家峰会,提供全球技术峰会前沿资料,大数据峰会、人工智能峰会、元宇宙峰会、数字孪生峰会、软件开发者大会等各类会议核心PPT课件文件,点击下方链接获取。